全网营销建设网站高端网站定制建设公司哪家好
问题描述:
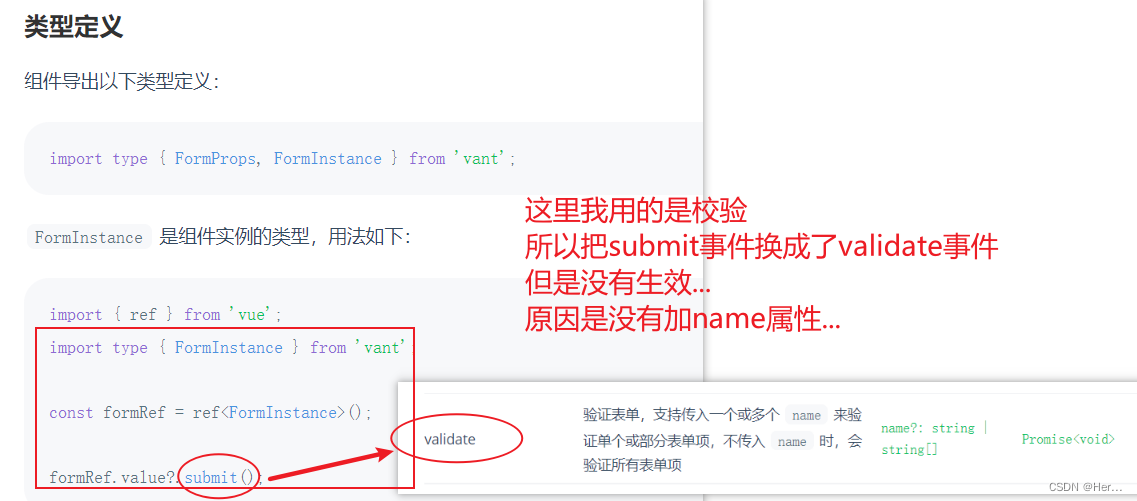
点击发送验证码后,为了让逻辑更加严谨,使用了vant组件自带的表单校验,进行二次校验,防止验证码发送成功后,登录手机号被二次修改,但根据官网描述cv之后不生效,甚至连获取验证码后的倒计时也不走了...
代码如下:
// 获取验证码
const getCode = async () => {
// 节流:如果时间>0就不执行
if (time.value > 0) return
time.value = 10
const res = await getLoginCode(mobile.value, 'login')
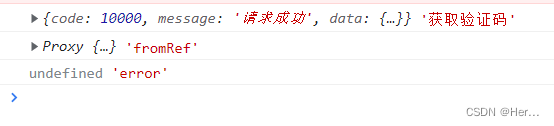
console.log(res, '获取验证码')
code.value = res.data.code
// vant自带的表单校验,防止验证码获取后,手机号再次被修改,再次校验不通过就阻止执行
console.log(formRef.value, 'fromRef')formRef.value?.validate('mobile').catch((error) => {
console.log(error, 'error')
})timeId = setInterval(() => {
time.value -= 1
codeText.value = time.value + 's后再次获取'
if (time.value < 1) {
codeText.value = '发送验证码'
return clearInterval(timeId)
}
}, 1000)
}
用catch捕捉出来的错误是undefined,也就是validate方法传参的name没有值,检查发现是结构里面没加name属性

修改后的代码如下:
<van-form autocomplete="off" @submit="login" ref="formRef">
<van-field
name="mobile"
v-model="mobile"
:rules="mobileRules"
placeholder="请输入手机号"
type="tel"
></van-field>
在需要校验的表单项中加上name属性就可以了
业务代码优化:
const getCode = async () => {
// 节流:如果时间>0就不执行
if (time.value > 0) return
time.value = 10
const res = await getLoginCode(mobile.value, 'login')
console.log(res, '获取验证码')
code.value = res.data.code// vant自带的表单校验,防止验证码获取后,手机号再次被修改,再次校验不通过就阻止执行
// validate的返回值是一个promise,但这里不需要接收返回值,直接加一个await更简单
await formRef.value?.validate('mobile')timeId = setInterval(() => {
time.value -= 1
codeText.value = time.value + 's后再次获取'
if (time.value < 1) {
codeText.value = '发送验证码'
return clearInterval(timeId)
}
}, 1000)
}