wordpress网站熊掌粉丝关注旅游网站开发本科论文
这个文章是怎么来的呢?现在不是低代码开发平台启蒙阶段嘛?笔者也有幸在工作中进行了尝试,目前也已经在实际工作中结合Python进行了使用,当然,是可以提高IT的工作效率的。
需求是这样的,想从公司的EBS平台报表系统里面抓取数据进行二次分析处理,翻遍了整个EBS BI,发现目前可用的推送接口也就是通过邮件定时推送数据文件,之前有做过用PowerAutomation抓取邮件附件,并保存在Onedrive上面,然后通过Onedrive的同步功能,同步到指定的共享文件夹上,给Python进行二次处理分析。过程流程不是很复杂,大致步骤如下:

在这个流程中有几个体验感受:
1. 微软实现了全闭环平台。
2. 目前运行感受来看,稳定性还是不错的。
3. 数据邮件会保存在收件者的邮箱中。
当然,对于低频次的推送,每天收个一两封推送邮件还好,如果是10分钟推送一次,估计收件人邮箱要爆炸了。这就引出了另外一个话题,如何自动的删除这些邮件?
好在笔者经过研究,结合了多个Template,实现了自动转存并删除邮件的效果,目前体验效果不错。工作流如下:
在这个流程中有几个体验感受:
1. 微软实现了全闭环平台。
2. 目前运行感受来看,稳定性还是不错的。
当然,对于低频次的推送,每天收个一两封推送邮件还好,如果是10分钟推送一次,估计收件人邮箱要爆炸了。这就引出了另外一个话题,如何自动的删除这些邮件?
好在笔者经过研究,结合了多个Template,实现了自动转存并删除邮件的效果,目前体验效果不错。工作流如下:
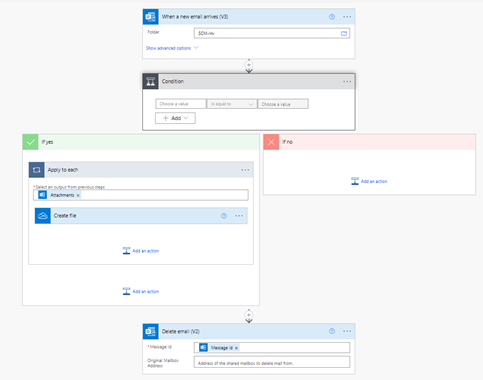
这是一个完全的拖拽式流程设计,对于一些重复的开发工作,完全可以在这个平台上实现,前提需要数据源来自微软平台,如Onedrive,sharepoint, O365, outlook.com等。
有了这个工具,感觉不需要重复的造轮子了,为什么不把Python精力放在更重要的地方呢,比如OpenCV, Tensorflow?
需求推动技术往前发展,应该需要这样。通过这个示例,抛砖引玉,需要能够有更多的低代码应用提供工作效率