建设银行公积金预约网站首页鲜花网站建设项目概述
目录
前言
1、处理参数的方式不同
2、${}的优点
3、SQL注入问题
4、like查询问题
前言
#{}和${}都可以在MyBatis中用来动态地接收参数,但二者在本质上还是有很大的区别。
1、处理参数的方式不同
${} :预编译处理
MyBatis在处理#{}时,会将SQL语句中的#{}替换为?,即占位符,然后使用PreparedStatement的set方法来赋值。
代码示例:
<select id="getUserByID" resultType="com.example.demo.model.UserInfo">select * from userinfo where id=#{id}</select>查看程序运行期间MyBatis打印的日志:

#{} :直接替换
MyBatis在处理${}时,会直接将SQL语句中的${}替换为参数的值。
代码示例:
<select id="getUserByID" resultType="com.example.demo.model.UserInfo">select * from userinfo where id=${id}</select>查看程序运行期间MyBatis打印的日志:

使用${}接收int类型的参数时是不会报错的,但是用来接收String类型的参数时代码就会报错:
代码示例:
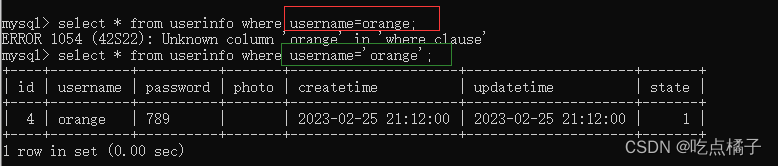
<!-- 根据用户名查询用户信息 --><select id="getUserByName" resultType="com.example.demo.model.UserInfo">select * from userinfo where username=${name}</select>查看程序运行期间MyBatis打印的日志:

"orange"是userinfo表中的一个用户名,在查询时需要加上单引号才能查询成功:
2、${}的优点
使用${}可以实现对查询结果的动态排序(升序/降序);而使用#{}则不能实现,如果传递的参数是String类型,#{}会对参数加单引号,就会出现SQL语句错误。
代码示例:
<!-- 查询所有用户并排序 --><select id="getAll" resultType="com.example.demo.model.UserInfo">select * from userinfo order by ${order}</select>
如果使用#{}时,最终的SQL语句为:select * from userinfo order by id 'desc'

3、SQL注入问题
由于${}是直接替换参数,不会给参数添加单引号,因此会导致SQL语句错误,如果非要使用${},就需要手动对参数添加单引号:

但这样又会带来SQL注入的问题:
代码示例:
<!-- 登录功能 --><select id="login" resultType="com.example.demo.model.UserInfo">select * from userinfo where username='${username}' and password='${password}'</select>传入参数:"' or 1 = '1"

表中用户的正确用户名和密码:

查询结果:

而使用#{}就不会出现SQL注入的问题:


结论:能使用#{}就使用#{}!如果非要使用${},那么一定要进行参数校验。
4、like查询问题
在进行like查询时,使用#{}会报错:
代码示例:
<select id="getUserByLike" resultType="com.example.demo.model.UserInfo">select * from userinfo where username like '%#{msg}%'</select>![]()
此时最终的SQL语句为: select * from userinfo where username like '%‘a'’%'
而使用${}时,虽然可以达到目的,成功查询到数据,但是${}会有SQL注入问题,使用时需要进行参数校验,而用户输入的内容则是多种多样的,我们无法全部校验。
为了解决这个问题,就需要使用MySQL的内置函数concat()来处理:
<select id="getUserByLike" resultType="com.example.demo.model.UserInfo">select * from userinfo where username like concat('%',#{msg},'%')</select>