怎么做宣传网站上海建站外贸
本篇内容主要介绍使用华为云CodeArts IDE for Java创建工程、代码补全、运行调试代码、Build构建和测试相关的主要功能。
一、下载安装华为云CodeArts IDE for Java
-
华为云CodeArts IDE for Java安装要求
至少需要 2 GB RAM ,但是推荐8 GB RAM;
至少需要 2.5 GB 硬盘空间,推荐SSD;
64位Microsoft Windows 10
- 下载并安装华为云CodeArts IDE for Java
>>>前往华为云CodeArts IDE for Java官方下载页面
下载完成后,运行codearts-java-*.exe文件。
按照安装导航的步骤,选择个人安装配置进行安装。
二、登录
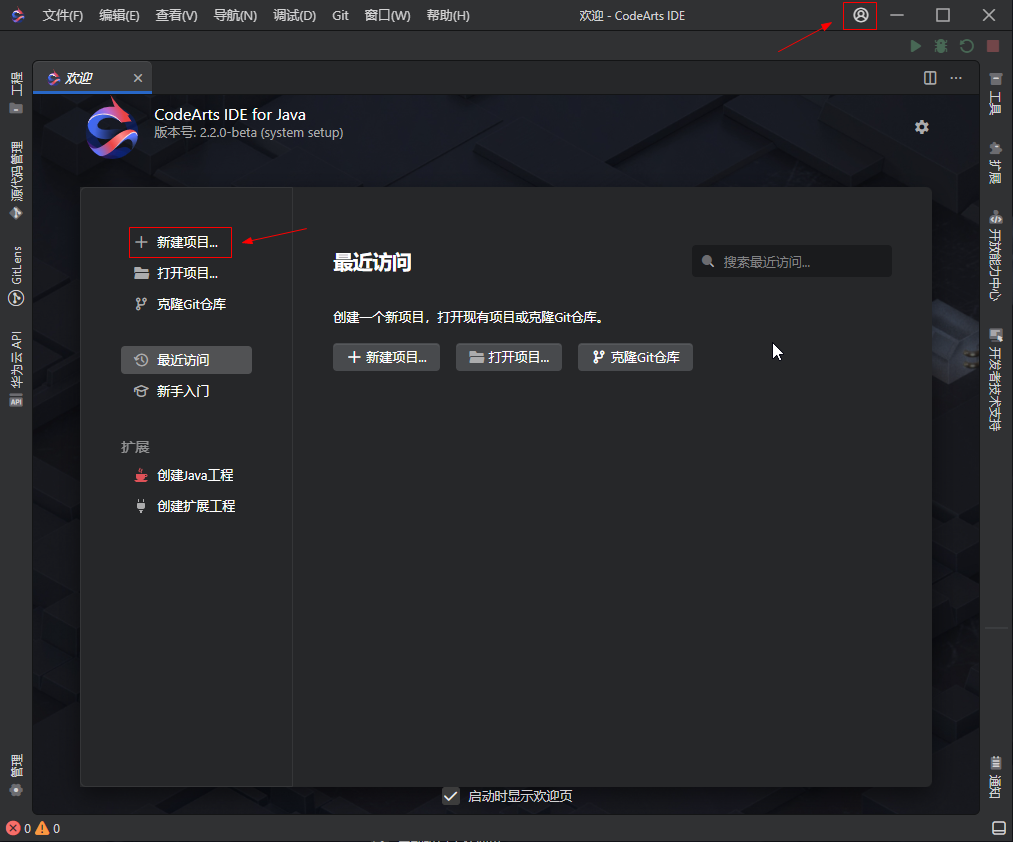
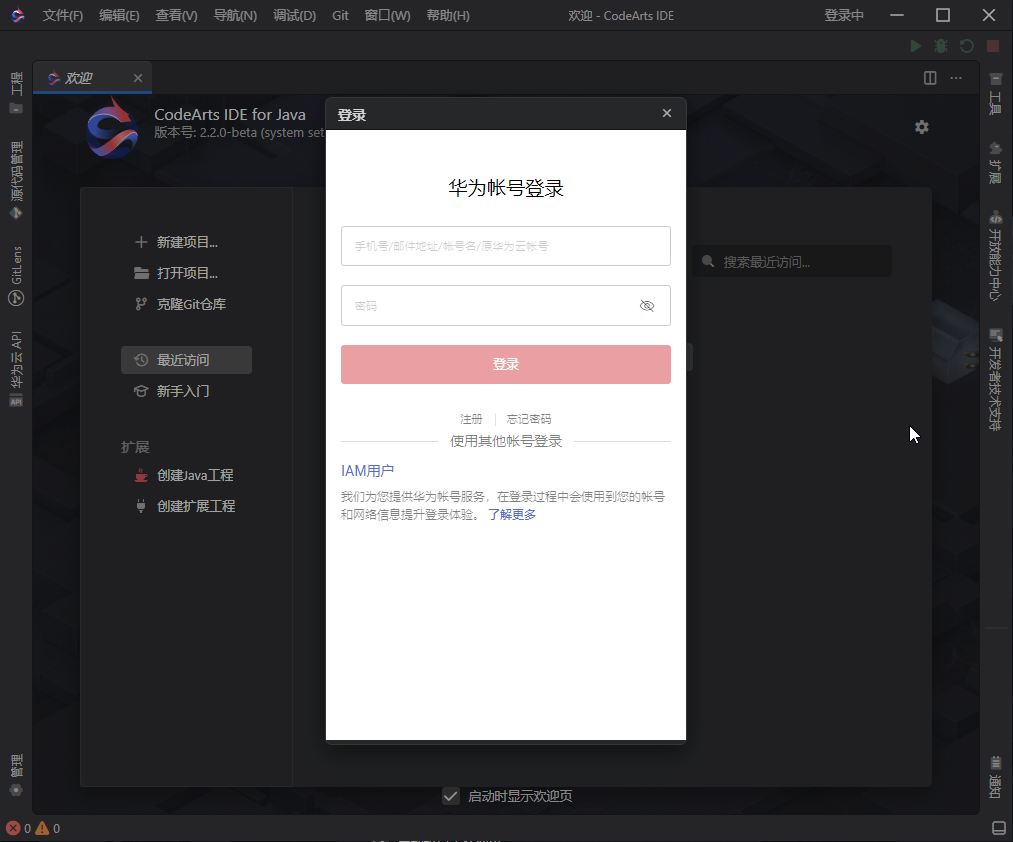
华为云CodeArts IDE for Java要求用户登录后才能激活并使用Java语言服务和运行调试的相关功能。打开CodeArts IDE后,可以通过点击右上角的登录入口,使用华为账号进行登录:
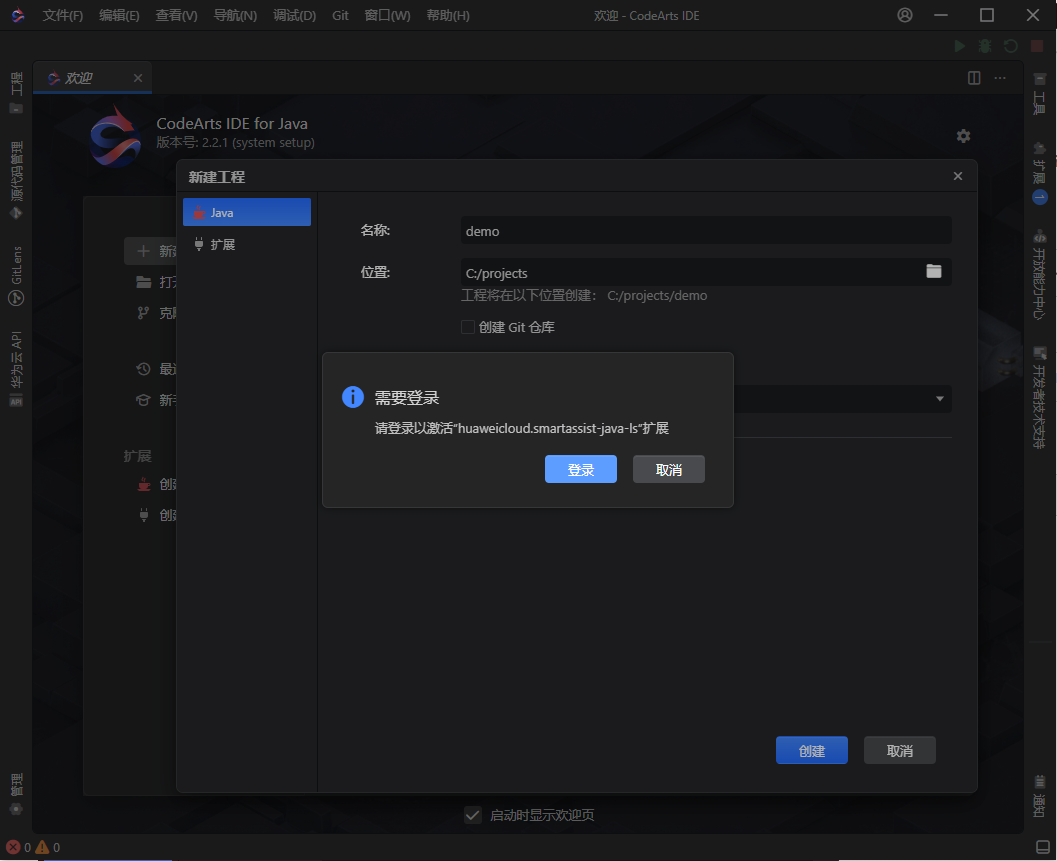
也可以在新建Java项目时弹出的需要登录弹窗中,点击登录按钮进行登录:
三、创建Java工程
- 华为云CodeArts IDE for Java可以通过新建工程向导界面创建Java工程,支持选择四种Java模板创建工程(构建系统:Maven/Gradle,框架:None/SpringBoot),选择创建SpringBoot工程时,可根据需求选择(可多选)相应的第三方依赖,创建成功后第三方依赖被成功写入pom.xml或build.gradle文件。新建工程界面效果如下:
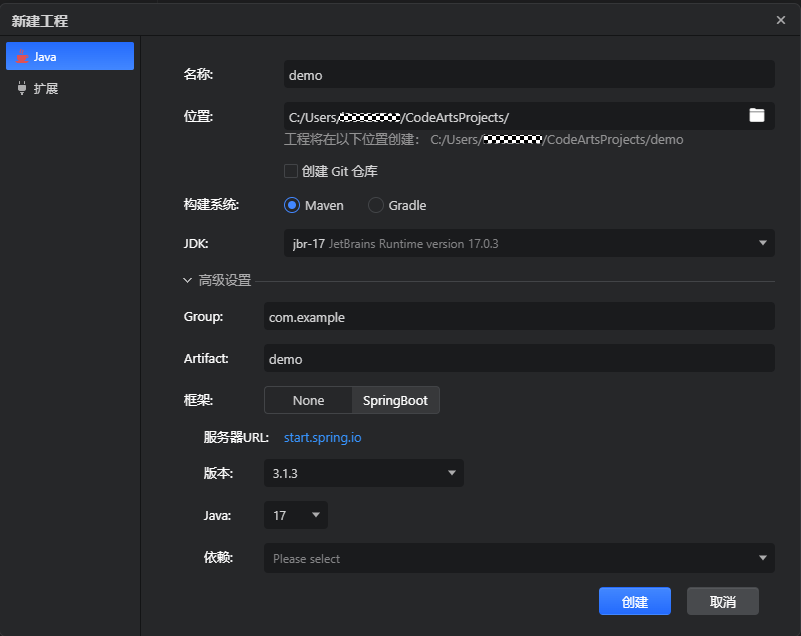
-
华为云CodeArts IDE for Java有三种方式打开新建Java工程向导界面,方式如下:
1. 点击“文件->新建->工程”菜单:

2. 在欢迎界面点击“新建项目”或者“创建Java工程”:
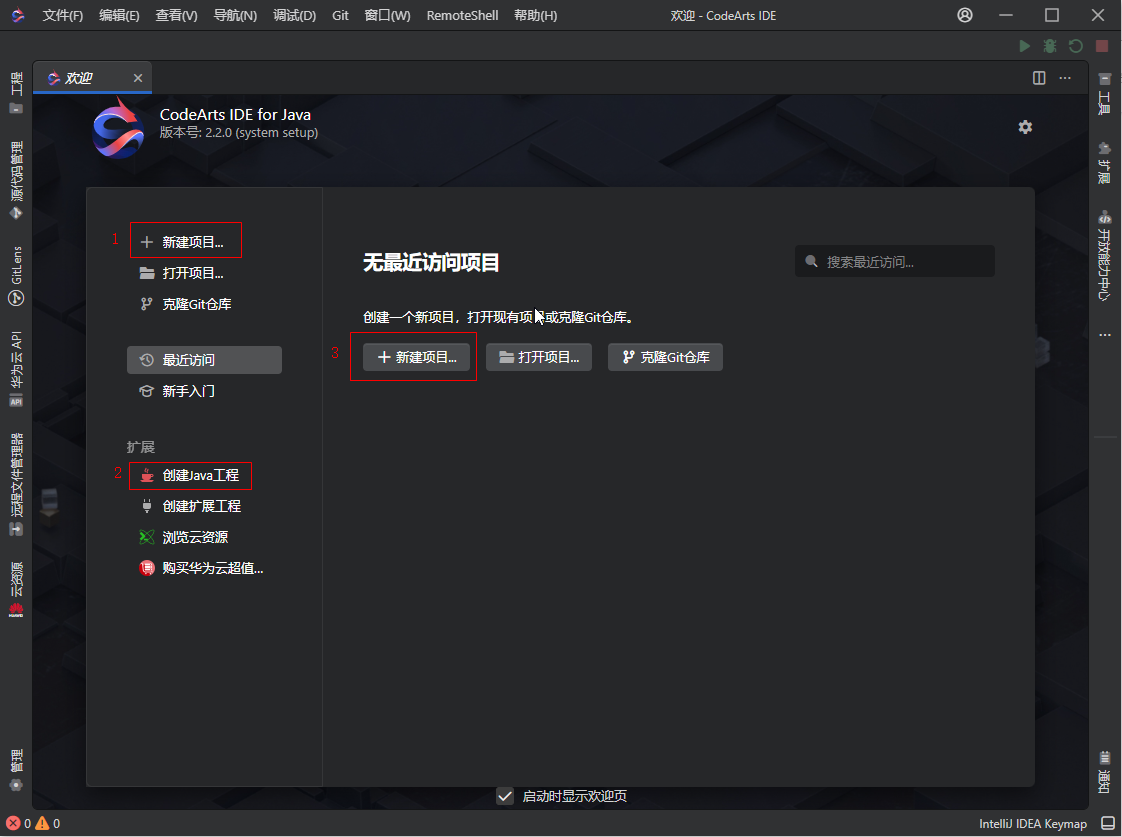
3. 使用快捷键“Alt+P”快速唤出新建工程界面。
- 如果在新窗口创建工程(未打开任何工程),工程创建成功后会直接在当前窗口打开;如果已经打开了一个工程,并在当前窗口通过新建工程向导创建新工程,创建成功的提示弹窗中,点击→当前窗口,工程在当前窗口打开。点击→新窗口,CodeArts IDE将打开新窗口并加载已创建的工程。
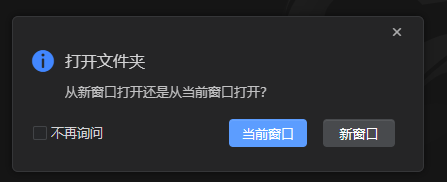
创建工程实例:
四、语言服务初始化与日志查看
- 加载项目时,Java语言服务会进行初始化,右下角状态栏以及消息通知弹窗会有语言服务初始化过程提示信息。语言服务初始化过程中会启动相关服务、下载依赖的Jar包及进行Indexing,此过程受计算机性能、网速等因素影响会耗费一定的时间。
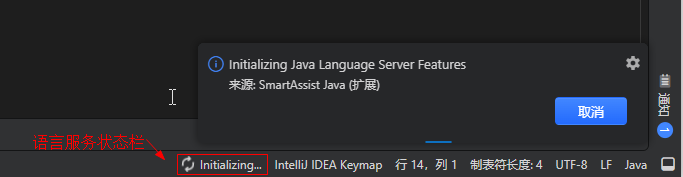
- 点击“输出”视图,切换“SmartAssist Java”,可查看更多语言服务初始化过程的日志:
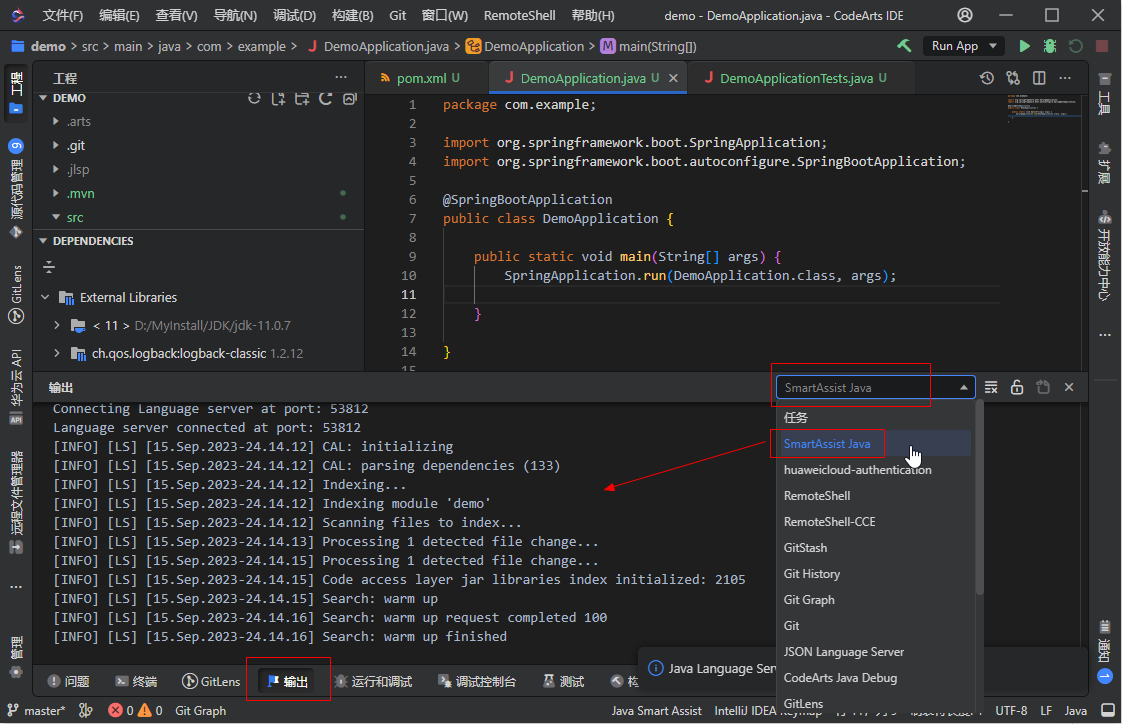
- 语言服务初始化完成之前,语言服务相关功能(如代码补全、代码重构、查看类型定义等)将不会有很好的体验,此时需耐心等待语言服务初始化完成。
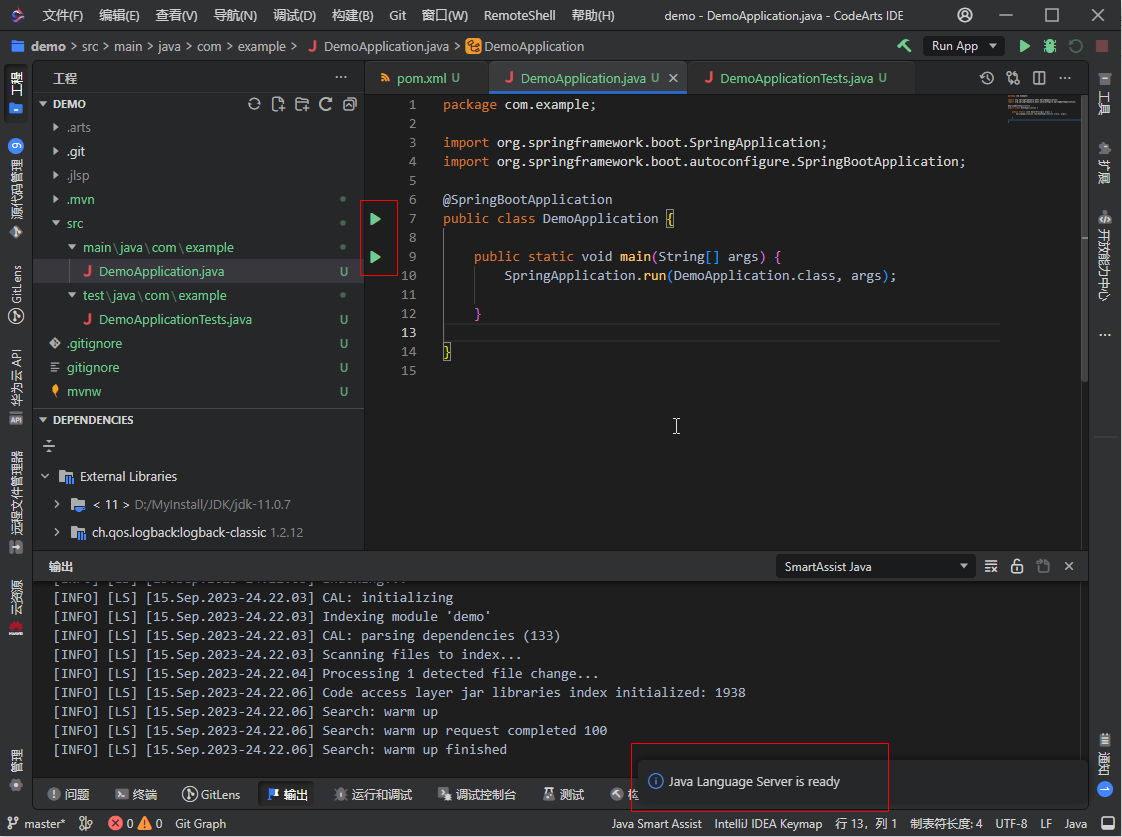
当右下角弹出提示“Java Language Server is ready”(Java语言服务已就绪)时(见下图),说明语言服务已初始化完毕,此时可执行文件类和main方法会出现运行按钮,我们就可以开始正常使用语言服务的全部功能。
五、代码补全
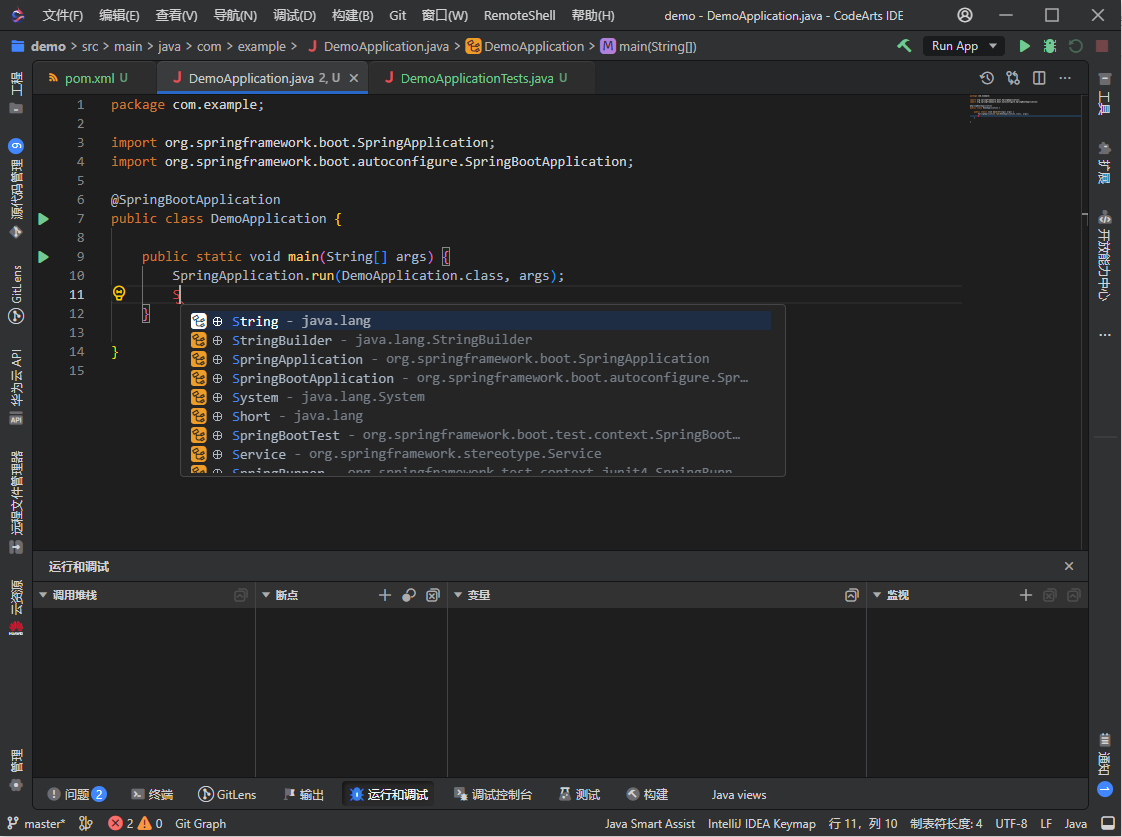
语言服务初始化完成后,即可使用代码补全功能。代码补全列表中包含语言服务的补全及强大的AI智能补全(带有⊕图标),见下图:
六、代码运行调试
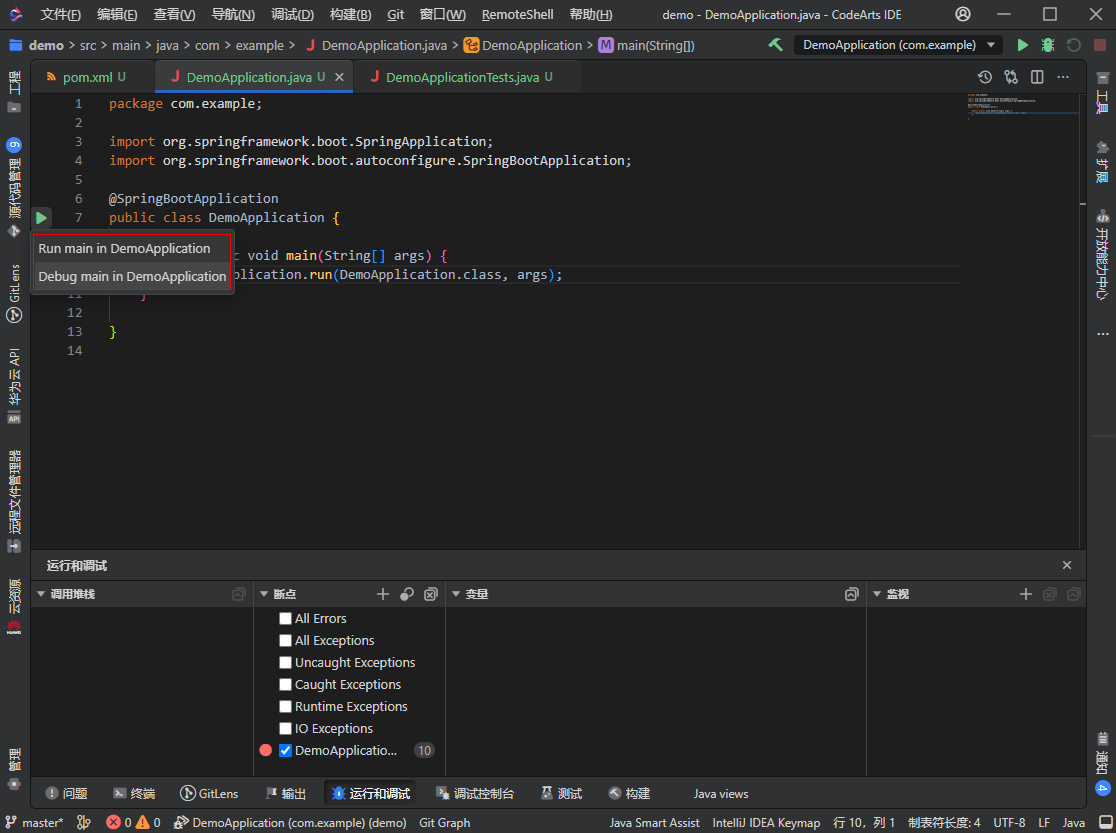
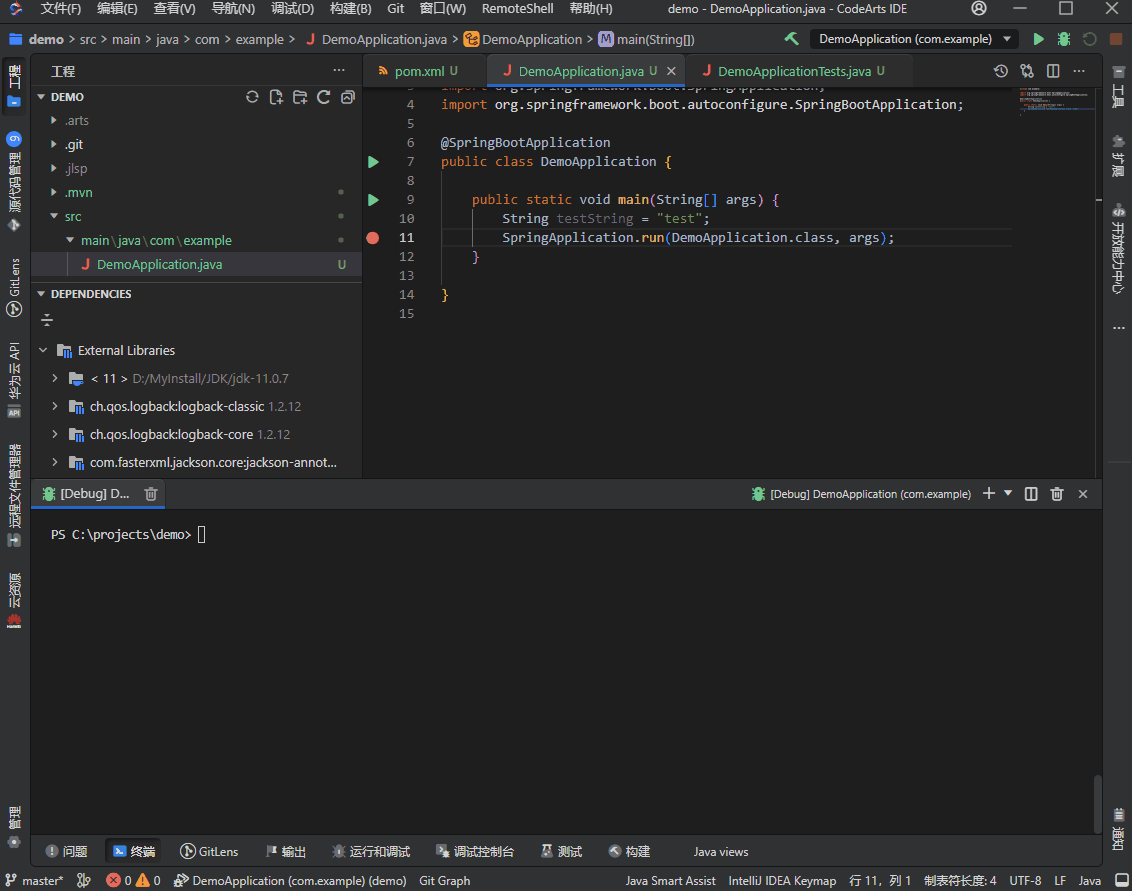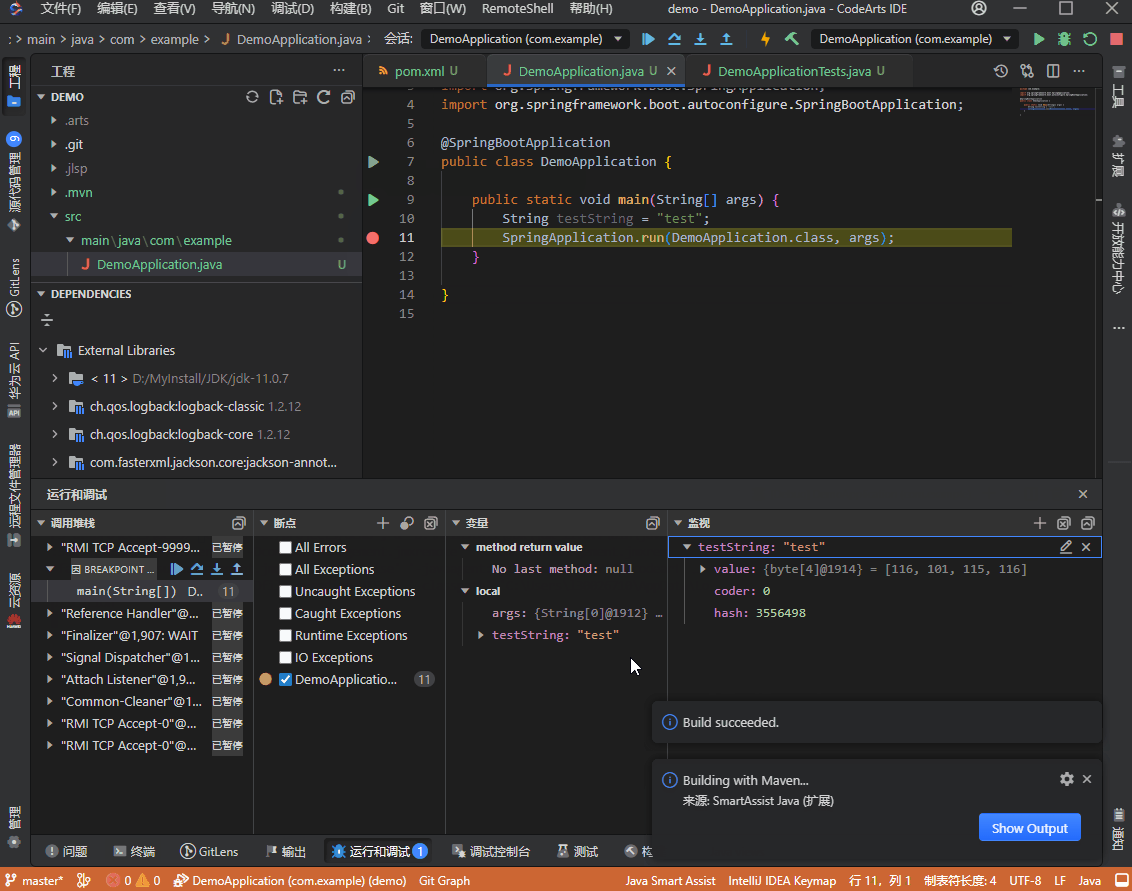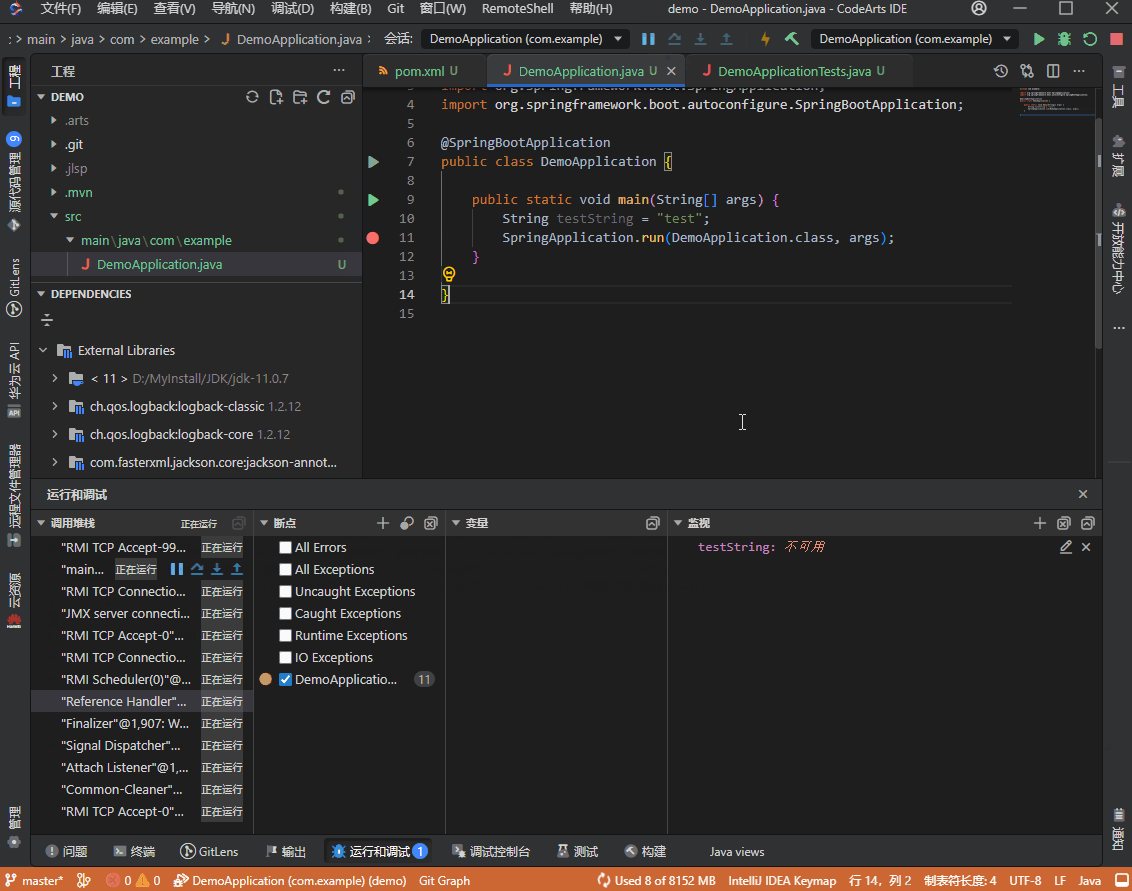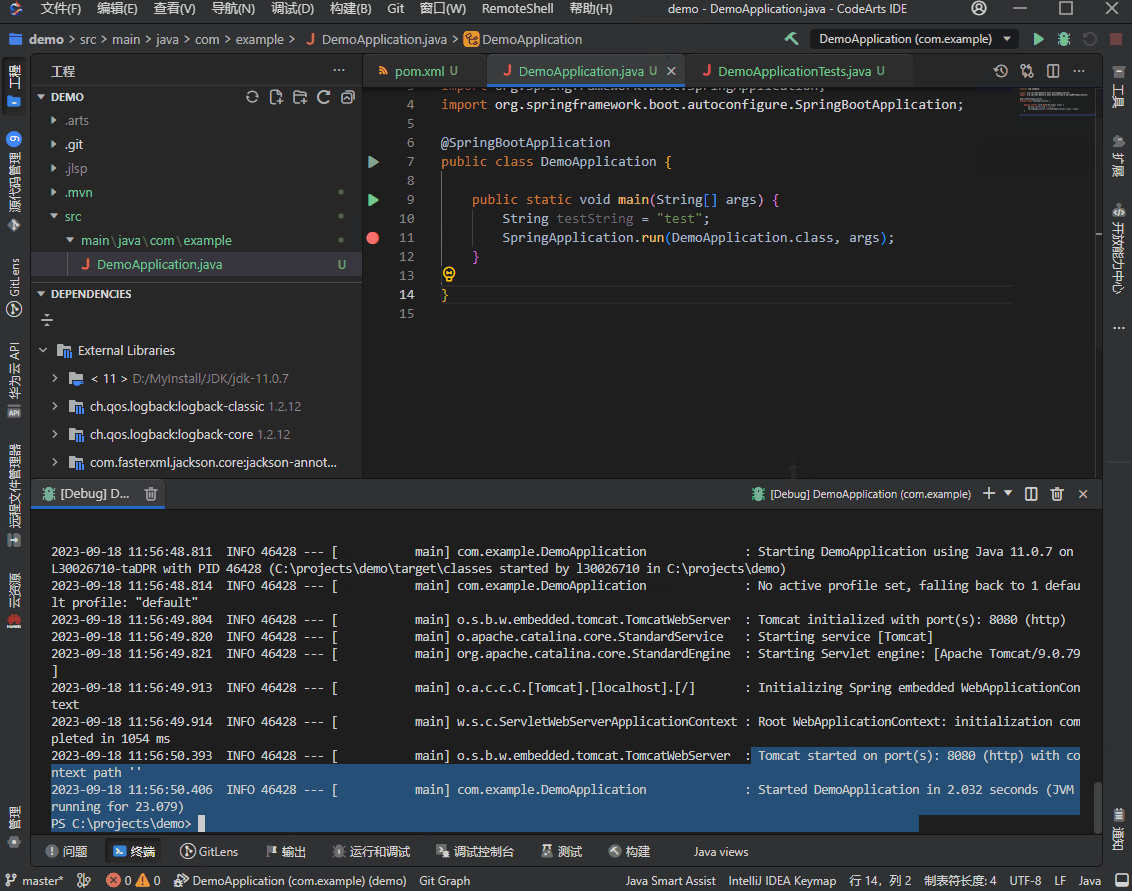
- 语言服务初始化完成后,在可运行的文件左侧会显示运行图标,选择“Run main in DemoApplication”即可开始运行,选择“Debug main in DemoApplication”即可开始调试,终端视图中将会显示调试运行的信息。
-
也可以点击右上角的运行按钮和调试按钮分别发起运行和调试。
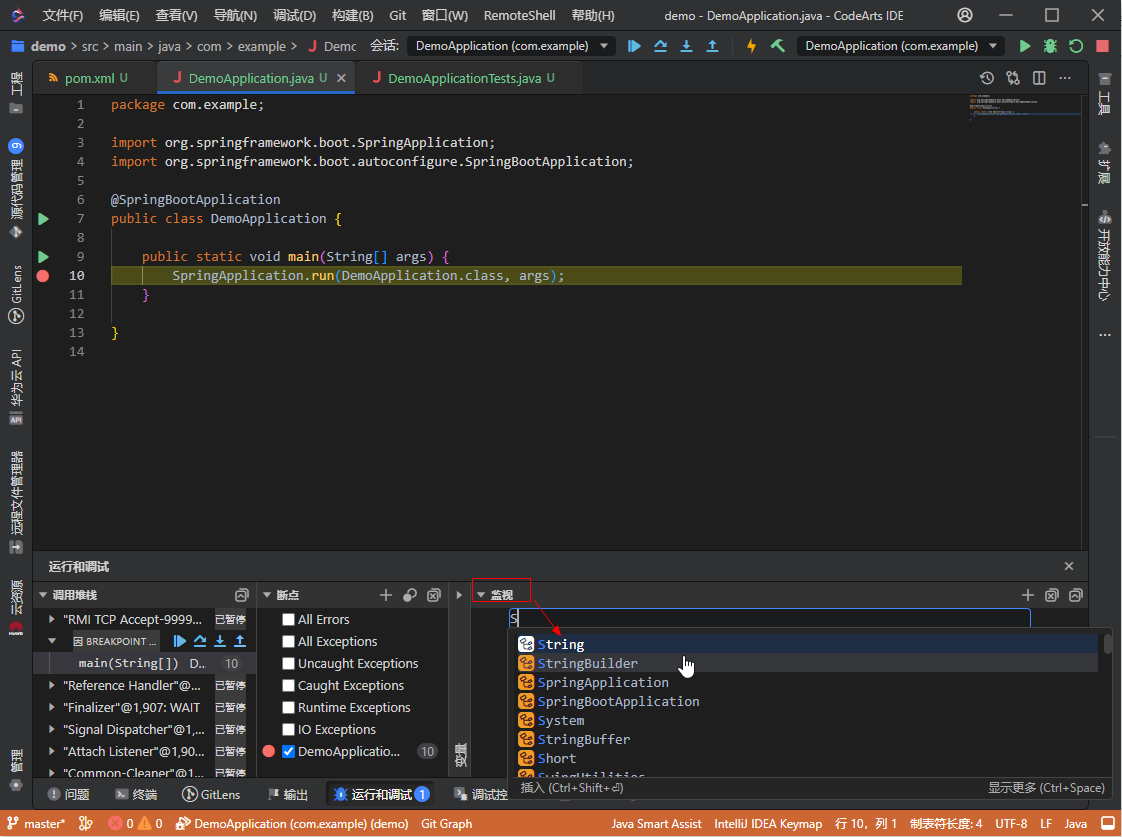
- 可在代码左侧设置断点,Debug进入断点后,可在底部运行调试视图中查看调试相关信息(变量、监视、调用堆栈),也可以对断点进行管理。
- 监视视图和变量视图在调试发起进入断点后,同样支持代码补全能力。
运行调试实例:
七、构建工程
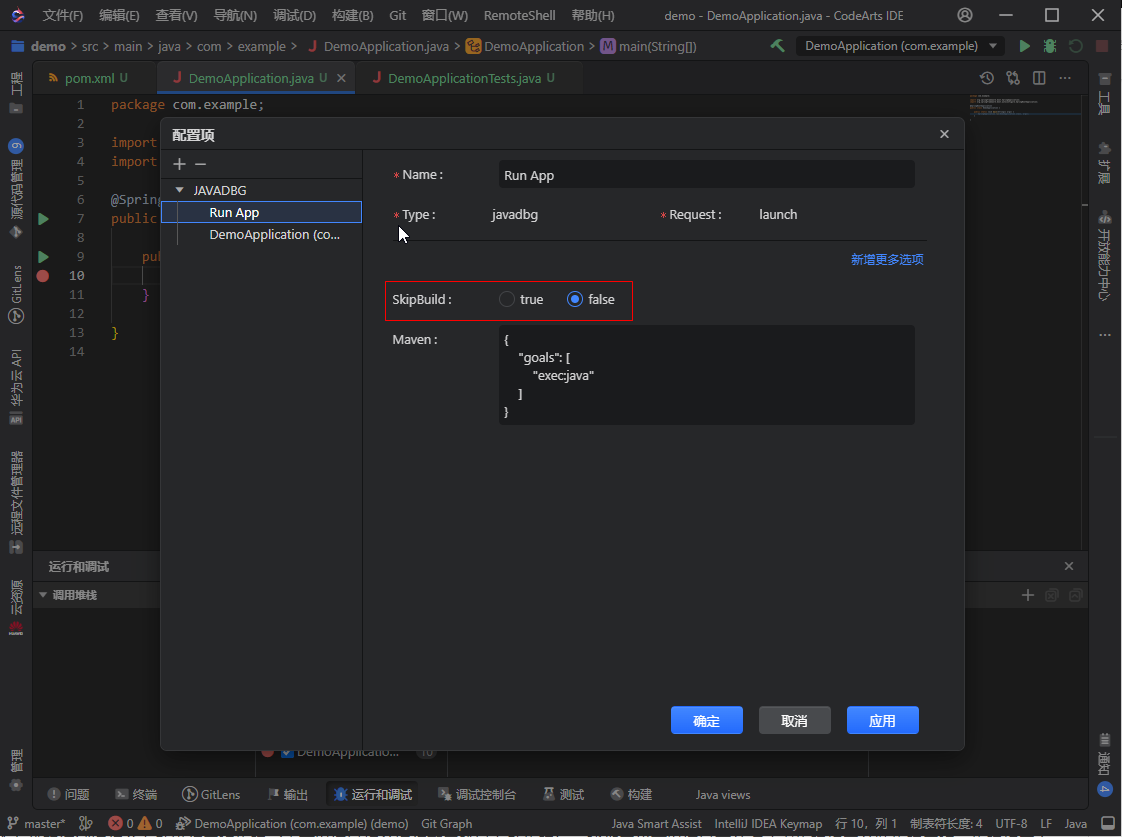
- 华为云CodeArts IDE for Java会在代码调试运行前自动进行工程构建,也可以通过修改相关运行配置跳过自动构建,见下图:
(备注:“SkipBuild”选项默认为false,当设置为true时,发起调试可以跳过构建直接调试,适用于已构建出产物、且代码没有其他修改的情形,可提升调试运行的速度。)
- 我们可以通过点击相关构建菜单主动触发构建工程,“构建”视图右半部分将显示构建过程的相关信息。
构建菜单入口如下:
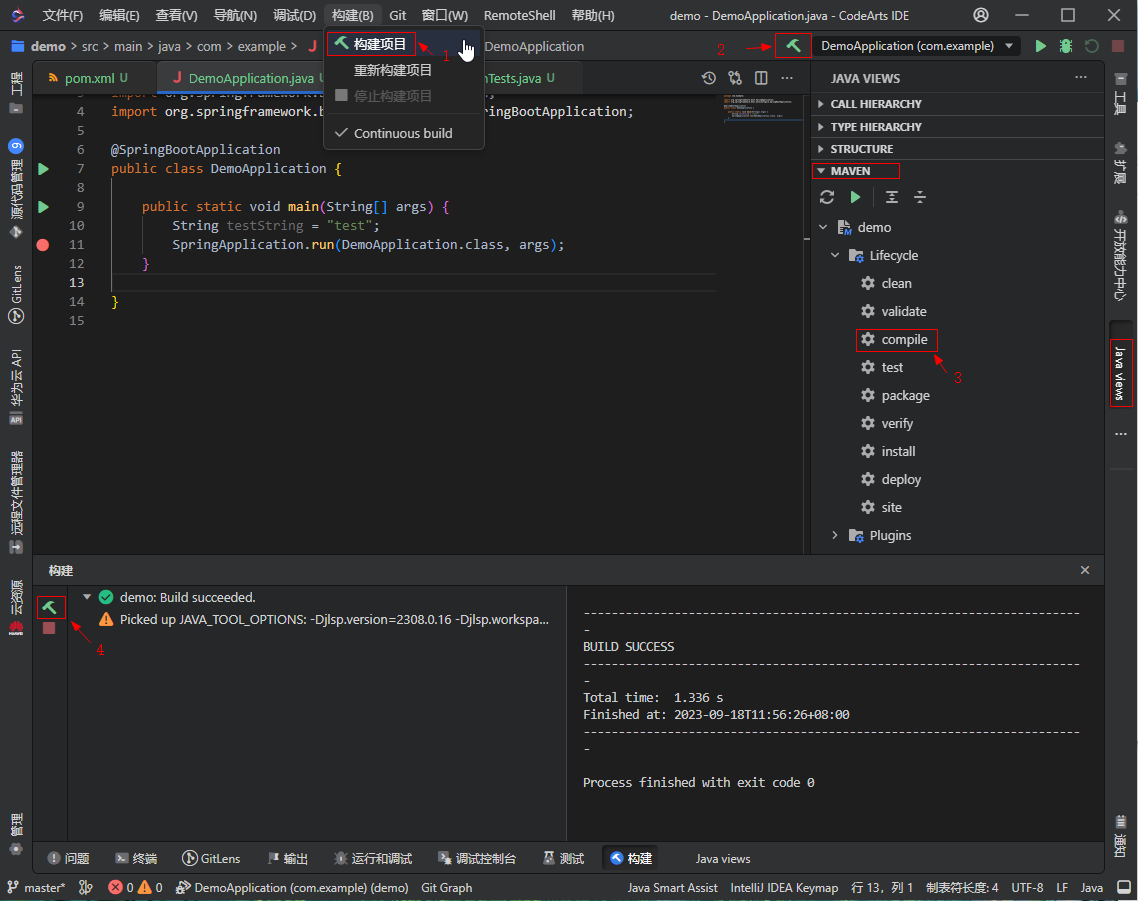
还可在构建视图的左侧视图中通过鼠标右键唤出构建菜单:
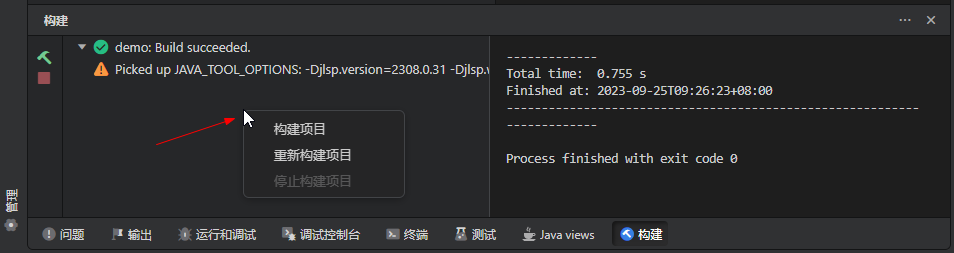
构建工程实例:
八、运行单元测试用例
华为云CodeArts IDE for Java在编辑器左侧栏和底部测试视图提供单元测试运行功能。
- 运行当前文件所有测试用例,请点击类名所在行的左侧绿色按钮,或者鼠标右键此按钮并选择“运行测试”。
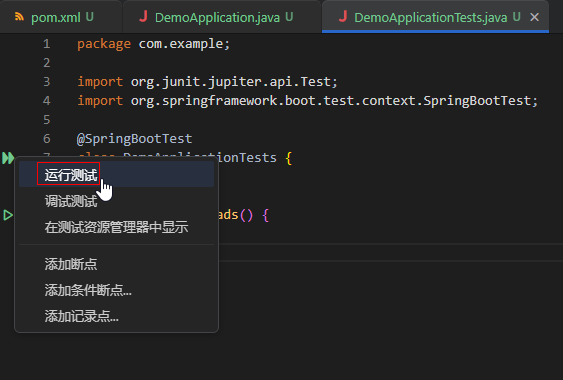
底部栏自动打开测试视图,展示当前运行所有用例的状态,右侧输出运行日志。

-
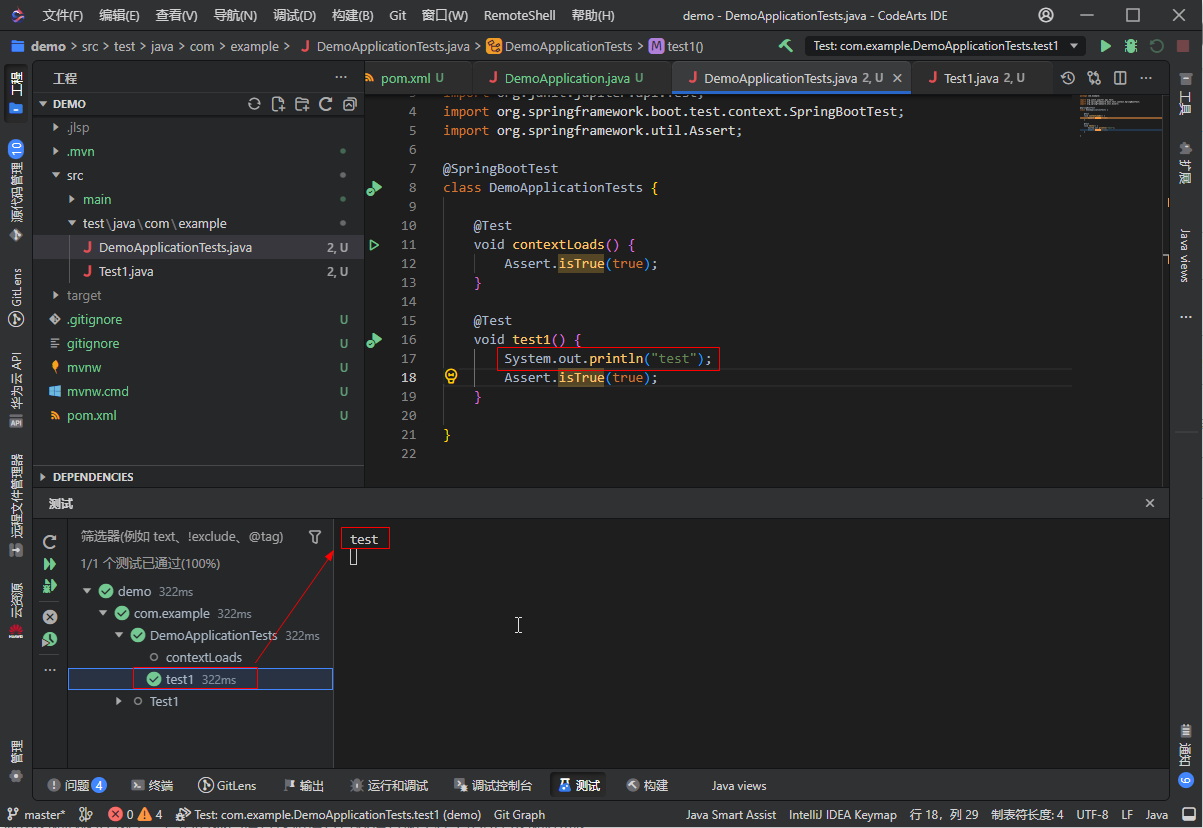
运行当前单个测试用例,请点击测试用例所在行的左侧绿色按钮,或者鼠标右键此按钮并选择“运行测试”,测试视图将展示当前运行的测试用例,点击测试用例后右侧可查看该测试用例的相关运行输出。
-
在测试视图的包名、类名或者方法名上,可以运行该包下、该类下或者某个具体的测试用例,鼠标悬停上去后会显示相关的运行调试按钮,点击后即可发起运行或调试。
-
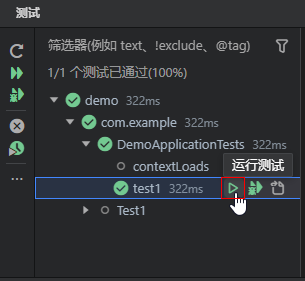
点击测试视图左侧工具栏的的绿色运行按钮运行可以运行此工程下的所有测试用例。
-
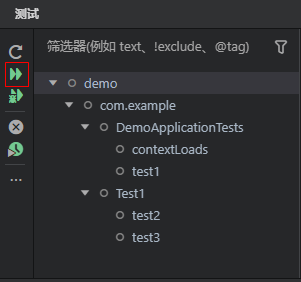
单击或者右键测试视图左侧工具栏的“视图和更多操作”按钮,可以展开更多测试视图相关的操作。如清除所有结果、排序查看、切换树形或列表查看等等。
-
点击清除所有结果,可以清除当前已运行的所有测试用例的结果,相关图标恢复未执行用例前的状态。
运行单元测试用例实例:
九、Java相关设置
CodeArts IDE for Java为Java相关的设置提供了单独的设置入口,点击编辑器左下角的“管理->Java助手设置”菜单可以唤出Java的设置界面:
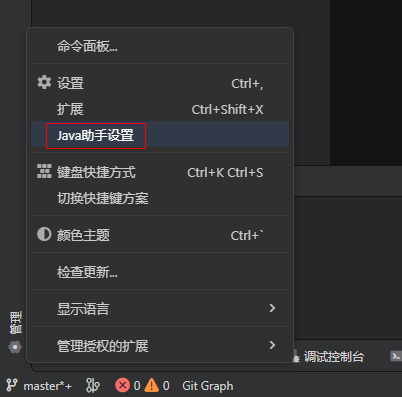
在这个设置界面中,你可以设置工程的SDK、语言级别,Maven、Gradle相关的构建工具的设置以及代码formatter规则设置等等:
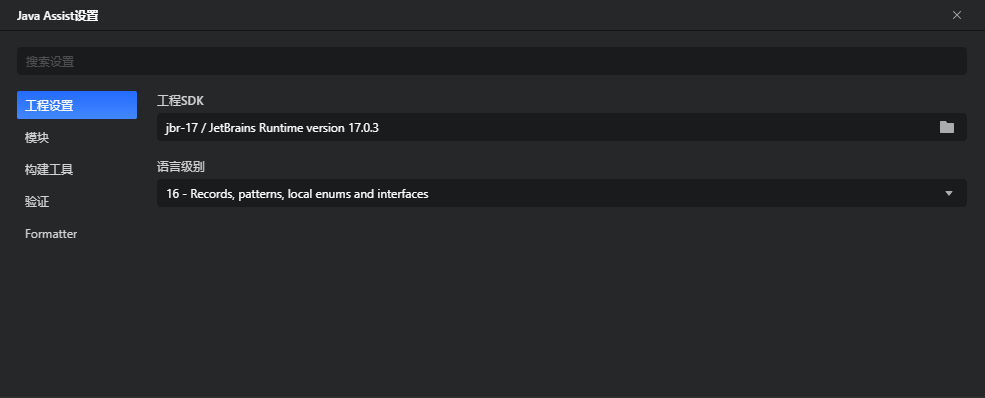
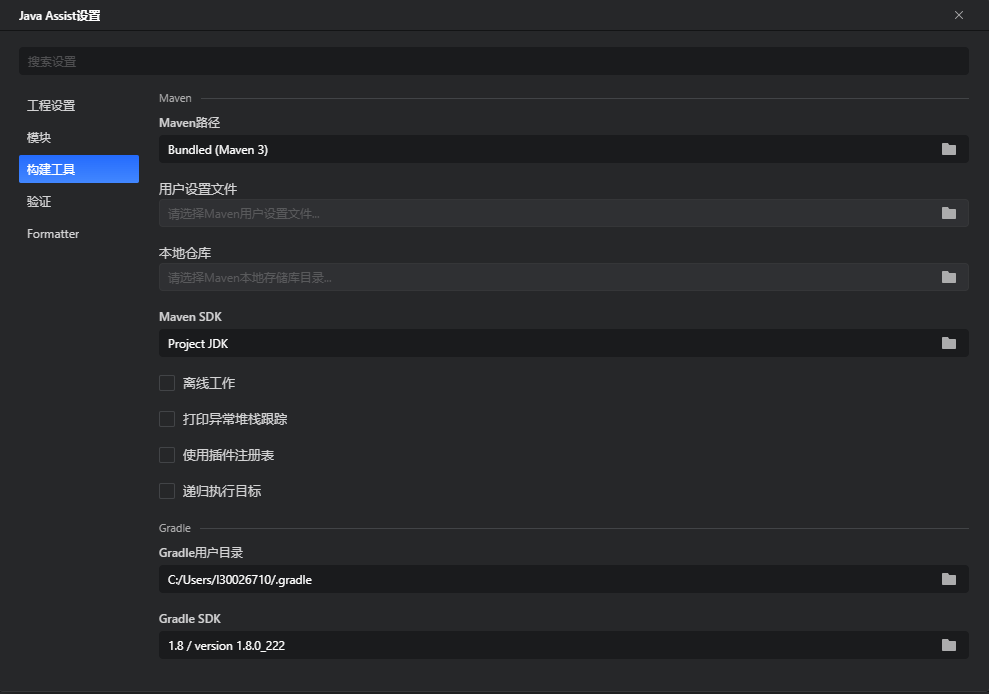
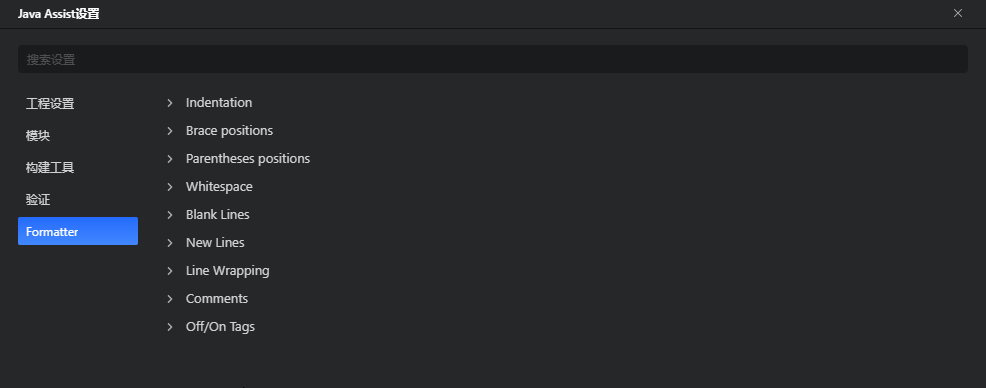
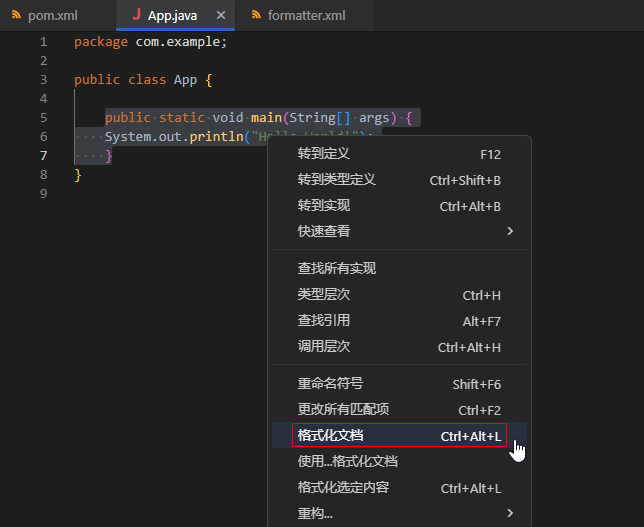
十、代码formatter规则设置说明
CodeArts IDE for Java支持自定义代码formatter规则的校验,暂不支持formatter规则的一键导入和导出(后续会支持)。
formatter规则设置好后,在编辑器中选中需要格式化的代码,通过右键唤出“格式化文档”的菜单(或者使用快捷键“Ctrl+Alt+L”)来格式化选中的代码: