班级网站怎么做网页制作wordpress用ssd服务器的优势
这篇文章分享一下笔者常用的Docker命令供各位读者参考。
为什么要用Docker?
简单来说:Docker通过提供轻量级、隔离且可移植的容器化环境,使得应用在不同平台上保持一致性、易于部署和管理,具体如下
- 环境一致性: Docker容器使得应用及其所有依赖项(如库、操作系统、配置文件等)都打包在一起,可以确保在任何地方运行时都具有相同的环境,不论是开发、测试还是生产环境。
- 跨平台兼容性: Docker容器可以在不同操作系统(如Windows、Linux和macOS)上运行,确保应用程序在不同环境中的一致性。
- 隔离性: 每个容器运行在隔离的环境中,不会干扰主机操作系统或其他容器。这样,开发人员可以在同一台机器上同时运行多个不同版本的应用和服务,而不会产生冲突。
- 轻量级和高效: 与虚拟机相比,Docker容器更加轻量级,启动速度更快,占用资源更少。这使得容器化应用的性能更好,并能够在相同的硬件上运行更多的实例。
- 可移植性: 由于Docker容器中包含了应用程序及其所有依赖项,因此可以轻松地将应用从开发环境迁移到生产环境,甚至在不同的云平台之间迁移。
- 版本控制和更新管理: Docker镜像可以被版本控制,当需要更新应用时,可以简单地创建新镜像并部署,这简化了应用的更新和回滚操作。
- 自动化部署: Docker与CI/CD(持续集成/持续部署)工具兼容,可以帮助自动化应用的构建、测试、部署和扩展,提升开发效率和运维灵活性。
- 资源利用率高: Docker容器共享操作系统内核,因此比虚拟机更高效,减少了资源的浪费。
- 分布式应用支持: Docker容器可以在集群环境中轻松运行,支持微服务架构,方便开发和管理分布式应用。
一、镜像管理
1.拉取镜像
docker pull [image]
2.查看镜像
docker images

3.导入镜像
docker load -i your_docker.tar

4.构建镜像
docker -f /path/dockerfile build -t my_image:latest .
5.将容器打包成镜像
为什么要将容器commit成镜像?
- 持久化容器状态:容器在运行时是临时的,一旦停止或删除,容器中的所有更改都会丢失。如果你在容器中做了配置或安装了一些依赖,
commit容器可以将这些更改保存为镜像,方便以后重新使用或分发。 - 版本控制:通过将容器状态保存为镜像,可以为应用创建不同的版本。例如,开发过程中每次变更后都可以创建一个新的镜像版本,便于追溯和管理。
- 迁移和分发:将容器保存为镜像后,可以通过镜像在不同环境或服务器之间迁移。这样,开发环境中的配置和软件版本可以准确复制到生产环境。
- 自动化部署:当容器的状态被
commit成镜像后,可以将这个镜像推送到 Docker Hub 或其他镜像仓库,方便团队成员或CI/CD流水线在不同机器上拉取并使用相同的镜像进行部署。 - 共享和协作:如果你在容器中做了一些定制化的修改,可以将这些修改保存为镜像,然后与团队成员共享。其他人可以基于这个镜像继续开发或部署。
简单来说,commit 容器成镜像是为了将动态容器环境固定下来,便于以后复用、管理和共享。
前提:容器正常运行中
docker commit <container_id> <repository_name>:<tag>
<container_id> 是你的容器ID。
<repository_name> 是你想要给镜像的名字。
<tag> 是你想要给镜像的标签,通常用 latest 表示最新版本。

检查是否成功

dockerfile.txt信息如下
FROM playphone:v5.0
WORKDIR /workspace
ENTRYPOINT bash start.sh & python3 rm.py & tail -f /dev/null
参数解析
- FROM playphone:v5.0:指定构建镜像时所使用的基础镜像。
- WORKDIR /workspace:设置工作目录。指定了容器内的当前工作目录。当后续的命令在容器中执行时,它们会相对于这个目录来执行。
- ENTRYPOINT bash start.sh & tail -f /dev/null:指定容器启动时运行的命令或脚本。
6.构建镜像
docker build -f /data/dockerfile.txt -t playphone:v5.1 .

检查是否成功

7.导出镜像
docker save -o <output_file>.tar <image_name>:<tag>
<output_file>.tar 是导出文件的名称。
<image_name>:<tag> 是你要导出的镜像名称和标签。

8.删除镜像
docker rmi <container_id>

二、容器管理
1.查看容器
docker ps -a
- CONTAINER ID:容器的唯一标识符(短ID)。
- IMAGE:容器是基于哪个镜像创建的。
- COMMAND:启动容器时执行的命令。
- CREATED:容器创建的时间。
- STATUS:容器的当前状态,可能是“Up”表示正在运行,或“Exited”表示已停止,后面跟着退出码等信息。
- PORTS:容器暴露的端口映射。
- NAMES:容器的名称(自动或手动设置)。

2.创建容器
docker run --gpus all -v /data:/data --shm-size 16g -it -d -p 8025:5000 --name='spiderman' carton-detect:v1.0 /bin/bash
-gpus all: 允许容器使用主机上的所有 GPU。这对于需要 GPU 加速的任务(如深度学习)非常重要。v /data:/data: 将主机上的/data目录挂载到容器内的/data目录。这允许容器访问和使用主机上的数据。-shm-size 16g: 设置共享内存大小为 16GB。这在需要大量共享内存的应用(如一些数据处理和机器学习任务)中很有用。it:i保持标准输入打开,t分配一个伪终端。通常用于需要与容器进行交互的情况。d: 后台运行容器。p 5581:18887: 将主机的 8025端口映射到容器的 5000 端口。这样可以通过主机的 8025 端口访问容器内的服务。-name='名字': 为容器指定一个名称,便于管理。cef698e9f00b: 镜像的 ID,表示基于哪个镜像创建容器。/bin/bash: 启动容器后执行的命令,这里是进入 Bash shell。
注:如果资源不够或者在本地,可能修改命令。笔者是在服务器上运行此命令,docker容器启动时,指定的端口参数是 -p 8025:5000,即宿主机的端口8025映射到容器内的端口 5000。本地访问:本地通过宿主机ip和端口8025访问该容器。
什么是共享内存(SHM,Shared Memory):
- 共享内存是多进程间通信的一种机制,通过这种机制,多个进程可以直接访问同一块内存区域,从而实现高效的数据交换。
- 默认情况下,Docker 容器的
/dev/shm目录大小为 64MB。如果你的应用程序需要更多的共享内存,可以使用--shm-size参数来增加该大小。
-it:(interactive、tty):
- i(保持标准输入打开):i 是 --interactive 的简写,表示保持容器的标准输入(stdin)打开。即使你没有附加到容器,这也允许你在容器中运行交互式命令。这对于需要与容器内的进程进行交互的情况非常有用,例如运行一个需要用户输入的程序。
- -t(分配一个伪终端):t 是 --tty 的简写,表示为容器分配一个伪终端(pseudo-TTY)。这使得容器能够提供类似终端的功能,并且可以更好地处理用户输入和显示输出。通常与 -i 一起使用,使你能够获得一个交互式的 shell 环境。
- 组合使用 -it: 当你将 -i 和 -t 组合使用(即 -it)时,你可以启动一个交互式的容器终端,可以输入命令并实时查看输出。这在需要调试、测试或运行需要用户交互的程序时非常有用。

3.查看容器日志
docker logs spiderman

4.进入容器
docker exec -it spiderman /bin/bash

5.退出容器
exit

6.停止容器
docker stop spiderman

7.启动容器
docker start spiderman

8.删除容器
前提:容器关闭中
docker rm spiderman

三、系统命令
1.显示Docker的系统信息
docker info

2.查看容器信息
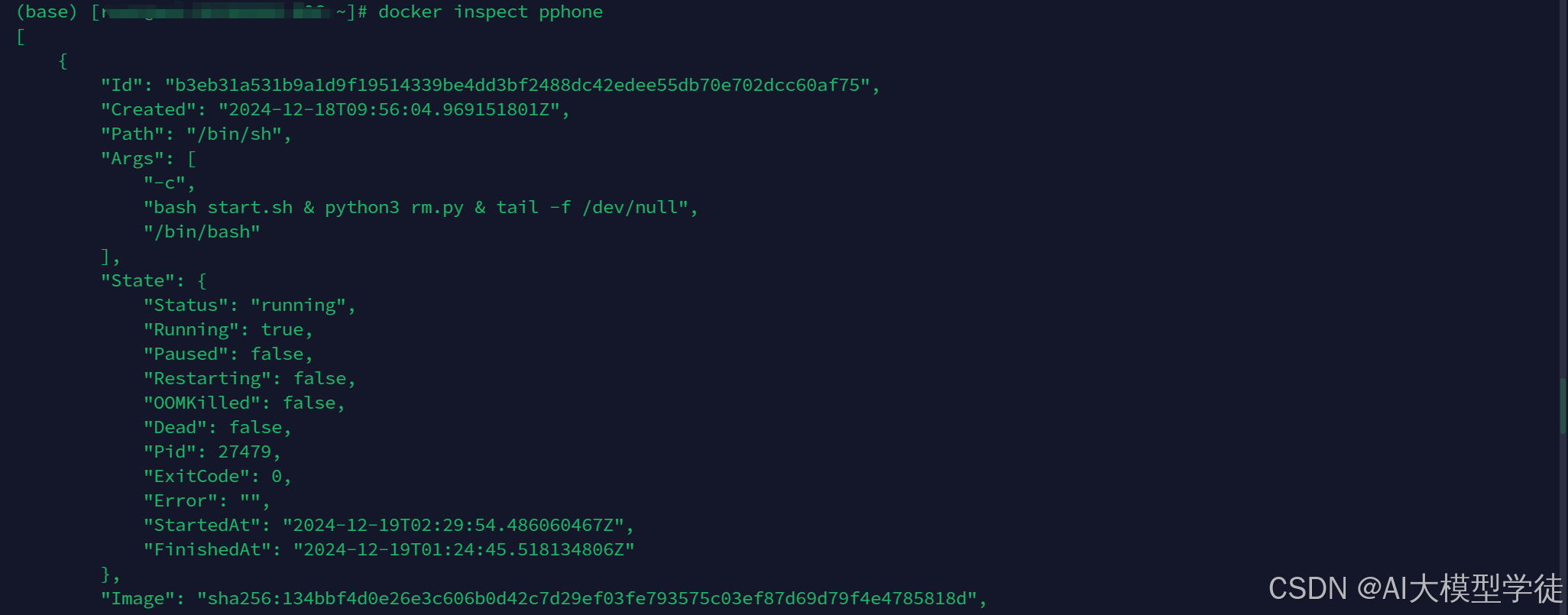
docker inspect your-container
这个命令会输出名为 your-container 的容器的所有详细信息(如配置、网络设置、存储卷、环境变量等)。