桂城网站建设丹灶网站设计
先看效果:
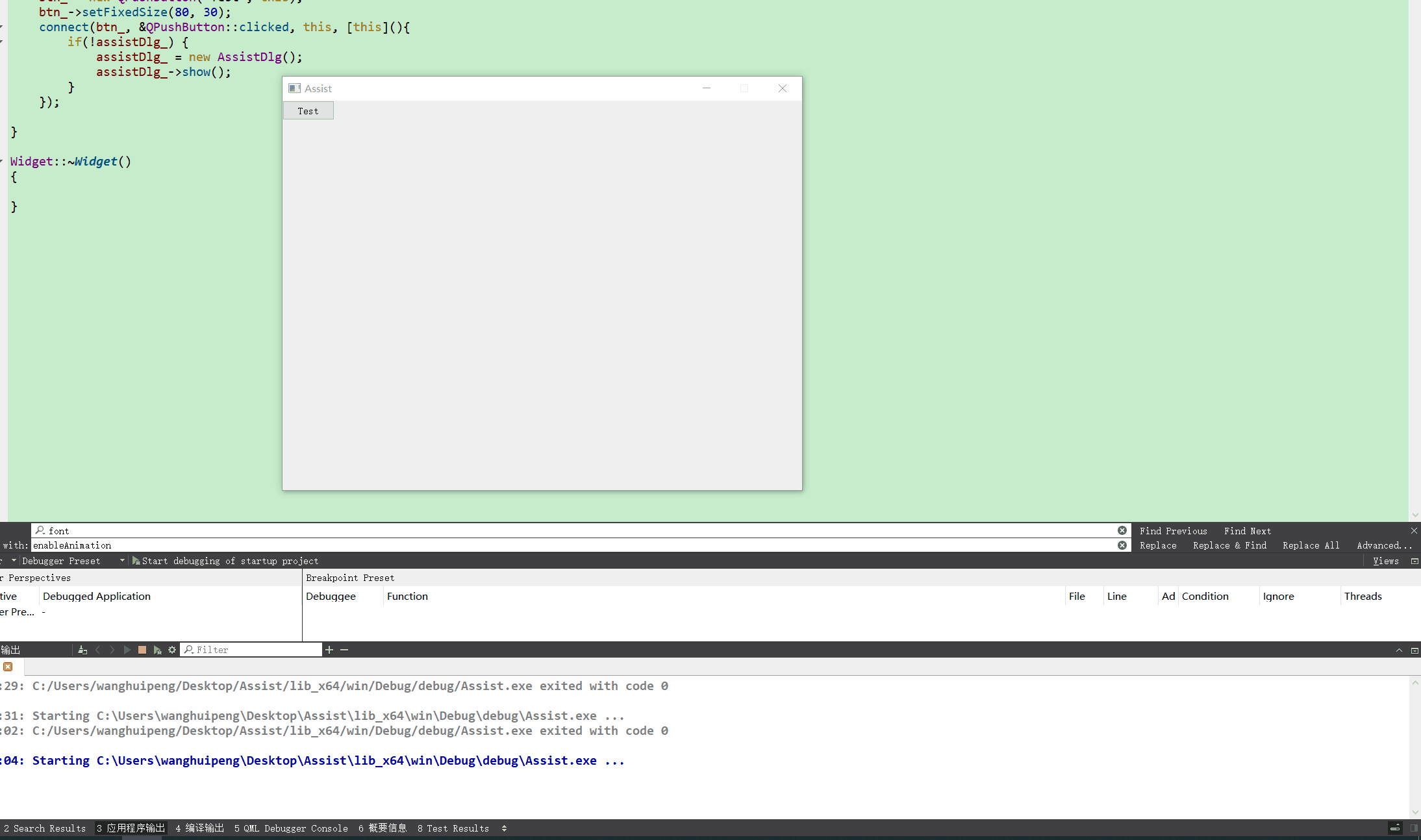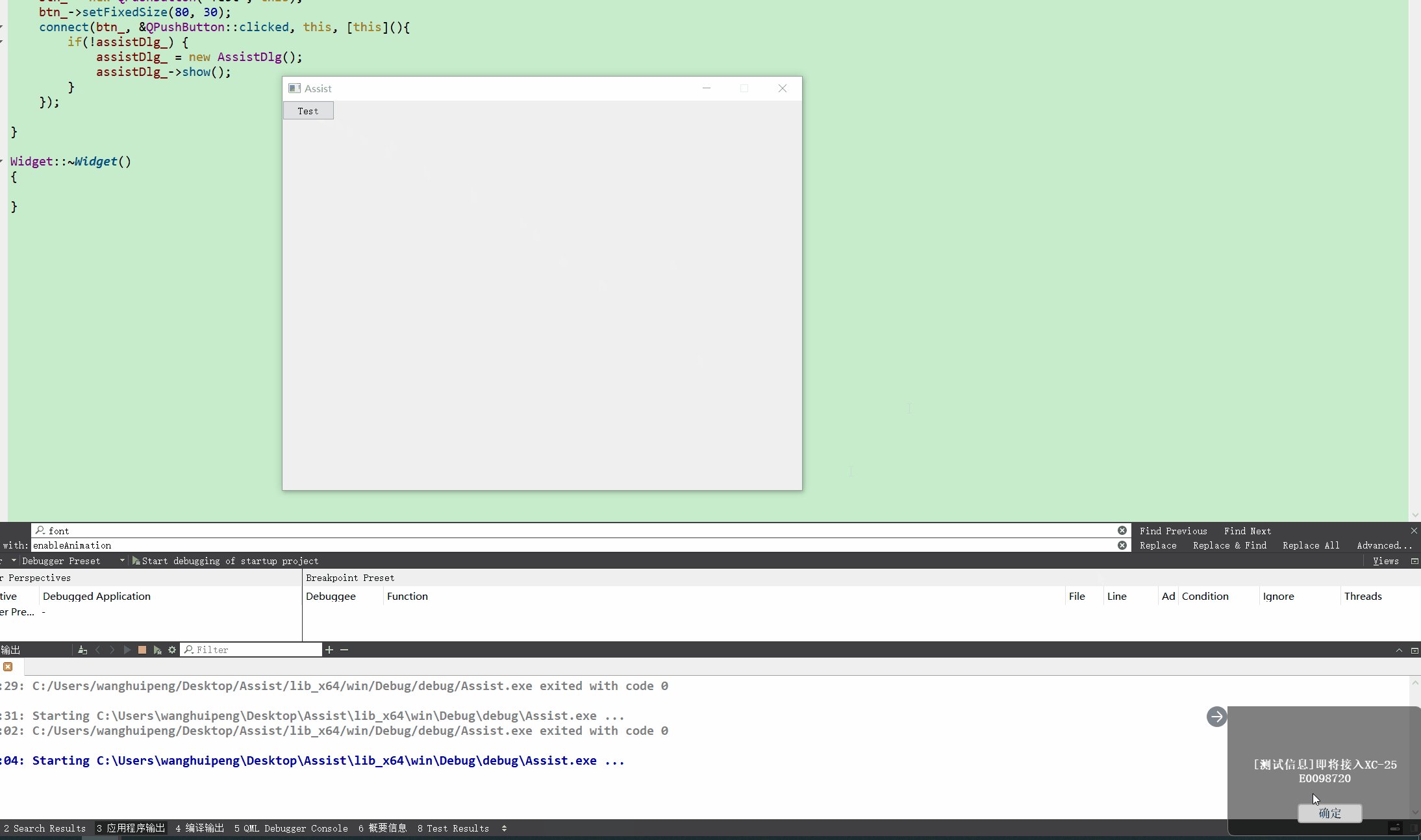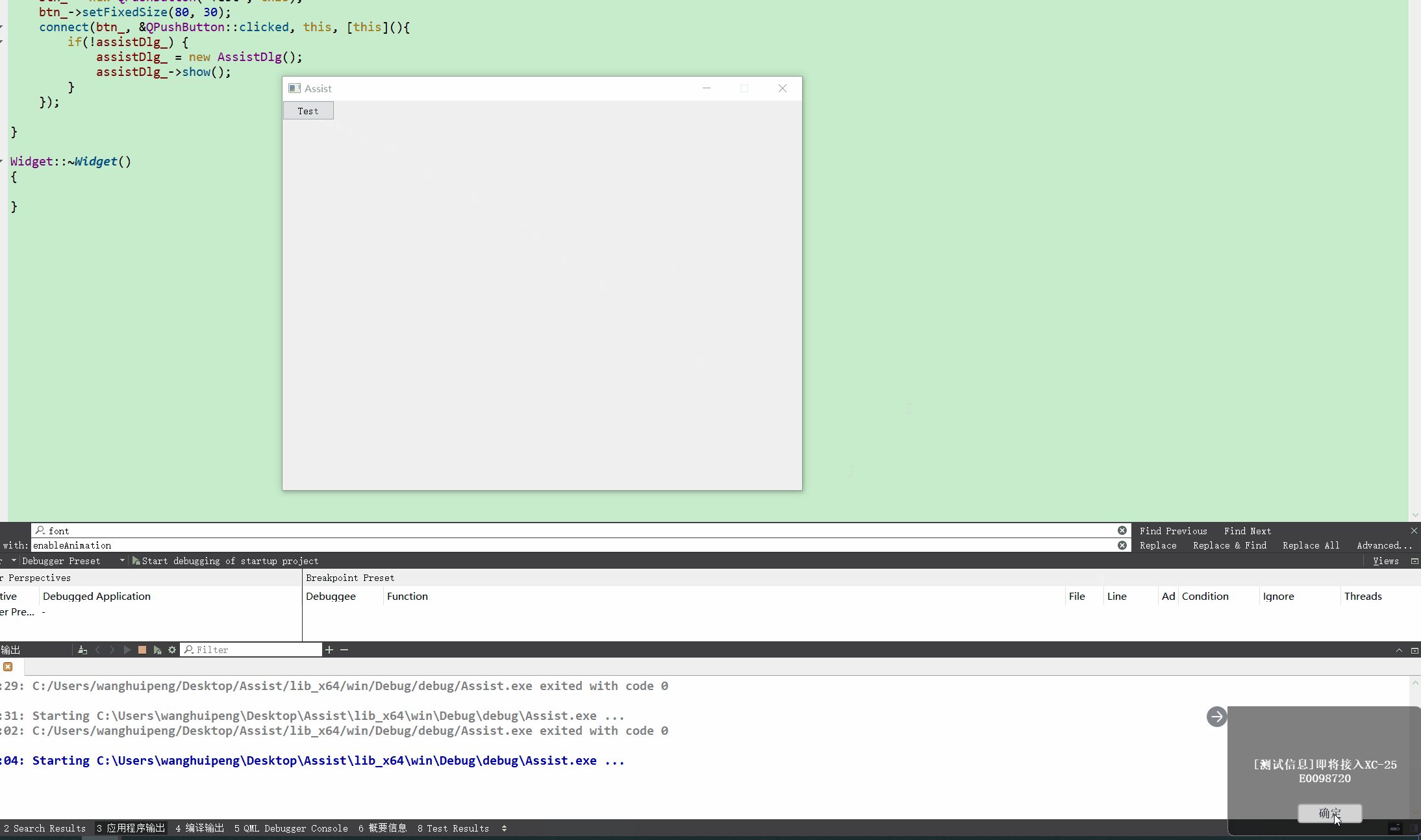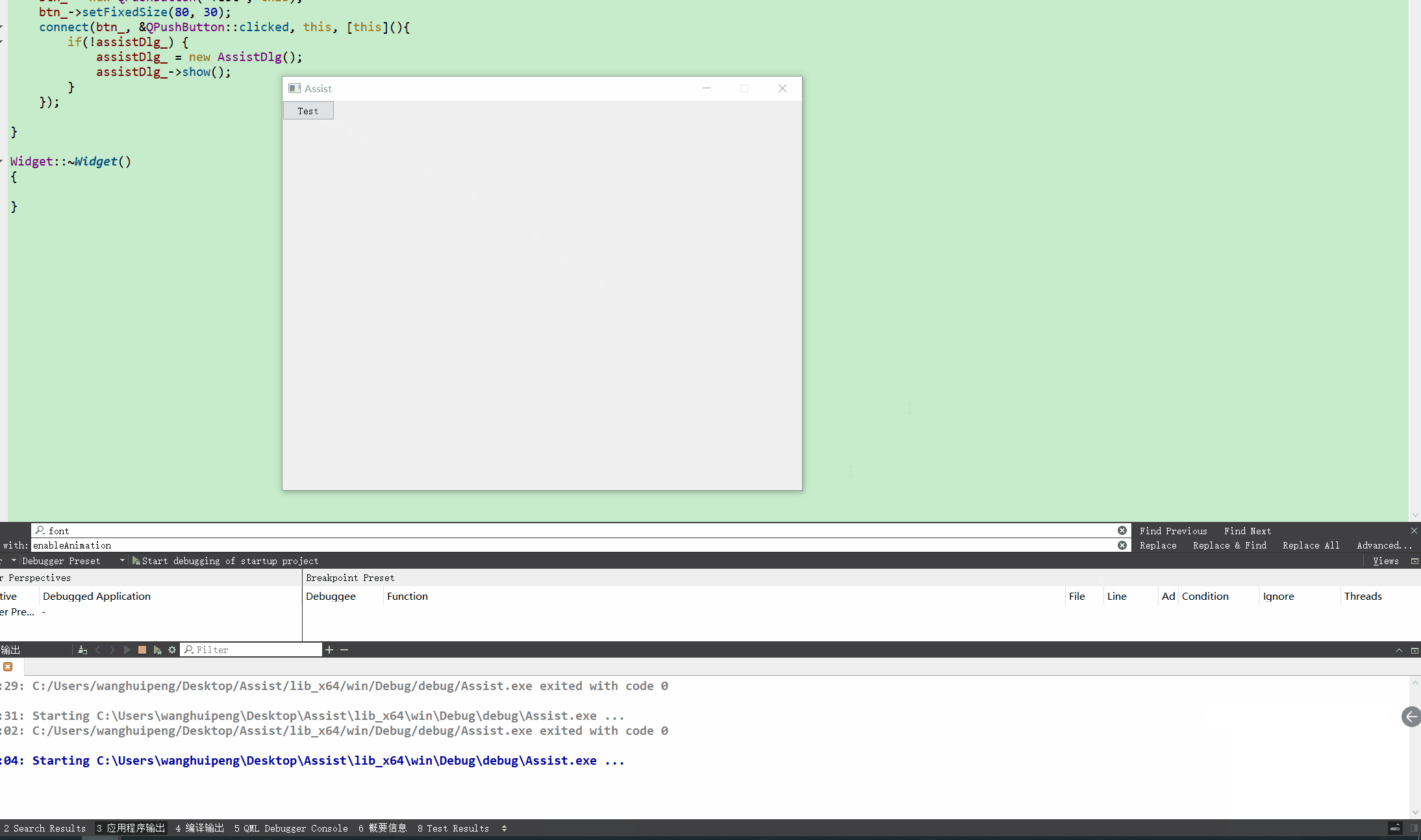
在进行多进程开发时,可能会遇到需要进行全局弹窗的需求。
因为平时会使用ToDesk进行远程桌面控制,在电脑被控时,ToDesk会在右下角进行一个顶层窗口的提示,效果如下:
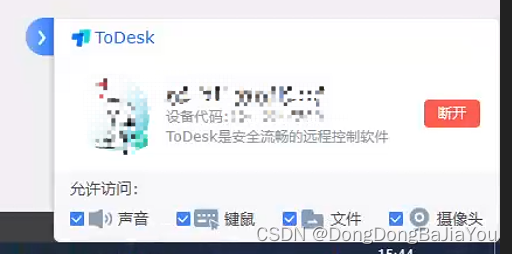
其实要实现顶层窗口,最关键的是设置窗口属性:
setWindowFlags(Qt::FramelessWindowHint | Qt::WindowStaysOnTopHint);同时一般也不太需要Windows状态栏的图标,我们可以这样,加一个Qt::Tool上去:
setWindowFlags(Qt::FramelessWindowHint | Qt::WindowStaysOnTopHint | Qt::Tool);动画效果的使用,会使程序的呈现更加奈斯:
// 初始化
{moveAnimation_ = new QPropertyAnimation(this,"pos",this);QScreen *primaryScreen = QGuiApplication::primaryScreen();if(primaryScreen==nullptr) { return; }geometry=primaryScreen->availableGeometry();this->move(geometry.width()-300-pix_right_.width(),geometry.height()-200);setFixedSize(300+pix_right_.width(), 200);
}// 调用
{QString imageName = is_expanded_ ? "right" : "left";QPoint showPoint = QPoint(geometry.width()-300-pix_right_.width(),geometry.height()-200);QPoint hidePoint = QPoint(geometry.width()-pix_right_.width(),geometry.height()-200);if(is_expanded_) {startAnimation(showPoint, hidePoint);btn_->setMask(pix_right_.mask());} else {startAnimation(hidePoint, showPoint);btn_->setMask(pix_left_.mask());}
}// target目标点,oldpos起始点
void AssistDlg::startAnimation(QPoint target, QPoint oldpos)
{moveAnimation_->setDuration(300);moveAnimation_->setStartValue(oldpos);moveAnimation_->setEndValue(target);moveAnimation_->setEasingCurve(QEasingCurve::OutCubic);moveAnimation_->start();
}不规则按钮的主要代码如下:
btn_ = new QPushButton(this);btn_->setFixedSize(pix_right_.size());btn_->setMask(pix_right_.mask());btn_->setStyleSheet("background-image: url(:/images/right.png)");btn_->setStyleSheet("QPushButton{""border-image:url(:/images/right.png)}");