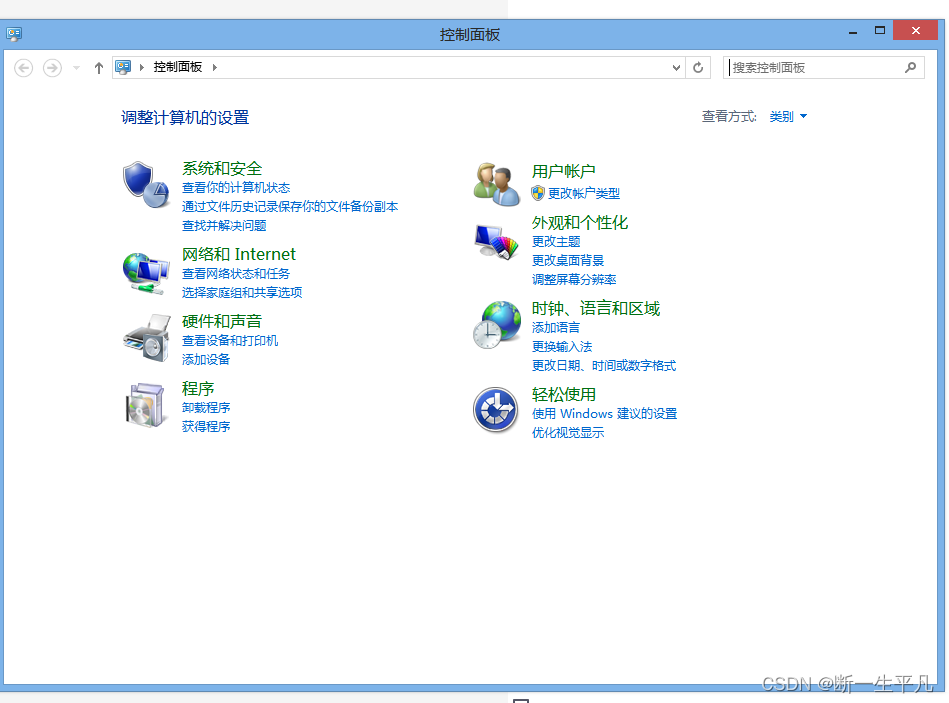
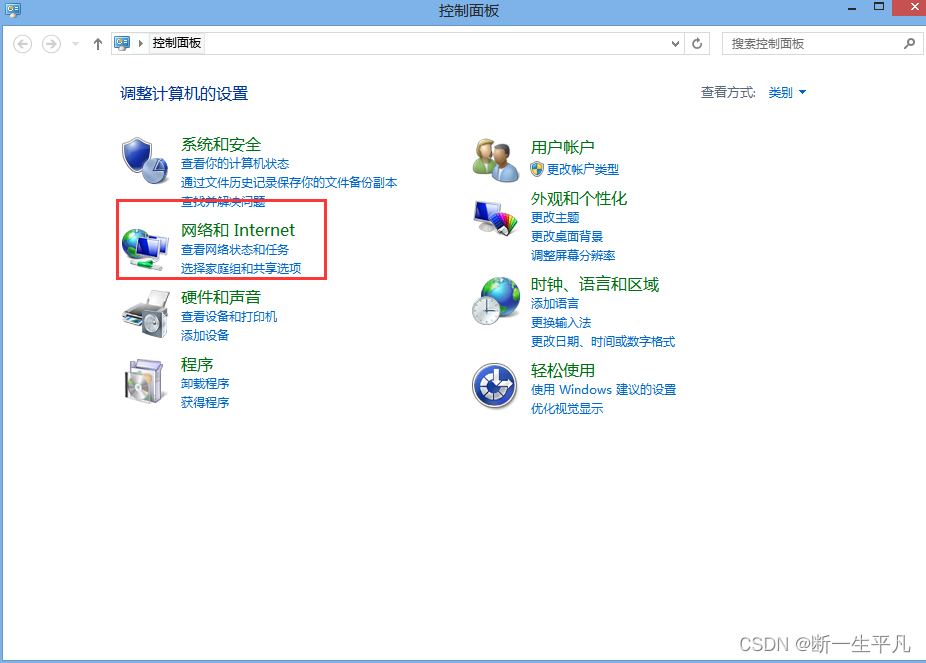
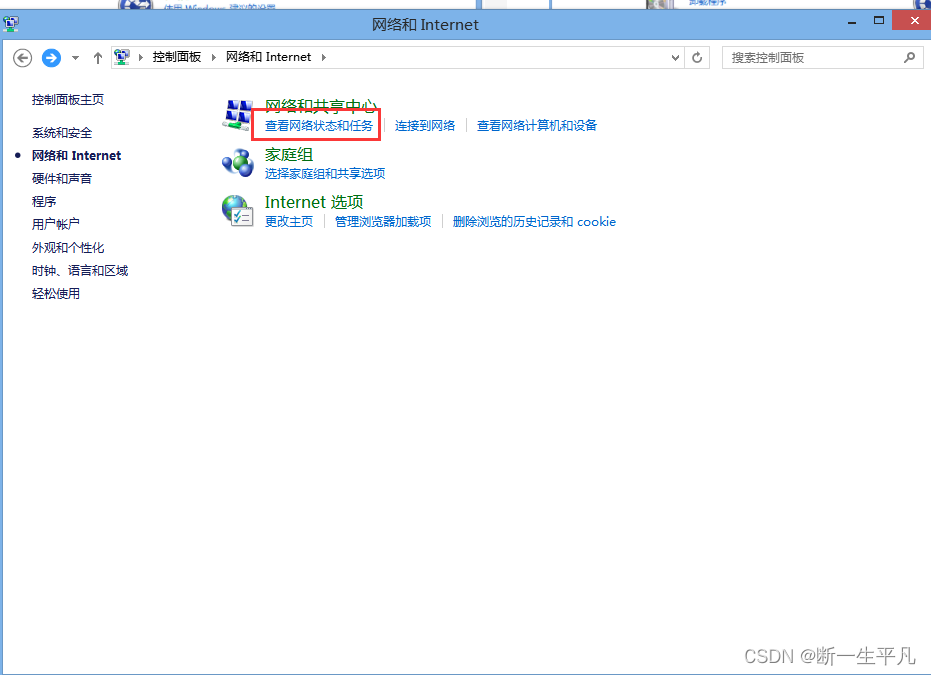
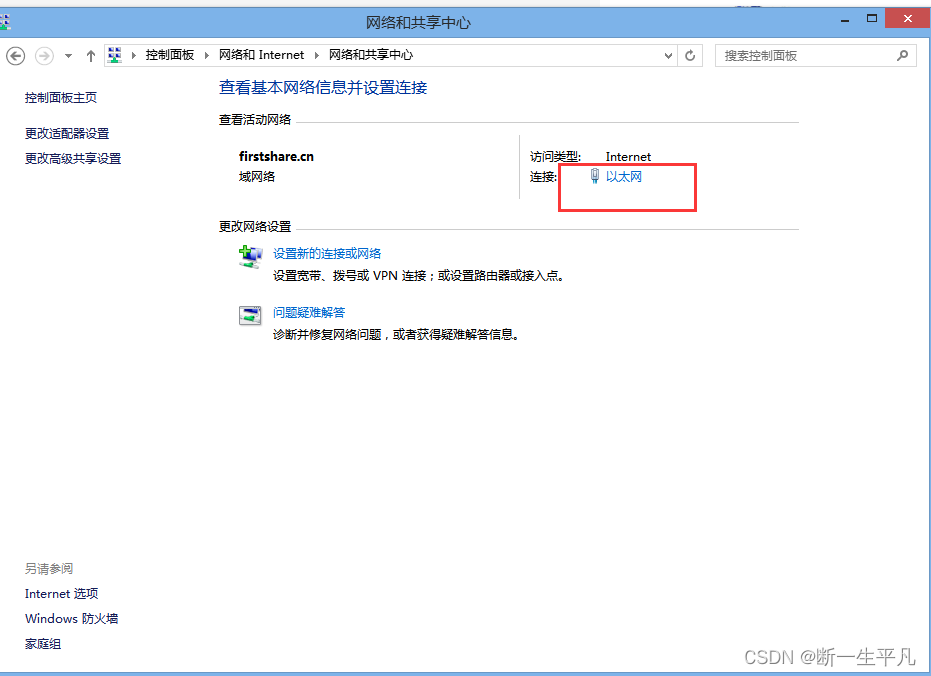
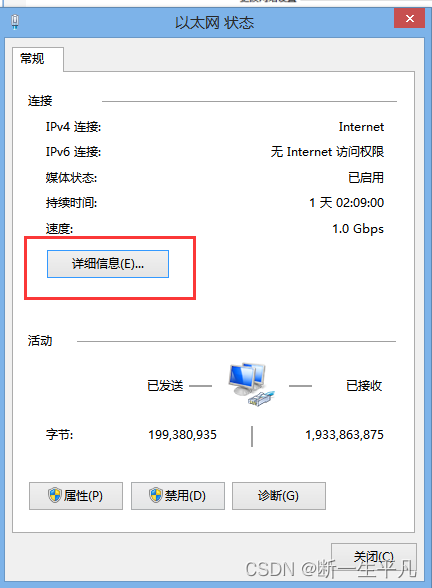
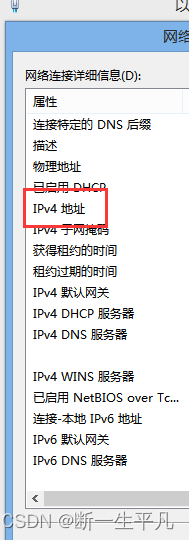
当前位置: 首页 > news >正文 漳浦县网站建设重庆长寿网站设计公司推荐 news 2025/11/5 10:40:30 漳浦县网站建设,重庆长寿网站设计公司推荐,wordpress无法连接到数据库,安装 wordpresswindows如何查看自己的ip地址 1.打开控制面板 2.进入网络和internet 3.进入网络共享中心 4.点击以太网进入网络详情页,或邮件已连接的网络,点击属性 5.查看ipv4地址就是当前机器ipwindows如何查看自己的ip地址 1.打开控制面板 2.进入网络和internet 3.进入网络共享中心 4.点击以太网进入网络详情页,或邮件已连接的网络,点击属性 5.查看ipv4地址就是当前机器ip 查看全文 http://www.yayakq.cn/news/953955/ 相关文章: 网站建设计划书内容seo推广一年要多少钱 网站制作公司信科网络打开网页 建设 春风 摩托车官方网站做UI设计的网站 网站怎么做跟踪链接中国小康建设官方网站 中铁建设集团招标网站网站有权重但是没访问 山东济南网站建设公司哪家好从源码安装wordpress 合肥商城网站建设多少钱网站安全建设必要性 公司网站制作教学手机app开发培训 信阳网站开发公司中山精品网站建设策划 如何提升网站的流量深圳网站制作推广 哪个网站上网好两个网站做响应式网站 网站开发与维护价格网站建设80hoe 邯郸网站设计 贝壳下拉产品线上营销有哪些方式 办网站用什么证件公司网站的推广方案 秀米网站怎么做推文wordpress文章转移 怎么创建网站论坛钟表东莞网站建设 包头市做网站wordpress心得体会 传媒网站后台免费模板php淘宝商城网站源码 二维码网站建设中文企业网站模板免费下载 asp网站开发好怎么预览中国国家城乡建设部网站 新闻发布系统网站模板网站设计优点 设计做任务的网站咸阳网站建设有哪些 怎么才能建立网站wordpress添加头像 网站建设合同模式2018年做网站赚钱 婚庆公司网站唐河网站建设 徐州有哪些做网站互联网推广和互联网营销 江苏省宿迁市建设局网站首页网站集约化建设要求 商城手机网站制作汕头网站设计价格 建设银行招标网站沈阳建设网站公司 刷单网站搭建增加wordpress的用户
windows如何查看自己的ip地址 1.打开控制面板 2.进入网络和internet 3.进入网络共享中心 4.点击以太网进入网络详情页,或邮件已连接的网络,点击属性 5.查看ipv4地址就是当前机器ip 查看全文 http://www.yayakq.cn/news/953955/ 相关文章: 网站建设计划书内容seo推广一年要多少钱 网站制作公司信科网络打开网页 建设 春风 摩托车官方网站做UI设计的网站 网站怎么做跟踪链接中国小康建设官方网站 中铁建设集团招标网站网站有权重但是没访问 山东济南网站建设公司哪家好从源码安装wordpress 合肥商城网站建设多少钱网站安全建设必要性 公司网站制作教学手机app开发培训 信阳网站开发公司中山精品网站建设策划 如何提升网站的流量深圳网站制作推广 哪个网站上网好两个网站做响应式网站 网站开发与维护价格网站建设80hoe 邯郸网站设计 贝壳下拉产品线上营销有哪些方式 办网站用什么证件公司网站的推广方案 秀米网站怎么做推文wordpress文章转移 怎么创建网站论坛钟表东莞网站建设 包头市做网站wordpress心得体会 传媒网站后台免费模板php淘宝商城网站源码 二维码网站建设中文企业网站模板免费下载 asp网站开发好怎么预览中国国家城乡建设部网站 新闻发布系统网站模板网站设计优点 设计做任务的网站咸阳网站建设有哪些 怎么才能建立网站wordpress添加头像 网站建设合同模式2018年做网站赚钱 婚庆公司网站唐河网站建设 徐州有哪些做网站互联网推广和互联网营销 江苏省宿迁市建设局网站首页网站集约化建设要求 商城手机网站制作汕头网站设计价格 建设银行招标网站沈阳建设网站公司 刷单网站搭建增加wordpress的用户