wordpress程序建站游戏推广员平台
一、下载IDEA
下载地址:https://www.jetbrains.com/idea/download/?section=windows#section=windows
拉到下面使用免费的IC版本即可。
 运行下载下来的exe文件,注意安装路径最好不要安装到C盘,可以改成其他盘,其他选项按需勾选即可。
运行下载下来的exe文件,注意安装路径最好不要安装到C盘,可以改成其他盘,其他选项按需勾选即可。
二、创建Java项目
运行IDEA,创建新的项目。
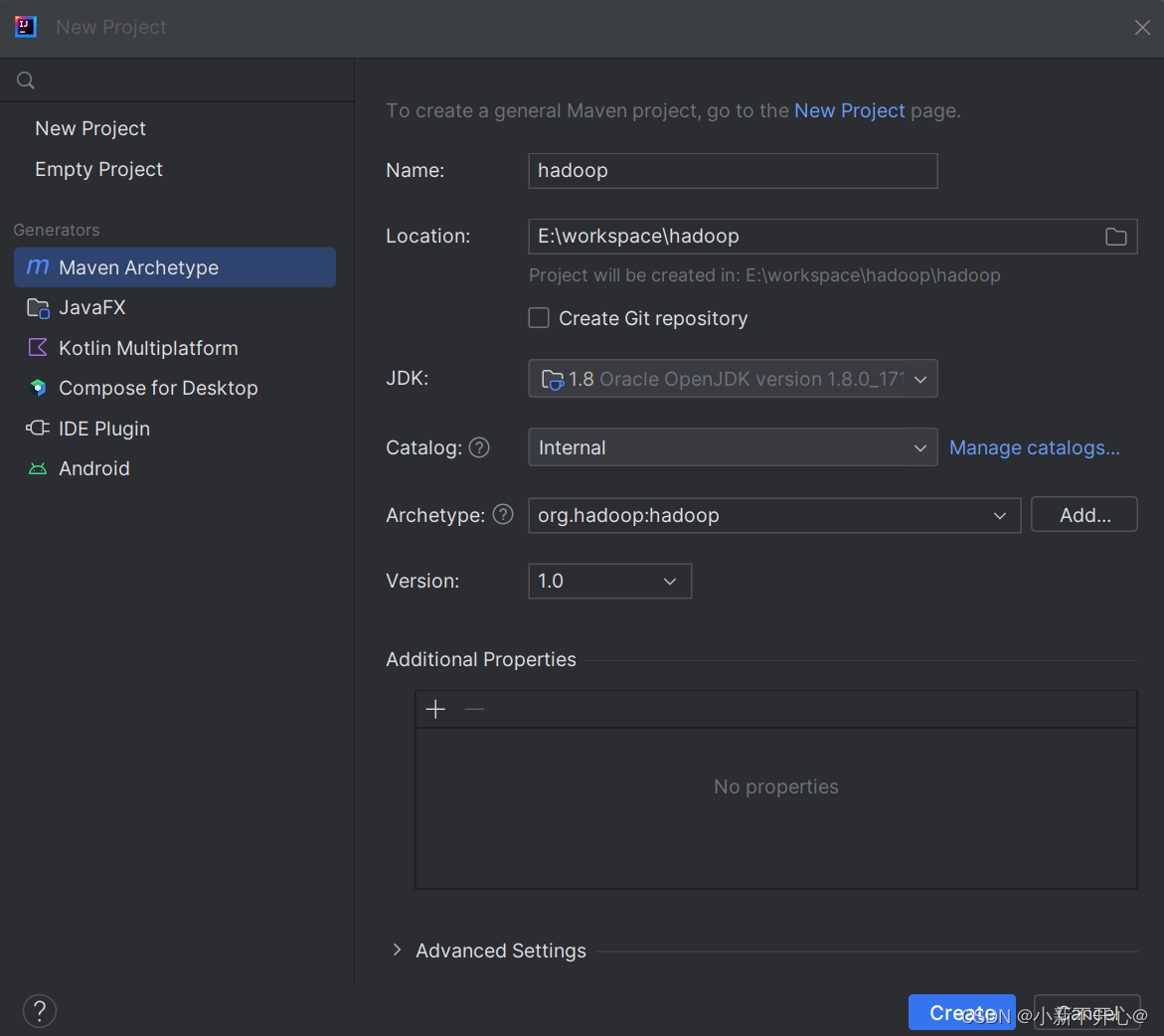
 选择创建maven项目
选择创建maven项目
 为了方便管理,将hadoop作为父项目,所以修改Hadoop的项目类型为pom。找到pom.xml,并添加packaging标签,dependencymanagement,子模块就只需要添加依赖名,不需要导入依赖版本。
为了方便管理,将hadoop作为父项目,所以修改Hadoop的项目类型为pom。找到pom.xml,并添加packaging标签,dependencymanagement,子模块就只需要添加依赖名,不需要导入依赖版本。
<packaging>pom</packaging>
<dependencyManagement><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.2.2</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version><scope>test</scope></dependency></dependencies></dependencyManagement>
三、创建新的子模块
右键hadoop文件-new-module
查看依赖
添加Java class
四、HDFS操作示例
1.显示HDFS制定目录下的所有目录。
在pom.xml里添加需要用到的依赖
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-configuration2</artifactId><version>2.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.3.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.3.1</version><scope>test</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>3.3.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.1</version></dependency>
参考代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;import java.io.IOException;public class Demon {public static void main(String[] args) throws IOException {System.setProperty("HADOOP_USER_NAME","root");//访问hadoop用户名,这里我设置的是root,如果是别的用户名需要修改Configuration config = new Configuration();//声明一个新的访问配置对象config.set("fs.defaultFS","hdfs://192.168.56.201:8020");//设置访问的具体地址FileSystem fs = FileSystem.get(config);//创建一个新的文件系统对象FileStatus[] stas = fs.listStatus(new Path("/"));for(FileStatus f : stas){System.out.println(f.getPermission().toString() + "" + f.getPath().toString());//输出根目录下的所有文件或目录,不包含子目录}fs.close();}
}
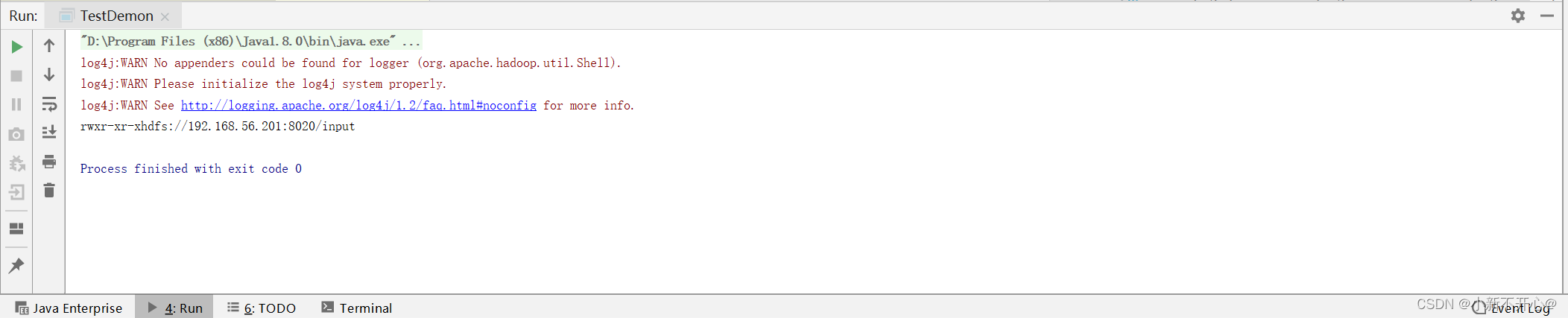
输出结果:
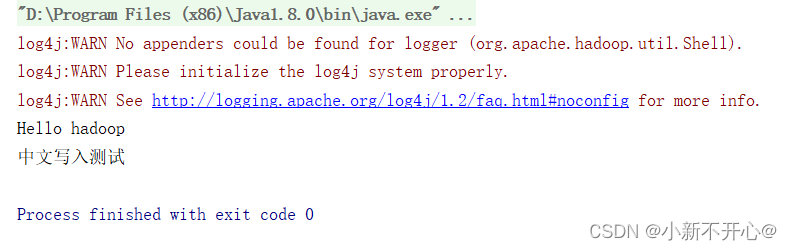
 2.向HDFS写入内容writefiles
2.向HDFS写入内容writefiles
参考代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;import java.io.IOException;
import java.io.OutputStream;public class Demo04WriteFile {public static void main(String[] args) throws IOException {String server = "hdfs://192.168.56.201:8020";System.setProperty("HADOOP_USER_NAME", "root");Configuration config = new Configuration();config.set("fs.defaultFS", server);try (FileSystem fs = FileSystem.get(config)) {OutputStream out = fs.create(new Path(server+"/test/b.txt"));out.write("Hello hadoop\n".getBytes());out.write("中文写入测试\n".getBytes());out.close();}}
}
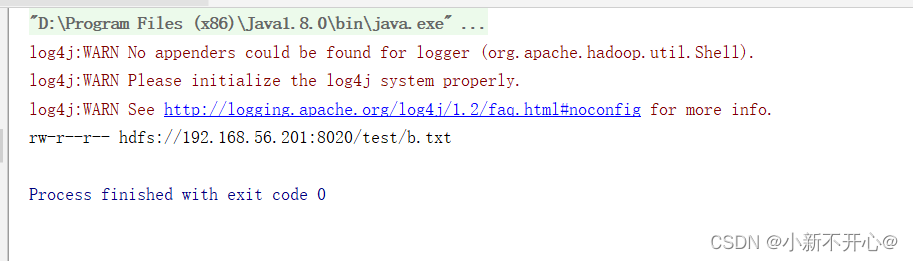
输入hdfs dfs -cat /test/b.txt查询,成功写入

3.listfile显示所有文件
参考代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;import java.io.IOException;public class Demo02ListFiles {public static void main(String[] args) throws IOException {System.setProperty("HADOOP_USER_NAME", "root");Configuration config = new Configuration();config.set("fs.defaultFS", "hdfs://192.168.56.201:8020");FileSystem fs = FileSystem.get(config);RemoteIterator<LocatedFileStatus> files =fs.listFiles(new Path("/test"), true);while (files.hasNext()) {LocatedFileStatus file = files.next();System.out.println(file.getPermission() + " " + file.getPath());}fs.close();}
}
输出结果:
 4.读取HDFS文件的内容filesystem.open
4.读取HDFS文件的内容filesystem.open
代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;import java.io.DataInputStream;
import java.io.IOException;public class Demo03ReadFile {public static void main(String[] args) throws IOException {String server = "hdfs://192.168.56.201:8020";System.setProperty("HADOOP_USER_NAME", "root");Configuration config = new Configuration();config.set("fs.defaultFS", server);try (FileSystem fs = FileSystem.get(config)) {DataInputStream in = fs.open(new Path(server+"/test/b.txt"));int len = 0;byte[] bs = new byte[1024];while ((len = in.read(bs)) != -1) {String str = new String(bs, 0, len);System.out.print(str);}}}}
输出结果: