部门网站建设目的黄页网站大全通俗易懂
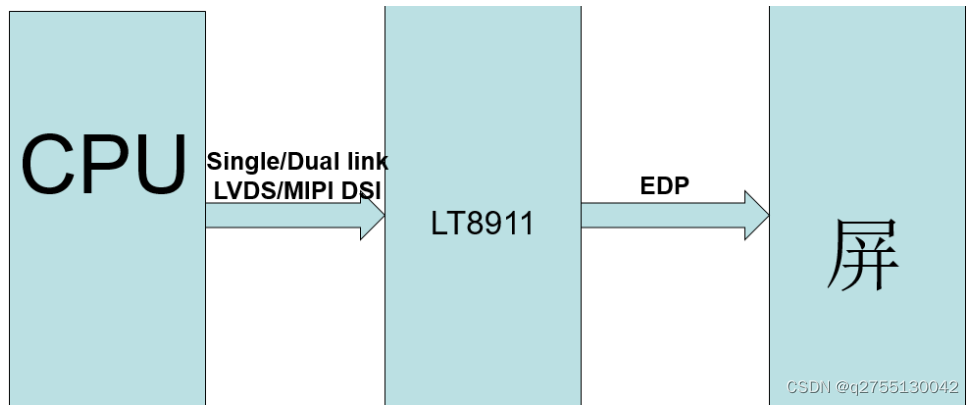
ASL芯片(集睿致远) CS5523是一款MIPI DSI输入,DP/e DP输出转换芯片,可pin to pin替代LT8911龙讯芯片。
MIPI DSI 最多支持 4 个通道,每个通道的最大运行速度为 1.5Gps。对于DP 1.2输出,它支持1.62Gbps和2.7Gbps的链路速率,支持2560 * 1440@60Hz的最高分辨率。单电源1.8V,节省成本并优化电路板空间。
CS5523适用于多个细分市场和显示应用,如手持设备,主板,双面板显示器和汽车显示器等等,CS5523芯片MIPI转EDP方案设计原理图如下:
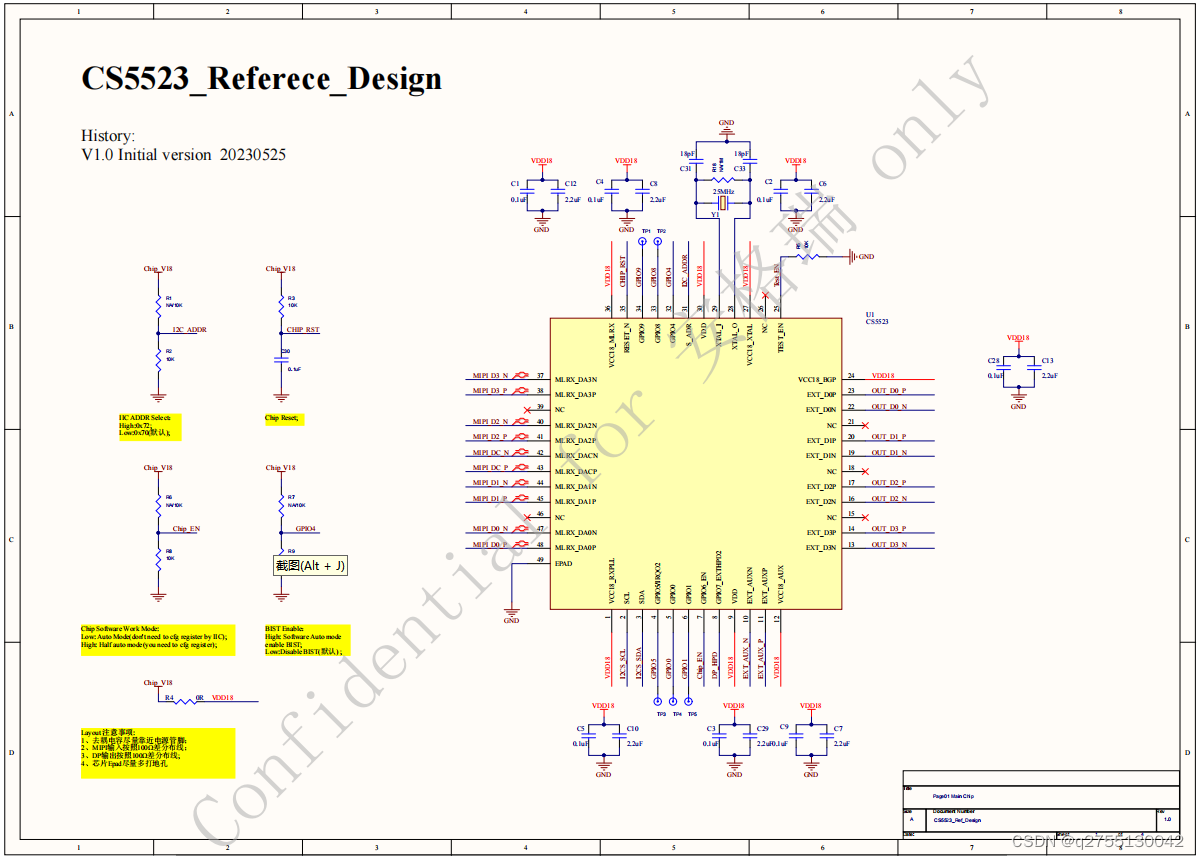
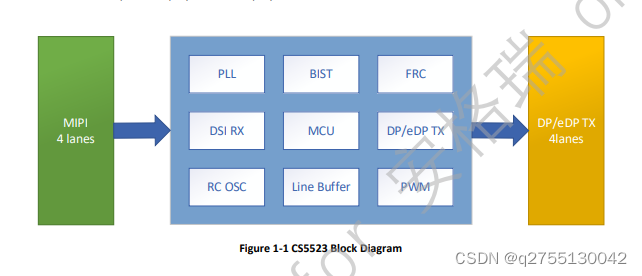
一.CS5523规格及特点
MIPI DSI 输入和 DP/EDP 输出:
支持抖动和6位+FRC
将 PWM 发生器与 GPIO 输出 PWM 集成以控制背光
内部上电复位 (POR)
嵌入式电子硬盘
带SPI闪存控制器的嵌入式MCU
MIPI 输入:
支持同步事件/同步脉冲模式
在V型消隐期间,支持所有线路进入低功耗模式
支持通道/极换
支持连续时钟和/或非连续时钟
支持 MIPI ® D-PHY 版本 1.2 和 MIPI® DSI 版本 1.3
支持 1 至 4 个数据通道 1 个时钟通道
双向车道 0(仅倒车 LP)
支持 ULPS(超低功耗统计)
支持18/24/30/36位的打包像素格式RGB
支持松散打包的 18 位像素格式 RGB
DSI 主机可以在 ESCAPE 模式下访问本地寄存器
电子数据处理/DP 输出:
符合 VESA DisplayPortTM (DP)v1.2 标准
符合 VESA 嵌入式显示端口TM (eDP)v1.2 标准
支持 4 通道高达 HBR(2.7Gbps) 输出
支持6,8bpc,RGB输出
支持EDP ASSR功能
支持数据通道和极换
支持 1Mbps 辅助通道
支持多达 2560x1440@60Hz
- 龙讯LT8911特点
LT8911是一颗将LVDS/MIPI DSI信号转换成EDP信号的转接芯片,应用产品:广告机,平板、医疗器械、车机、显示器、小电视、车载电视等。ASL集睿致远CS5523可pin to pin替代LT8911龙讯芯片。
设计注意事项:
A、LT8911设计的时候要特别注意输入输出的走线问题,要做好屏蔽以免信号受到干扰。
B、注意电源滤波
C、设计的时候预留LVDS信号要预留阻抗匹配电阻
D、设计的时候复位脚最好由客户CPU的GPIO口进行控制,以便控制整个方案的时序,避免后面出现问题。