有建站模板如何建设网站网络热词排行榜
如果您想将设备连接到互联网,您可能想知道要使用的正确电缆。跳线和交叉电缆都是类型的以太网电缆,可帮助连接计算机、调制解调器、路由器和交换机等设备。那么,跳线和交叉电缆有什么区别呢?让我们讨论这两种类型的电缆,并探讨它们的不同之处。
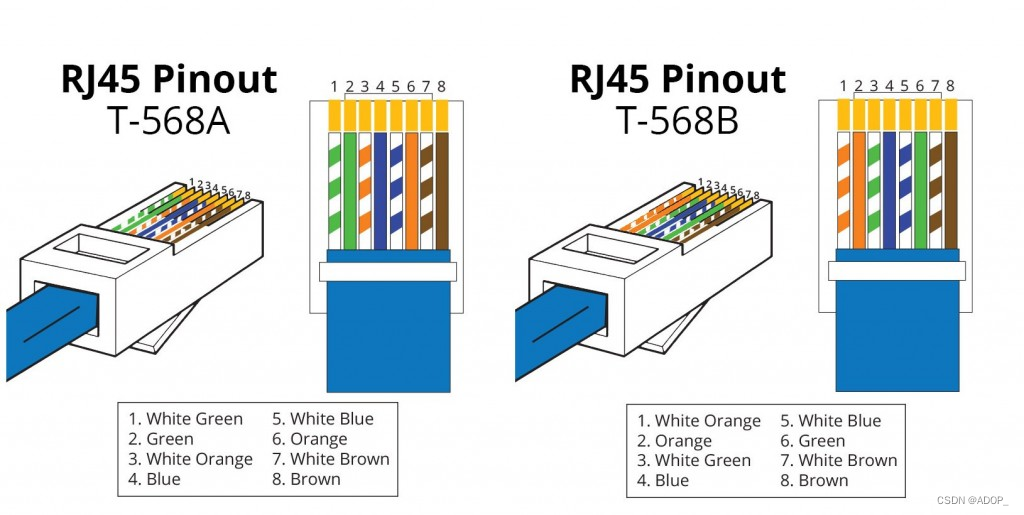
T-568A与T-568B
T-568A与T-568B是两种以太网线缆接线标准,广泛应用于RJ45连接器和网络布线中。这两种标准定义了8根导线在插头中的排列顺序,以确保网络通信的正确性和效率。
T-568A标准的线序从左到右依次是绿白、绿、橙白、蓝、蓝白、橙、棕白、棕。而T-568B标准的线序则是橙白、橙、绿白、蓝、蓝白、绿、棕白、棕。这两种标准在功能上没有区别,但通常在同一网络系统中应保持一致,以避免通信错误。
在实际应用中,T-568B标准更为常见,特别是在美国。然而,如果网络设备的手册或规范中指定了T-568A标准,则应遵循相应的指导。在跨接线(Crossover Cable)的制作中,一端使用T-568A标准,另一端使用T-568B标准,这样可以直接连接两台计算机进行通信,而无需通过交换机或路由器。
在布线时,正确的线序对于网络的稳定性和传输速度至关重要。不正确的线序可能导致网络连接不稳定,数据传输速率下降,甚至完全无法通信。因此,无论是在家庭网络还是商业网络中,遵循正确的接线标准都是确保网络性能的基础。
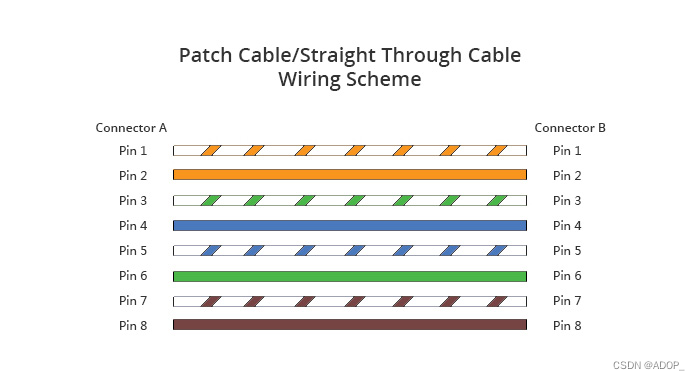
什么是跳线?
跳线,也称为跨接线或跳接线,是一种用于电子设备或通信网络中的短电线,它通过连接两个电路点来传输信号或电流。在网络技术中,跳线通常指的是一种特殊的以太网电缆,用于直接连接两台网络设备,如交换机、路由器或计算机,而无需中继设备。
在网络布线中,跳线可以用于连接不同类型的设备或相同类型的设备。例如,当两台计算机需要直接通信而不通过交换机时,可以使用一根跳线,其中一端采用T-568A标准,另一端采用T-568B标准。这种跳线也被称为交叉线,因为它在两端交换了某些导线的位置,从而使发送和接收信号的线对调换,实现直接通信。
在数据中心或服务器房间,跳线也用于管理和组织网络连接。它们通常较短,便于在机架内部或跨越相邻设备进行连接,同时减少杂乱无章的线缆和提高空气流通。跳线的颜色和长度多种多样,以满足不同的布线需求和标识不同的服务或应用。
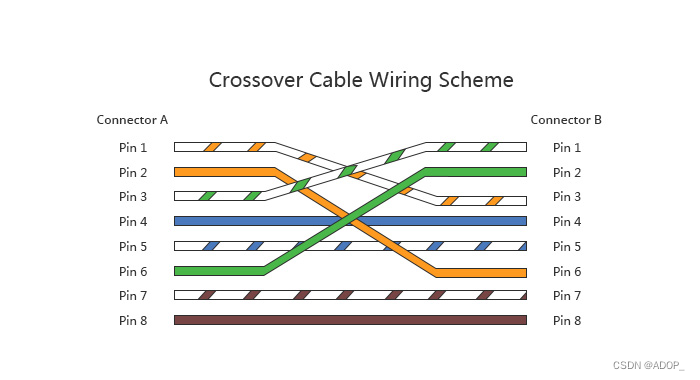
什么是交叉电缆?
交叉电缆,也称为交叉线或交换线,是一种特殊类型的以太网电缆,用于直接连接两台同类设备,如两台计算机或两台交换机,而不需要中继设备如路由器或集线器。它的特点是在一端的RJ45插头中交换了某些导线的位置,使得一端的发送线与另一端的接收线相对应,从而实现设备间的直接通信。
在制作交叉电缆时,通常一端会遵循T-568A标准的线序,另一端则遵循T-568B标准。这种线序的交换允许发送和接收信号的线对调换,使得两台设备能够直接进行数据传输。例如,T-568A标准的绿白线(发送+)和绿线(发送-)会与T-568B标准的橙白线(接收+)和橙线(接收-)相对应,反之亦然。
交叉电缆在家庭网络或小型办公室网络中尤为有用,当没有交换机或路由器可用时,可以通过交叉电缆直接连接两台计算机,实现文件共享或游戏联机。然而,随着现代网络设备的自适应性增强,许多现代交换机和路由器都具备自动交叉功能(Auto-MDIX),能够自动检测并配置通信模式,因此交叉电缆的需求已经大大减少。
跳线与交叉电缆:有什么区别?
从上面可以清楚地看出,跳线的两端具有相同的电线排列,而交叉电缆的两端具有不同的电线。因此,它们在以太网中有不同的应用。跳线用于将设备连接到网络,而交叉电缆用于连接两个设备。
直通(跳线)用于:
-
将路由器连接到集线器
-
将计算机连接到交换机
-
将 LAN 端口连接到交换机或计算机
使用交叉电缆:
-
将计算机连接到计算机
-
将交换机连接到交换机
-
将路由器连接到路由器
-
将集线器连接到集线器
跳线与交叉电缆:何时使用
简而言之,交叉电缆将两个相同类型的设备连接在一起进行通信,例如PC到PC或交换机到交换机。跳线连接两个不同的设备,如 PC 和交换机。以下方案将介绍不同的应用程序。
场景 1:PC 到 PC
如果我们有两台计算机直接相互连接。两台 PC 都尝试在 TX 线上传输,它们的信号会发生碰撞。此外,RX线上不会发送任何内容。因此,两台计算机都无法接收任何内容。此时,需要交叉电缆在两台 PC 之间建立连接。由于这种电缆是交叉的,因此可以从PC 2的RX线上接收到来自PC 1的TX线的信号。这就是为什么交叉电缆经常用于连接两个相同的设备的原因。

场景二:PC切换到PC
如果在两台计算机之间混合使用交换机,会发生什么情况?事实上,交换机被设计为在两台计算机之间进行通信,这两台计算机具有固有的电线交叉。因此,我们不需要电缆为我们穿越。PC 1 在其 TX 线上发送的内容由其 RX 线上的交换机接收,然后在其 TX 线上传输,最后由另一台 PC 的 RX 线接收。反之亦然。因此,当交换机连接到 PC 时,只需使用 Cat5e 或Cat6跳线 等跳线即可。

场景三:PC切换到切换到PC
如果我们有两个开关,会发生什么?两个开关分别穿过导线一次,因此在开关之间出现另一对交叉。如上所述,两个相同的设备需要交叉电缆才能进行连接。从上图中,我们可以看到:
(1) 当 PC 1 连接到交换机 1 时,我们需要一根跳线。
(2) 当交换机 1 连接到交换机 2 时,我们需要交叉电缆。
(3) 当交换机 2 连接到 PC 2 时,我们需要一根跳线。

总结
综上所述,跳线和交叉电缆可能看起来很相似,但它们在电缆配置和与特定设备的兼容性方面存在显着差异。如果我们能够轻松识别它们之间的区别,我们就可以为网络设置选择最合适的电缆,从而确保高效稳定的连接。
ADOP(前沿光学科技有限公司)提供的跳线是一种高性能的光纤通信设备,用于实现光路的活动连接。这些跳线广泛应用于光纤通信系统、光纤接入网、光纤数据传输以及局域网等领域。ADOP的跳线产品线包括多种类型的光纤跳线,以满足不同的网络需求和应用场景。
光纤跳线的主要分类包括单模光纤和多模光纤:
- 单模光纤跳线(Single-mode Fiber)通常用黄色表示,其接头和保护套为蓝色,适用于长距离传输。
- 多模光纤跳线(Multi-mode Fiber)一般用橙色或水蓝色表示,接头和保护套用米色或黑色,适合短距离传输。
ADOP还提供了不同接口类型的光纤跳线,包括但不限于:
- FC型光纤跳线:外部加强方式采用金属套,紧固方式为螺丝扣,常用于配线架上。
- SC型光纤跳线:连接GBIC光模块的连接器,外壳呈矩形,紧固方式是插拔销闩式,常用于路由器和交换机。
- ST型光纤跳线:常用于光纤配线架,外壳呈圆形,紧固方式为螺丝扣。
- LC型光纤跳线:连接SFP模块的连接器,采用操作方便的模块化插孔,常用于路由器。
ADOP的跳线还包括高性能的800G MPO/MTP单模光纤跳线,这种跳线采用了MPO/MTP接口,能够在单模光纤上实现高达800Gbps的数据传输速率。这些跳线的设计旨在满足数据中心和大型网络环境中对于超高速数据传输的需求。
使用ADOP光纤跳线时,需要注意以下事项:
- 确保光纤跳线两端的光模块的收发波长一致。
- 避免过度弯曲和绕环,以减少光在传输过程中的衰减。
- 使用保护套保护光纤接头,防止灰尘和油污损害光纤。
- 光纤接头被弄脏时,可以用棉签蘸酒精清洁,以保持通信质量。
总之,ADOP的光纤跳线是现代通信和网络系统中的关键组件,确保了高效、可靠的光信号传输。

前沿光学(Advanced Optical Networking, ADOP),作为一家在AI光交换设备和配件领域内先进的供应商,我们专注于利用InfiniBand和RoCE(RDMA over Converged Ethernet)架构,为全球客户提供成熟、可靠、高效的光互联产品和解决方案。我们的使命是通过创新的技术,加速数据中心的性能,支持高性能计算(HPC)、人工智能(AI)、机器学习(ML)和大数据分析等先进应用。
如果您需要更详细的信息,您可以访问ADOP官网。
电话:+86-13422862448
电话:0755-2306 8851
ADOP - 前沿光学科技有限公司
前沿驱动创新,光学创造未来,ADOP与您精彩前行!🚀