做网站主流语言黑马程序员广州校区
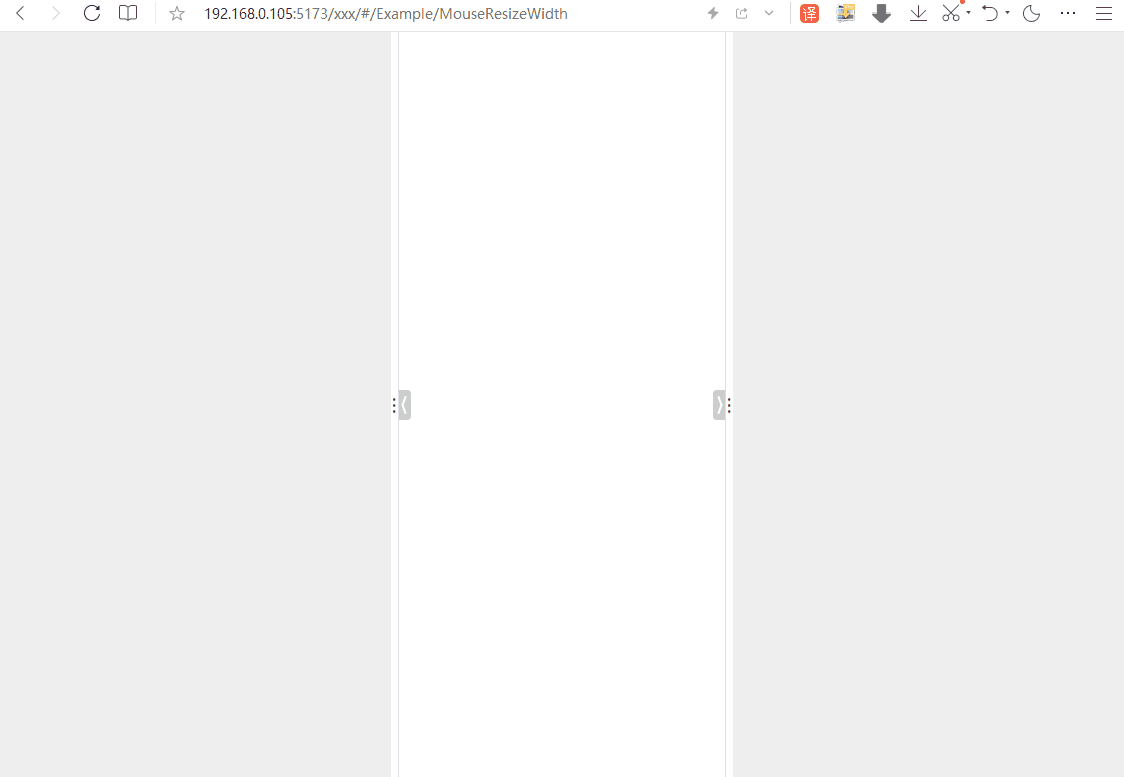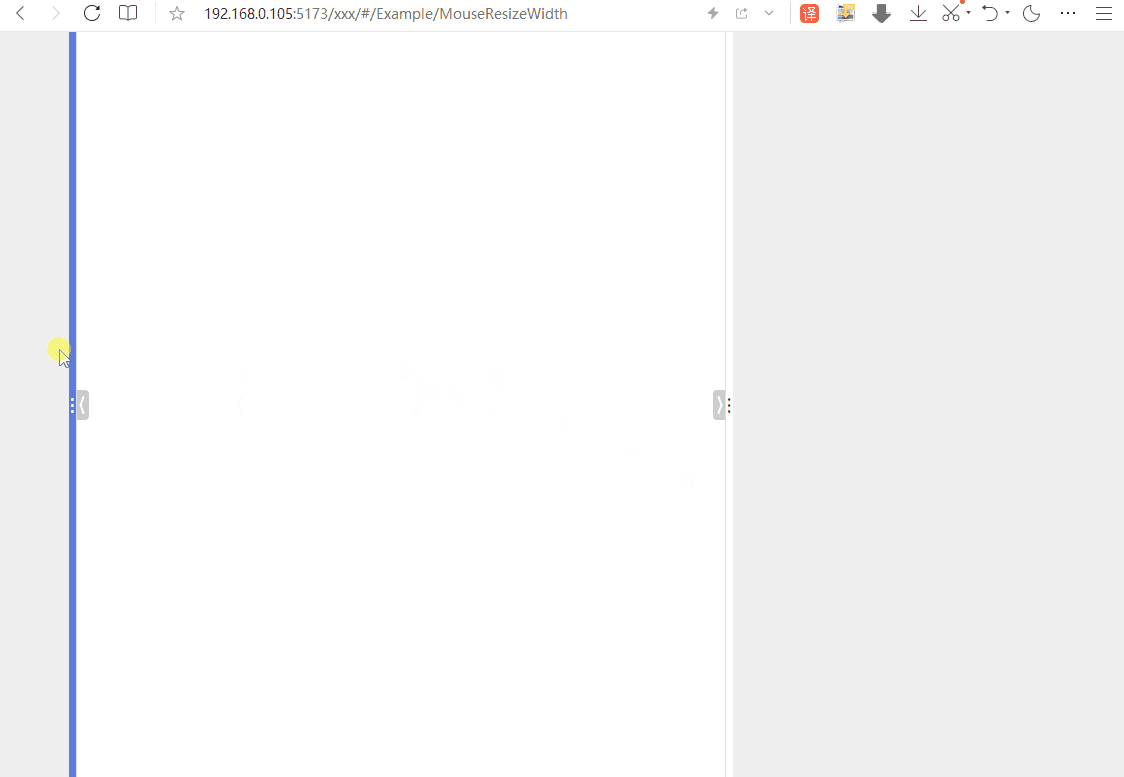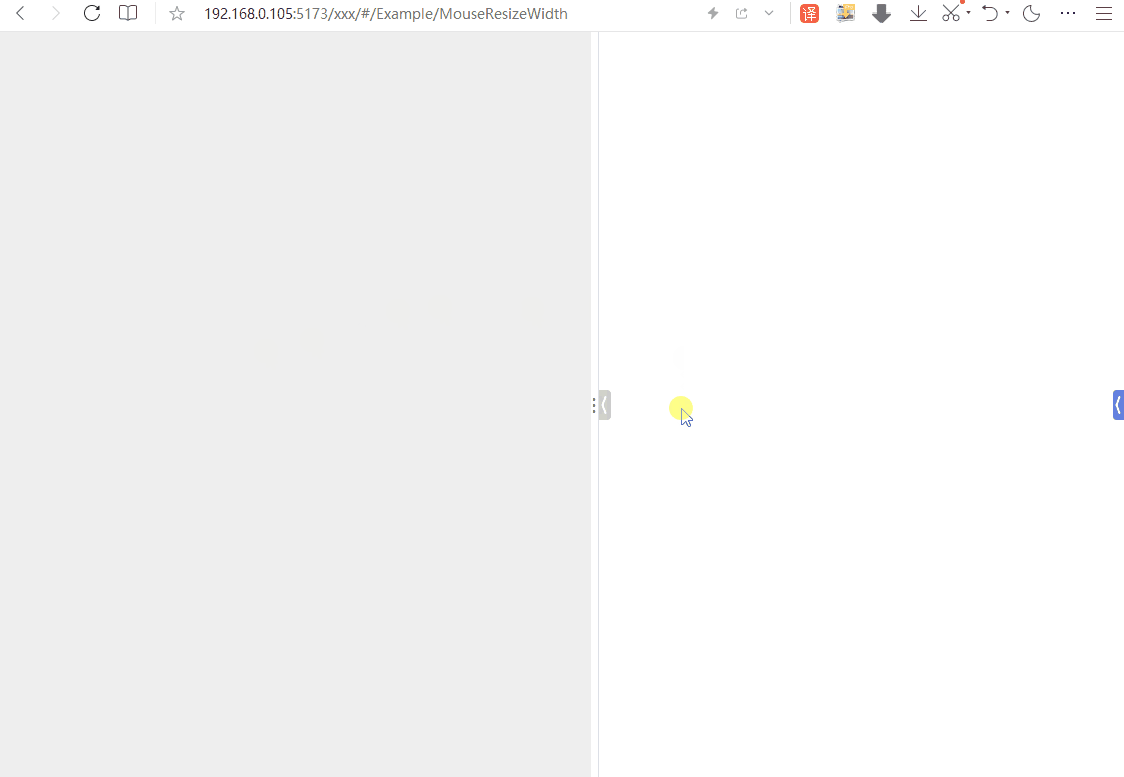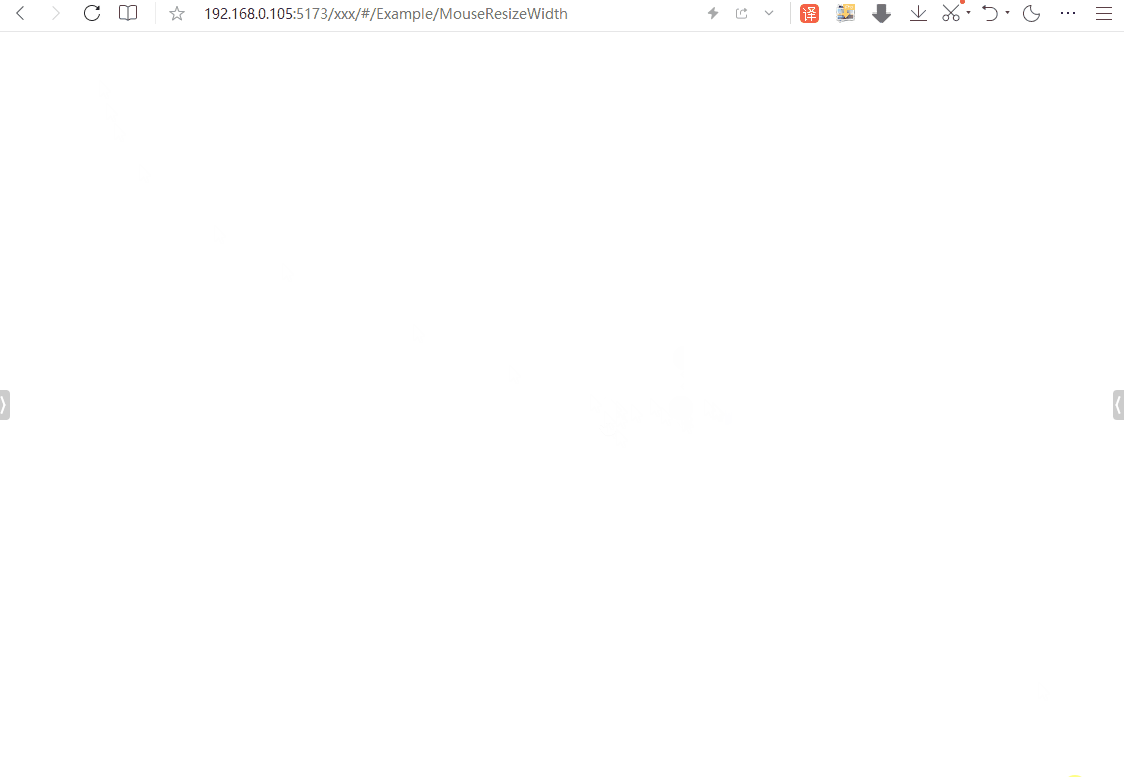
其原理主要是利用JavaScript中的鼠标事件来控制CSS样式。大致就是监听某个DOM元素的鼠标按下事件,以及按下之后的移动事件和松开事件。在鼠标按下且移动过程中,可实时获得鼠标的X轴坐标的值,通过简单计算,可计算出目标元素的宽度,然后再用CSS赋值就实现该效果了。
一、示例代码
<template><div class="index"><div class="index-left" ref="indexLeftRef"><div class="index-left-box"></div><div class="left-resize-bar">⋮</div></div><div class="index-middle" ref="indexRightRef"><div class="index-middle-box"><div class="left-view-more" @click="handleViewMoreLeftClick"><div class="left-view-more-false" v-if="!isExpandLeft" /><div class="left-view-more-true" v-else /></div><div class="index-middle-box_main"></div><div class="right-view-more" @click="handleViewMoreRightClick"><div class="right-view-more-false" v-if="!isExpandRight" /><div class="right-view-more-true" v-else /></div></div></div><div class="index-right" ref="indexRightRef"><div class="right-resize-bar">⋮</div><div class="index-right-box"></div></div></div>
</template><script setup>
import { onMounted, ref, getCurrentInstance } from 'vue'// 代理对象
const { proxy } = getCurrentInstance()// 左侧是否收起或展开
const isExpandLeft = ref(false)/*** 左侧点击收起或展开事件句柄方法*/
const handleViewMoreLeftClick = async () => {const indexLeftRef = await proxy.$refs.indexLeftRefisExpandLeft.value = !isExpandLeft.valueif (isExpandLeft.value) {indexLeftRef.style.width = '0'indexLeftRef.style.borderRight = '0px solid #dcdfe6'} else {indexLeftRef.style.width = '400px'indexLeftRef.style.borderRight = '1px solid #dcdfe6'}
}// 右侧是否收起或展开
const isExpandRight = ref(false)/*** 右侧点击收起或展开事件句柄方法*/
const handleViewMoreRightClick = async () => {const indexRightRef = await proxy.$refs.indexRightRefisExpandRight.value = !isExpandRight.valueif (isExpandRight.value) {indexRightRef.style.width = '0'indexRightRef.style.borderRight = '0px solid #dcdfe6'} else {indexRightRef.style.width = '400px'indexRightRef.style.borderRight = '1px solid #dcdfe6'}
}/*** 左侧拖动事件句柄方法*/
const handleDragLeftResizeBar = () => {var leftResizeBar = document.getElementsByClassName("left-resize-bar")[0]var wholeArea = document.getElementsByClassName("index")[0]var leftArea = document.getElementsByClassName("index-left")[0]var middleArea = document.getElementsByClassName("index-middle")[0]var rightArea = document.getElementsByClassName("index-right")[0]console.log('leftResizeBar =>', leftResizeBar)console.log('wholeArea =>', wholeArea)console.log('leftArea =>', leftArea)console.log('middleArea =>', middleArea)console.log('rightArea =>', rightArea)// 鼠标按下事件leftResizeBar.onmousedown = function (eventDown) {// 颜色提醒leftResizeBar.style.backgroundColor = "#5e7ce0"leftResizeBar.style.color = "#ffffff"// 鼠标移动事件document.onmousemove = function (eventMove) {let width = eventMove.clientXconsole.log('width =>', width)if (width >= 600) {width = 600 // 设置最大拉伸宽度为600} else if (width <= 0) {// 当拉伸宽度为小于或等于0,最小拉伸宽度为0,同时是否收起图标向右width = 0isExpandLeft.value = true} else {// 当拉伸宽度为大于0且小于600,是否收起图标向左isExpandLeft.value = false}leftArea.style.width = width + 'px'}// 鼠标松开事件document.onmouseup = function (evt) {// 颜色恢复leftResizeBar.style.backgroundColor = "#ffffff"leftResizeBar.style.color = "#40485c"document.onmousemove = nulldocument.onmouseup = nullleftResizeBar.releaseCapture && leftResizeBar.releaseCapture() // ReleaseCapture()函数用于释放该元素捕获的鼠标}leftResizeBar.setCapture && leftResizeBar.setCapture() // setCapture()函数用于设置该元素捕获的鼠标为空// 说明:一般情况下,SetCapture()和ReleaseCapture()函数是成对使用的。在使用SetCapture()函数捕获鼠标之后,需要在适当的时候调用ReleaseCapture()函数释放鼠标,否则可能会导致鼠标失去响应或者其他异常情况return false}
}/*** 右侧拖动事件句柄方法*/
const handleDragRightResizeBar = () => {var rightResizeBar = document.getElementsByClassName("right-resize-bar")[0]var wholeArea = document.getElementsByClassName("index")[0]var leftArea = document.getElementsByClassName("index-left")[0]var middleArea = document.getElementsByClassName("index-middle")[0]var rightArea = document.getElementsByClassName("index-right")[0]console.log('rightResizeBar =>', rightResizeBar)console.log('wholeArea =>', wholeArea)console.log('leftArea =>', leftArea)console.log('middleArea =>', middleArea)console.log('rightArea =>', rightArea)// 鼠标按下事件rightResizeBar.onmousedown = function (eventDown) {// 颜色提醒rightResizeBar.style.backgroundColor = "#5e7ce0"rightResizeBar.style.color = "#ffffff"// 鼠标移动事件document.onmousemove = function (eventMove) {let width = wholeArea.clientWidth - eventMove.clientXif (width >= 600) {width = 600 // 设置最大拉伸宽度为600} else if (width <= 0) {// 当拉伸宽度为小于或等于0,最小拉伸宽度为0,同时是否收起图标向左width = 0isExpandRight.value = true} else {// 当拉伸宽度为大于0且小于600,是否收起图标向右isExpandRight.value = false}rightArea.style.width = width + 'px'}// 鼠标松开事件document.onmouseup = function (evt) {// 颜色恢复rightResizeBar.style.backgroundColor = "#ffffff"rightResizeBar.style.color = "#40485c"document.onmousemove = nulldocument.onmouseup = nullrightResizeBar.releaseCapture && rightResizeBar.releaseCapture() // ReleaseCapture()函数用于释放该元素捕获的鼠标}rightResizeBar.setCapture && rightResizeBar.setCapture() // setCapture()函数用于设置该元素捕获的鼠标为空// 说明:一般情况下,SetCapture()和ReleaseCapture()函数是成对使用的。在使用SetCapture()函数捕获鼠标之后,需要在适当的时候调用ReleaseCapture()函数释放鼠标,否则可能会导致鼠标失去响应或者其他异常情况return false}
}onMounted(() => {handleDragLeftResizeBar()handleDragRightResizeBar()
})
</script><style lang="less" scoped>.index {display: flex;flex-direction: row;width: 100%;height: 100%;overflow: hidden;/* ---- ^ 左边 ---- */:deep(.index-left) {position: relative;z-index: 0;display: flex;flex-direction: row;width: 400px;border-right: 1px solid #dcdfe6;.index-left-box {flex: 1;display: flex;flex-direction: column;padding: 7px 0 7px 7px;overflow: hidden;background-color: #f3f6f8;.index-left-box_header {width: 100%;min-width: 400px - 14px;height: auto;.header__navbar {display: flex;width: 100%;align-items: center;font-size: 13px;text-align: center;margin-bottom: 7px;.header__navbar_panorama {flex: 1;margin-right: 5px;padding: 5px 0;border: 1px solid #dcdfe6;transition: all ease 0.3s;cursor: pointer;}.header__navbar_product {flex: 1;margin-left: 5px;padding: 5px 0;border: 1px solid #dcdfe6;transition: all ease 0.3s;cursor: pointer;}.header__navbar_panorama:hover,.header__navbar_product:hover{border: 1px solid #5e7ce0;}.header__navbar_actived {background-color: #5e7ce0;border: 1px solid #5e7ce0;color: #fff;}}.header__form {border-top: 1px solid #dcdfe6;padding-top: 7px;}}.index-left_content {flex: 1;overflow: hidden;border: 1px solid #dcdfe6;}}.left-resize-bar {display: flex;align-items: center;width: 7px;height: 100%;background-color: rgb(255, 255, 255);cursor: col-resize;user-select: none;transition: all ease 0.3s;font-size: 20px;color: #40485c;&:hover {color: #fff !important;background-color: #5e7ce0 !important;}}}/* ---- / 左边 ---- *//* ---- ^ 中间 ---- */:deep(.index-middle) {position: relative;z-index: 1;flex: 1;height: 100%;position: relative;transition: all ease 0.3s;background-color: #ffffff;.index-middle-box {display: flex;position: relative;width: 100%;height: 100%;overflow: hidden;// ^ 是否收起左侧边栏的图标.left-view-more {width: 12px;height: 30px;background-color: #ccc;border-bottom-right-radius: 4px;border-top-right-radius: 4px;position: absolute;display: block;margin: auto;left: 0;top: 0;bottom: 0;cursor: pointer;z-index: 1;transition: all ease 0.3s;&:hover {background-color: #5e7ce0;}.left-view-more-true {width: 100%;height: 10px;position: absolute;display: block;margin: auto;left: 0;right: 0;top: 0;bottom: 0;&::before {display: block;height: 2px;width: 10px;content: "";position: absolute;left: 0;top: 0;background-color: #fff;transform: rotate(70deg);}&::after {display: block;height: 2px;width: 10px;content: "";position: absolute;left: 0;bottom: 0;background-color: #fff;transform: rotate(-70deg);}}.left-view-more-false {width: 100%;height: 10px;position: absolute;display: block;margin: auto;left: 0;right: 0;top: 0;bottom: 0;&::before {display: block;height: 2px;width: 10px;content: "";position: absolute;left: 0;top: 0;background-color: #fff;transform: rotate(-70deg);}&::after {display: block;height: 2px;width: 10px;content: "";position: absolute;left: 0;bottom: 0;background-color: #fff;transform: rotate(70deg);}}}// / 是否收起左侧边栏的图标// ^ 是否收起右侧边栏的图标.right-view-more {width: 12px;height: 30px;background-color: #ccc;border-bottom-left-radius: 4px;border-top-left-radius: 4px;position: absolute;display: block;margin: auto;right: 0;top: 0;bottom: 0;cursor: pointer;z-index: 1;transition: all ease 0.3s;&:hover {background-color: #5e7ce0;}.right-view-more-true {width: 100%;height: 10px;position: absolute;display: block;margin: auto;left: 0;right: 0;top: 0;bottom: 0;&::before {display: block;height: 2px;width: 10px;content: "";position: absolute;left: 0;top: 0;background-color: #fff;transform: rotate(-70deg);}&::after {display: block;height: 2px;width: 10px;content: "";position: absolute;left: 0;bottom: 0;background-color: #fff;transform: rotate(70deg);}}.right-view-more-false {width: 100%;height: 10px;position: absolute;display: block;margin: auto;left: 0;right: 0;top: 0;bottom: 0;&::before {display: block;height: 2px;width: 10px;content: "";position: absolute;right: 0;top: 0;background-color: #fff;transform: rotate(70deg);}&::after {display: block;height: 2px;width: 10px;content: "";position: absolute;right: 0;bottom: 0;background-color: #fff;transform: rotate(-70deg);}}}// / 是否收起右侧边栏的图标}}/* ---- / 中间 ---- *//* ---- ^ 右边 ---- */:deep(.index-right) {position: relative;z-index: 0;display: flex;flex-direction: row;width: 400px;border-left: 1px solid #dcdfe6;.right-resize-bar {display: flex;align-items: center;width: 7px;height: 100%;background-color: rgb(255, 255, 255);cursor: col-resize;user-select: none;transition: all ease 0.3s;font-size: 20px;color: #40485c;&:hover {color: #fff !important;background-color: #5e7ce0 !important;}}.index-right-box {flex: 1;display: flex;flex-direction: column;padding: 7px 7px 7px 0;overflow: hidden;background-color: #f3f6f8;}}/* ---- / 右边 ---- */}
</style>
二、效果如下 ~