做网站建设的公司是什么类型领硕网站seo优化
1. CSS 选择器的优先级是怎么样的?
CSS 选择器的优先级顺序:
内联样式 > ID选择器 > 类选择器 > 标签选择器
优先级的计算:
优先级是由 A、B、C、D 四个值来决定的,具体计算规则如下
- A={如果存在内联样式则为 1,否则为 0}
- B={ID 选择器出现的次数}
- C={类选择器、属性选择器、伪类选择器出现的总次数}
- D={标签选择器、伪元素选择器出现的总次数}
计算示例:
样式一:
/*A=0 不存在内联样式B=0 不存在ID选择器C=1 有一个类选择器D=3 有三个标签选择器最终计算结果:{0,0,1,3}
*/
div ul li .red {...;
}
样式二:
/*A=0 不存在内联样式B=1 有一个ID选择器C=0 不存在类选择器D=0 不存在标签选择器最终计算结果:{0,1,0,0}
*/
#mydiv {...;
}
计算完成后,我们通过从 A 到 D 的顺序进行值的大小比较,权重由 A 到 D 从高到低,只要比较出最大值即可。例如上面的两个样式:
1. 样式一的 A=0,样式二的 A=0 【相等,继续往下比较】
2. 样式一的 B=0 < 样式二的 B=1 【样式二的大,不继续往下比了,即认为样式二的优先级更高】
2. 通过 CSS 的哪些方式可以实现隐藏页面上的元素?
| 方式 | 说明 |
|---|---|
| opacity: 0 | 通过将元素的透明度设置为 0,实现看起来隐藏的效果;但是依然会占用空间并可以进行交互 |
| visibility: hidden | 与透明度为 0 的方案非常类似,会占据空间,但不可以进行交互 |
| overflow: hidden | 只会隐藏元素溢出的部分;占据空间且不可交互 |
| display: none | 可以彻底隐藏元素并从文档流中消失,不占据空间也不能交互,且不影响布局 |
| z-index: -9999 | 通过将元素的层级置于最底层,让其他元素覆盖住它,达到看起来隐藏的效果 |
| transform: scale(0,0) | 通过将元素进行缩放,缩小为 0;依然会占据空间,但不可交互 |
| left: -9999px | 通过将元素定位到屏幕外面,达到看起来看不到的效果 |
3. px、em、rem 之间有什么区别?
考察点: 相对单位, 绝对单位, 以及适配问题
| 单位名称 | 说明 |
|---|---|
| px | 绝对单位。代表像素数量,页面会按照给出的精确像素进行展示 |
| em | 相对单位。默认的基准点为父元素的字体大小,而如果自身定义了字体大小则按自身的来算。所以即使在同一个页面内,1em 可能不是一个固定的值。 |
| rem | 相对单位。可以理解为 root em,即基准点为根元素<html>的字体大小。rem 是 CSS3 中新增单位,Chrome/FireFox/IE9+都支持, 一般用于做移动端适配 |
正常开发 px 使用率较高, 如果要做 rem 适配, 会用到 rem 单位!
rem 布局的原理:
- 使用 rem 为单位
- 动态的设置 html font-size (媒体查询, js 设置, 插件设置都可以)
webpack 有工具, 可以写 px, 自动转 rem https://youzan.github.io/vant/#/zh-CN/advanced-usage
4. 让元素水平居中的方法有哪些?
方法一:使用 margin
通过为元素设置左右的 margin 为 auto,实现让元素居中。
<div class="center">本内容会居中</div>
.center {height: 500px;width: 500px;background-color: pink;margin: 0 auto;
}
方式二: 转成行内块, 给父盒子设置 text-align: center
<div class="father"><div class="center">我是内容盒子</div>
</div>
.father {text-align: center;
}
.center {width: 400px;height: 400px;background-color: pink;display: inline-block;
}
方法三:使用 flex 布局
使用 flex 提供的子元素居中排列功能,对元素进行居中。
<div class="father"><div class="center">我是内容盒子</div>
</div>
.father {display: flex;background-color: skyblue;justify-content: center;align-items: center;
}
.center {width: 400px;height: 400px;background-color: pink;
}
方式四: 使用定位布局
<div class="father"><div class="center">我是内容盒子</div>
</div>
.father {background-color: skyblue;position: relative;height: 500px;
}
.center {width: 400px;height: 400px;background-color: pink;position: absolute;left: 50%;top: 50%;transform: translate(-50%, -50%);
}
【更多方式参考】实现水平居中垂直居中
5. 在 CSS 中有哪些定位方式?
也就是 position 样式的几个属性。
static 正常文档流定位
-
此时设置 top、right、bottom、left 以及 z-index 都无效
-
块级元素遵循从上往下纵向排列,行级元素遵循从左到右排列
relative 相对定位
这个 “相对” 是指相对于正常文档流的位置。
absolute 绝对定位
当前元素相对于 **最近的非 static 定位的祖先元素 **来确定自己的偏移位置。
例如,当前为 absolute 的元素的父元素、祖父元素都为 relative,则当前元素会相对于父元素进行偏移定位。
fixed 固定定位
当前元素相对于屏幕视口 viewport 来确定自己的位置。并且当屏幕滚动时,当前元素的位置也不会发生改变。
sticky 粘性定位
这个定位方式有点像 relative 和 fixed 的结合。当它的父元素在视口区域、并进入 top 值给定的范围内时,当前元素就以 fixed 的方式进行定位,否则就以 relative 的方式进行定位。
<style>* {margin: 0;padding: 0;}.header {width: 100%;height: 100px;background-color: orange;}.nav {width: 100%;height: 200px;background-color: pink;position: sticky;top: 0px;}.main {width: 100%;height: 100px;background-color: skyblue;}
</style><div class="header">我是头部</div>
<div class="nav">我是导航</div>
<div class="container"><div class="main">我是主体部分1</div><div class="main">我是主体部分2</div><div class="main">我是主体部分3</div><div class="main">我是主体部分4</div><div class="main">我是主体部分5</div><div class="main">我是主体部分6</div><div class="main">我是主体部分7</div><div class="main">我是主体部分8</div>
</div>
6. 如何理解 z-index?
可以将它看做三维坐标系中的 z 轴方向上的图层层叠顺序。
元素默认的 z-index 为 0,可通过修改 z-index 来控制设置了 postion 值的元素的图层位置。
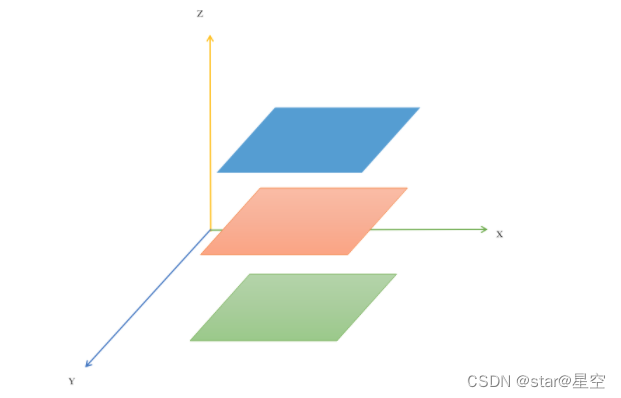
可以将这种关系想象成一摞书本,通过 z-index 可以改变一本书在这摞书中的上下位置。
z-index 的小坑, 如果父辈元素有定位, 且配置了 z-index, 优先按照父辈元素的定位的 z-index 进行比较层级
<style>.father {width: 100%;height: 200px;position: relative;background-color: skyblue;z-index: 1;}.son {position: absolute;width: 100px;height: 100px;background-color: red;left: 0;top: 0;z-index: 999;}.box2 {position: absolute;width: 100px;height: 100px;background-color: blue;left: 0;top: 0;z-index: 100;}
</style><div class="father"><div class="son"></div>
</div><div class="box2"></div>
7. 如何清除浮动 ?
考察: css 基本功
可以有以下几种方式:
-
定高法
-
使用一个空的 div,并设置样式
<div style="clear:both"></div>
-
为父元素添加
overflow: hidden -
定义一个 clearfix 样式类
.clearfix:after {content: ""; /*设置内容为空*/height: 0; /*高度为0*/line-height: 0; /*行高为0*/display: block; /*将文本转为块级元素*/visibility: hidden; /*将元素隐藏*/clear: both; /*清除浮动*/
}.clearfix {zoom: 1; /*为了兼容IE*/
}
说明:当前 flex 已成为主流布局方式,适应性强, 且稳定, 所以浮动使用率目前已逐步降低。
8. 谈谈你对 BFC 的理解?
什么是 BFC:
BFC 的全称是 Block Formatting Context,块级格式化上下文。这是一个用于在盒模型下布局块级盒子的独立渲染区域,
将处于 BFC 区域内和区域外的元素进行互相隔离。
何时会形成 BFC:
满足下列条件之一就可触发 BFC:
- HTML 根元素
- position 值为
absolute或fixed - float 值不为
none - overflow 值不为
visible - display 值为
inline-block、table-cell或table-caption
BFC 的应用场景:
- 场景一:防止两个相邻块级元素的上下 margin 发生重叠 (上下 margin 合并问题)
属于同一 BFC 的, 两个相邻块级子元素的上下 margin 会重叠,如果想让它们不重叠,可通过让这两个相邻块级子元素分属于不同的 BFC。
以下示例代码中的两个盒子的上下外边距会重合(即它们都设置了 10px 的外边距,我们期望它们之间的间距是 20px,但实际效果却只有 10px):
<style>.box1 {width: 200px;height: 100px;background-color: red;margin-bottom: 10px; /* 下外边距为 10px */}.box2 {width: 200px;height: 100px;background-color: green;margin-top: 10px; /* 上外边距为 10px */}
</style><div class="box1"></div>
<div class="box2"></div>

下面我们让其中一个盒子触发 BFC,从而达到间隔 20px 的期望效果:
.box2 {width: 200px;height: 100px;background-color: green;margin-top: 10px;display: inline-block; /* 通过设置 display 为 inline-block 可以触发 BFC */
}

- 场景二:清除浮动
以下示例代码中, 容器元素 box1 的高度会没有高:
<style>.box1 {width: 200px;background-color: red;}.box2 {float: left;background-color: green;}
</style><div class="box1"><div class="box2">Hello,world</div><div class="box2">Hello,world</div><div class="box2">Hello,world</div>
</div>
而通过为 box1 添加 BFC 触发条件,可以让它的高度变回正常状态:
.box1 {width: 200px;background-color: red;overflow: hidden;
}
- 场景三:实现自适应布局, 防止元素被浮动元素覆盖(左边固定, 右边自适应)
以下示例中,box2 会被设置了浮动的 box1 覆盖:
<style>.box1 {float: left;width: 300px;background-color: red;height: 400px;}.box2 {background-color: blue;height: 600px;}
</style><div class="box1"></div>
<div class="box2"></div>

要避免这种覆盖行为,可以让 box2 触发 BFC, 实现布局效果, 左边固定右边自适应:
.box2 {background-color: blue;height: 600px;overflow: hidden; /* 将 overflow 设置为非 visible 值可触发 BFC */
}

参考文章:深入理解 BFC
9. 什么是 CSS Sprites 以及它的好处?
考察: 性能优化的方案
CSS Sprites,俗称雪碧图、精灵图。这是一种 CSS 图片合并技术,就是将 CSS 中原先引用的一些较小的图片,合并成一张稍大的图片后再引用的技术方案。它可以减少请求多张小图片带来的网络消耗(因为发起的 HTTP 请求数变少了),并实现提前加载资源的效果。
操作方式:
可以手工使用图片编辑软件(如 Photoshop),将多张小图片合并编辑变成一张大图片,并针对这张大图片,编写 CSS 样式来引用这张大图片中对应位置的小图片(涉及到的样式:background-image、background-position、background-size)。然后在 HTML 元素中使用这些样式即可。
https://img.alicdn.com/tfs/TB1eiXTXlTH8KJjy0FiXXcRsXXa-24-595.png
缺点:
- CSS Sprites 中任意一张小图的改动,都需要重新生成大图;并且用户端需要重新下载整张大图,这就降低了浏览器缓存的优势
- 随着 HTTP2 的逐渐普及,HTTP2 的多路复用机制可以解决请求多个小图片所创建多个 HTTP 请求的消耗,让 CSS Sprites 存在的价值降低了
- 图片如果放大, 是会失真
目前其他主流的处理图片的方案: iconfont 字体图标, svg 矢量图…
10. 你对媒体查询的理解是什么样的?
考察点: 响应式适配, 根据不同的屏幕尺寸, 显示不同的效果 (设置盒子的样式)
媒体查询是自 CSS3 开始加入的一个功能。它可以进行响应式适配展示。
媒体查询由两部分组成:
- 一个可选的媒体类型(如 screen、print 等)
- 零个或多个媒体功能限定表达式(如 max-width: 500px、orientation: landscape 等)
这两部分最终都会被解析为 true 或 false 值,然后整个媒体查询值为 true,则和该媒体查询关联的样式就生效,否则就不生效。
使用示例:
/* 在css样式表的定义中直接使用媒体查询 */
.container {width: 600px;height: 200px;background-color: pink;margin: 0 auto;
}
@media screen and (max-width: 767px) {.container {width: 100%;}
}
@media screen and (min-width: 768px) and (max-width: 991px) {.container {width: 750px;}
}
@media screen and (min-width: 992px) and (max-width: 1199px) {.container {width: 980px;}
}
@media screen and (min-width: 1200px) {.container {width: 1170px;}
}
@media screen and (width: 1200px) {.container {background-color: skyblue;}
}
参考文章:深入理解 CSS 媒体查询
11. 你对盒子模型的理解是什么样的?
浏览器的渲染引擎在对网页文档进行布局时,会按照 “CSS 基础盒模型” (CSS Basic Box Model)标准,将文档中的所有元素都表示为一个个矩形的盒子,再用 CSS 去决定这些盒子的大小尺寸、显示位置、以及其他属性(如颜色、背景、边框等)。
下图就是盒模型示意图,它由几部分组成:
- 内容(content)
- 内边距(padding)
- 边框(border)
- 外边距(margin)

12. 标准盒模型和怪异盒模型有哪些区别?
两者的区别主要体现在元素尺寸的表示上。
盒模型的指定:
在 CSS3 中,我们可以通过设置 box-sizing 的值来决定具体使用何种盒模型:
- content-box 标准盒模型
- border-box 怪异盒模型
标准盒模型:
box-sizing: content-box; (默认值)
在标准盒模型下,元素的宽(width)和高(height)值即为盒模型中内容(content)的实际宽高值。
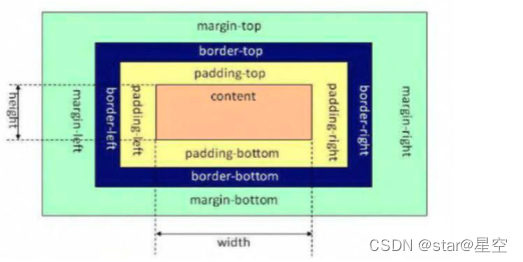
因此,计算一个元素宽度的公式如下(不考虑 margin, margin 是外边距, 如果是计算占用页面的空间, 就要带上 margin):
盒子宽度 =
border-left+padding-left+width+padding-right+border-right占据页面宽度 =
margin-left+border-left+padding-left+width+padding-right+border-right+margin-right
怪异盒模型:
box-sizing: border-box; (目前主流常用值)
在怪异盒模型下,元素的 width 和 height 值却不是 content 的实际宽高,而是去除 margin 后剩下的元素占用区域的宽高,即:
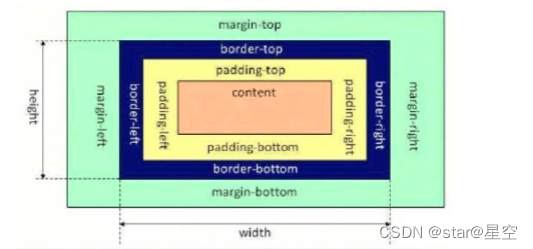
因此,计算一个元素占用了页面总宽度的公式如下:
盒子宽度 =
width盒子占据页面宽度 =
margin-left+width+margin-right
参考文章:深入理解盒模型
13. 说说伪类和伪元素的区别?
什么是伪类?
伪类(pseudo-class)是以冒号:为前缀,可被添加到⼀个选择器的末尾的关键字。
它用于让样式在元素的特定状态下才被应用到实际的元素上。比如::checked、:hover、:disabled、 :first-child等。
:hover
:nth-child(1)
:nth-child(2)
:checked
注意: 伪类, 虽然是写法比较特殊, css 选择器的权重, 和类一致的
什么是伪元素?
:before / :after
伪元素⽤于创建⼀些并不在 DOM 树中的元素,并为其添加样式。伪元素的语法和伪类类似,可以一个冒号或两个冒号为前缀。
⽐如,可以通过 :before 、:after 来在⼀个元素前、后增加⼀些额外的⽂本并为它们添加样式;
并且,虽然⽤户可以看到这些⽂本,但其实它们并不在 DOM 树中。(坑: 伪元素是无法注册事件的, 所以不要通过 js 控制伪元素)
两者的区别
虽然它们在语法上是一致的,但是它们的功能区别还是非常明显的。
- 伪类是用来匹配元素的特殊状态的
- 伪元素是用来匹配元素的隶属元素的,这些隶属元素可以在界面中展示,但在 DOM 中不体现
参考文章:伪类与伪元素
14. 谈谈你对 flex 的理解?
在真实的应用场景中,通常会遇到各种各样不同尺⼨和分辨率的设备,为了能在所有这些设备上正常的布局我们的应用界面,就需要响应式的界⾯设计方式来满⾜这种复杂的布局需求。
flex 弹性盒模型的优势在于开发⼈员只需要声明布局应该具有的⾏为,⽽不需要给出具体的实现⽅式,浏览器负责完成实际布局,当布局涉及到不定宽度,分布对⻬的场景时,就要优先考虑弹性盒布局。
你能联想到的 flex 语法有哪些呢?
flex-direction: 调整主轴方向
row:主轴方向为水平向右
column:主轴方向为竖直向下
row-reverse:主轴方向为水平向左
column-reverse:主轴方向是竖直向上。
justify-content 主要用来设置主轴方向的对齐方式
flex-start: 弹性盒子元素将向起始位置对齐
flex-end: 弹性盒子元素将向结束位置对齐。
center: 弹性盒子元素将向行中间位置对齐
space-around: 弹性盒子元素会平均地分布在行里
space-between:第一个贴左边,最后一个贴右边,其他盒子均分,保证每个盒子之间的空隙是相等的。
align-items 用于调整侧轴的对齐方式
flex-start: 元素在侧轴的起始位置对齐。
flex-end: 元素在侧轴的结束位置对齐。
center: 元素在侧轴上居中对齐。
stretch: 元素的高度会被拉伸到最大(不给高度时, 才拉伸)。
flex-wrap 属性控制 flex 容器是单行或者多行,默认不换行
nowrap: 不换行(默认),如果宽度溢出,会压缩子盒子的宽度。
wrap: 当宽度不够的时候,会换行。
align-content 用来设置多行的 flex 容器的排列方式
flex-start: 各行向侧轴的起始位置堆叠。
flex-end: 各行向弹性盒容器的结束位置堆叠。
center: 各行向弹性盒容器的中间位置堆叠。
space-around: 各行在侧轴中平均分布。
space-between: 第一行贴上边,最后一个行贴下边,其他行在弹性盒容器中平均分布。
stretch:拉伸,不设置高度的情况下。
可参考 [flex 布局教程](