如何创建一个网站卖东西济南 论坛网站建设
【简单介绍】
依托先进的目标检测算法YOLOv8与灵活的PyQt5界面开发框架,我们倾力打造出了一款集直观、易用与功能强大于一体的目标检测GUI界面软件。通过深度融合YOLOv8在目标识别领域的出色性能与PyQt5的精美界面设计,我们成功推出了一款高效且稳定的软件GUI。
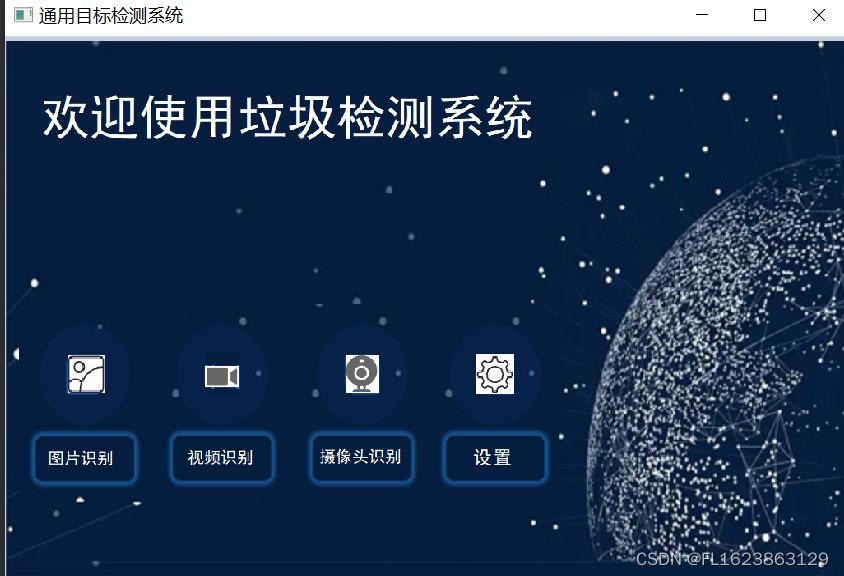
在界面设计方面,我们始终坚持以用户体验和操作便捷为核心。主界面的布局清晰直观,功能模块划分合理,使用户能够迅速上手并熟悉软件的核心功能。同时,我们采用现代时尚的设计风格,运用流畅的线条和柔和的色彩,为用户打造一个既舒适又美观的视觉环境。
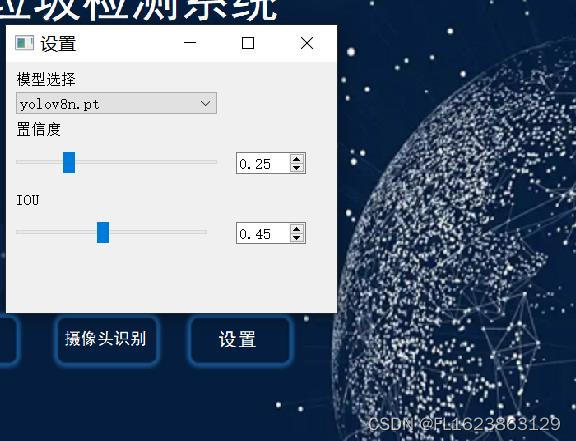
在功能实现上,我们充分发挥了YOLOv8在目标检测领域的优势。通过无缝对接YOLOv8模型,软件能够迅速准确地识别各类目标。用户只需轻松上传待检测的图片或视频,软件便能自动完成检测任务,并以直观清晰的方式呈现结果。此外,我们还提供了丰富的参数设置选项,用户可根据实际需求灵活调整检测参数,以获得更为精确的结果。
除了基础检测功能外,我们还为软件增加了一系列实用的辅助功能。例如,用户可实时查看检测结果,并轻松实现图片、视频文件及摄像头的检测功能,极大地提升了后续分析与分享工作的便捷性。
综上所述,这款基于YOLOv8与PyQt5的精美界面GUI设计软件不仅具备强大的目标检测功能,还充分考虑到用户体验与操作的便捷性。我们坚信,它将成为目标检测领域的佼佼者,为用户带来前所未有的高效与便捷的工作体验。
【效果展示】


【视频演示】
YOLOv8检测界面-PyQt5实现第五套界面演示_哔哩哔哩_bilibili为了满足各种用户口味,我们会推出5套各具特色pyqt5界面演示yolov8检测源码,这是第5套, 视频播放量 1、弹幕量 0、点赞数 0、投硬币枚数 0、收藏人数 0、转发人数 0, 视频作者 未来自主研究中心, 作者简介 未来自主研究中心,相关视频:labelme json转yolo工具用于目标检测训练数据集使用教程,YOLOv8检测界面-PyQt5实现第二套界面演示,基于yolov5-6.0+bytetrack的目标追踪演示,将yolov8封装成一个类几行代码完成语义分割任务,基于yolov5的单目测距视频演示,YOLOv8检测界面-PyQt5实现,基于pyqt5+yolov5+lprnet实现车牌检测和车牌识别系统,用C#部署yolov8的tensorrt模型进行目标检测winform最快检测速度,使用易语言调用opencv进行视频和摄像头每一帧处理,建议所有神经网络初学者必看这个可视化图解,看不懂你找我,教你从零搭建神经网络,手撕CNN!![]() https://www.bilibili.com/video/BV1tx421k7Pv/?vd_source=989ae2b903ea1b5acebbe2c4c4a635ee
https://www.bilibili.com/video/BV1tx421k7Pv/?vd_source=989ae2b903ea1b5acebbe2c4c4a635ee
【源码下载】
https://download.csdn.net/download/FL1623863129/89034948
【测试环境】
windows x64
anaconda3+python3.8
torch==1.9.0+cu111
ultralytics==8.1.23