网站建设时间计划书让别人做网站的步骤
01.IP
要想让网络中的计算机能够互相通信,必须为计算机指定一个标识号,通过这个标识号来指定要接受数据的计算机和识别发送的计算机,而IP地址就是这个标识号,也就是设备的标识。
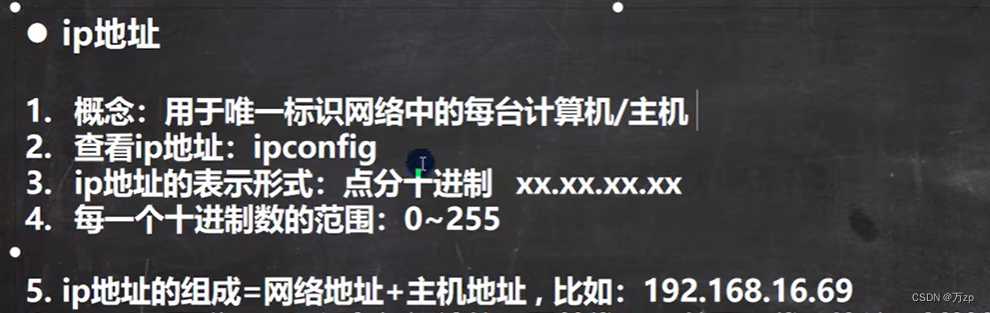
ip地址组成:

ip地址分类:

02.端口号和域名
如果说IP地址可以唯一的标识网络中的设备,那么端口号就可以唯一标识设备中的应用程序,也就是应用程序的标识。

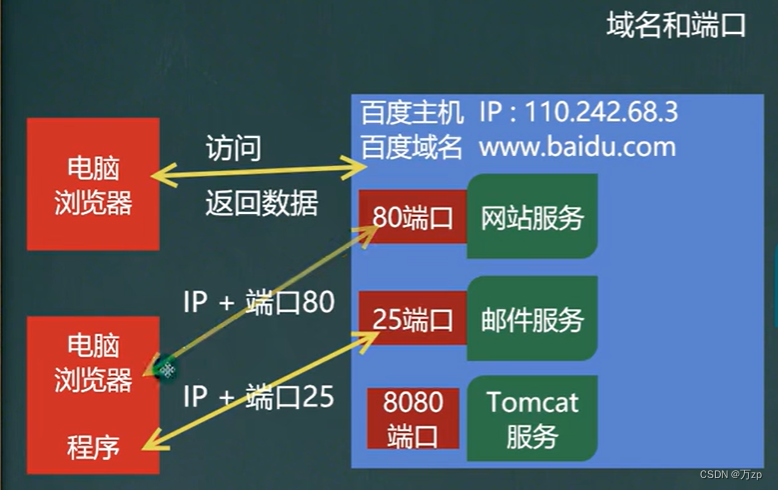
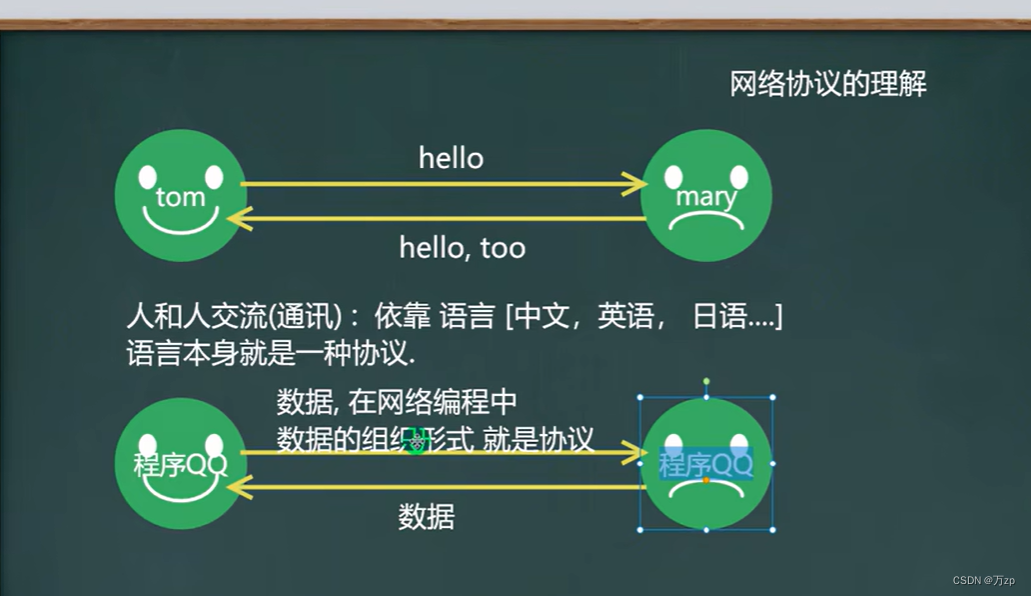
03.TCP/IP协议
协议:

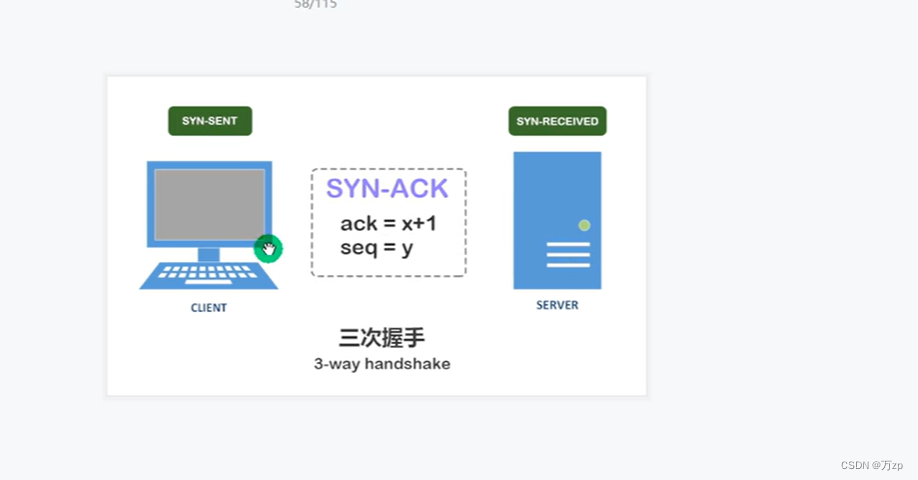
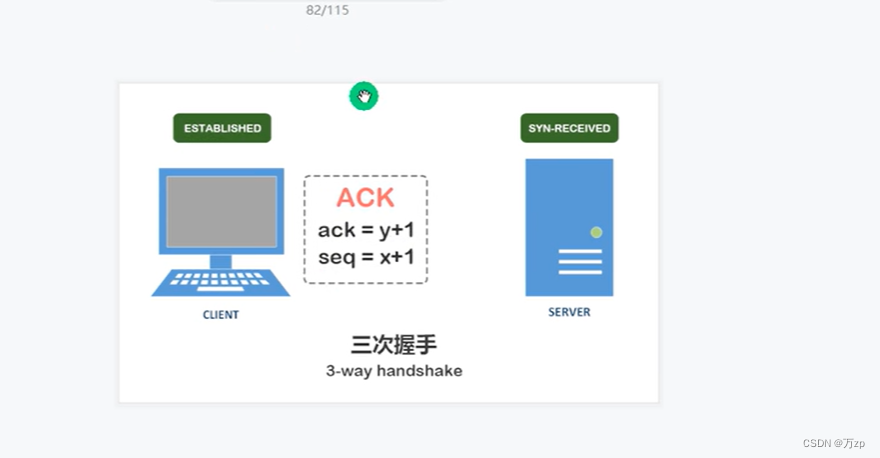
04.TCP/UDP:



05.InetAddress

InetAddress host = InetAddress.getLocalHost();System.out.println(host);

InetAddress host1 =InetAddress.getByName("www.baidu.com");System.out.println(host1);

InetAddress host1 =InetAddress.getByName("www.baidu.com");String address=host1 .getHostAddress() ;String name=host1 .getHostName();System.out.println(host1 );System.out.println(address);System.out.println(name);