网站做收录要多少长时间珠海网站建设策略
public class Test {/*** 谓类的方法就是指类中用static 修饰的方法(非static 为实例方法),比如main 方法,那么可以以main* 方法为例,可直接调用其他类方法,必须通过实例调用实例方法,this 关键字不是这么用的*** Java数据库连接库JDBC用到哪种设计模式?* 桥接模式**下面关于静态方法说明正确的是 在静态方法中调用本类的静态方法时可直接调用*静态方法中没有this关键词,因为静态方法是和类同时被加载的,而this是随着对象的创建存在的,静态比对象优先存在**下面哪些类可以被继承? Java.lang.Thread、java.lang.Number、java.lang.Double、java.lang.Math、 java.lang.ClassLoader* Thread可以被继承,用于创建新的线程* B,Number类可以被继承,* Integer,Float,Double等都继承自Number类* C,Double类的声明为* public final class Doubleextends Numberimplements Comparable<Double>* final生明的类不能被继承* D,Math类的声明为 public final class Mathextends Object* 不能被继承* E,ClassLoader可以被继承,用户可以自定义类加载器***** java.lang包中不能被继承的类:** public final class Byte** public final class Character** public static final class Character.UnicodeBlock** public final class Class<T>** public final class Compile** public final class Double** public final class Float** public final class Integer** public final class Long** public final class Math** public final class ProcessBuilder** public final class RuntimePermission** public final class Short** public final class StackTraceElement** public final class StrictMath** public final class String** public final class StringBuffer** public final class StringBuilder** public final class System** public final class Void* @param args*/public static void main(String[] args) {String a = new String("A");String b = new String("B");System.out.println("a"+System.identityHashCode(a));//地址System.out.println("b"+System.identityHashCode(b));//地址
// System.out.println(b+"");oper(a,b);//x,y是a,b的副本,x.append(y)使得AB在一起,// 而y=x后,y指向AB,方法结束后x,y消亡,故a-AB,b-B;System.out.println("a"+System.identityHashCode(a));//地址System.out.println("b"+System.identityHashCode(b));//地址System.out.println(a+","+b);}public static void oper(String x,String y){System.out.println("x"+System.identityHashCode(x));//地址System.out.println("y"+System.identityHashCode(y));//地址
// x.append(y);x = x+y;y = x;System.out.println("x"+System.identityHashCode(x));//地址System.out.println("y"+System.identityHashCode(y));//地址}
}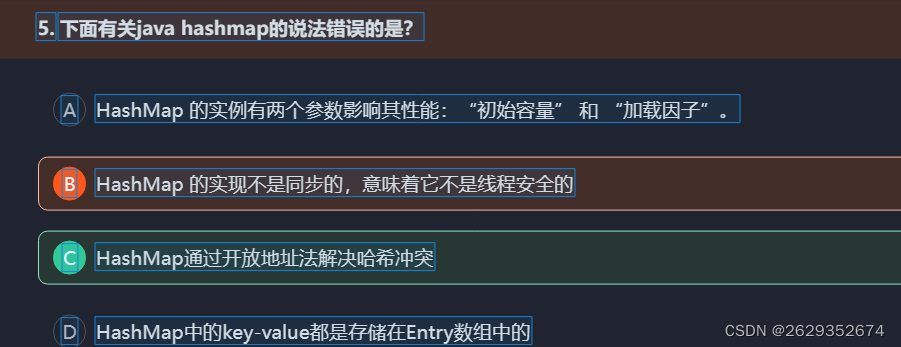
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的
hash采用拉链法解决冲突,hashmap ,Hashtable采用拉链法解决冲突


public A foo(B b){return b;}
重写 要求两同两小一大原则, 方法名相同,参数类型相同,子类返回类型小于等于父类方法返回类型, 子类抛出异常小于等于父类方法抛出异常, 子类访问权限大于等于父类方法访问权限。[注意:这里的返回类型必须要在有继承关系的前提下比较]
重载 方法名必须相同,参数类型必须不同,包括但不限于一项,参数数目,参数类型,参数顺序
再来说说这道题 A B 都是方法名和参数相同,是重写,但是返回类型没与父类返回类型有继承关系,错误 D 返回一个类错误 c的参数类型与父类不同,所以不是重写,可以理解为广义上的重载访问权限小于父类,都会显示错误
虽然题目没点明一定要重载或者重写,但是当你的方法名与参数类型与父类相同时,已经是重写了,这时候如果返回类型或者异常类型比父类大,或者访问权限比父类小都会编译错误

中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源。中间件位于客户机
服务器的操作系统之上,管理计算机资源和网络通讯。是连接两个独立应用程序或独立系统的软件。相连接的系统,即使它们具有不同的接口,但通过中间件相互之间仍能交换信息。执行中间件的一个关键途径是信息传递。通过中间件,应用程序可以工作于多平台或OS环境。
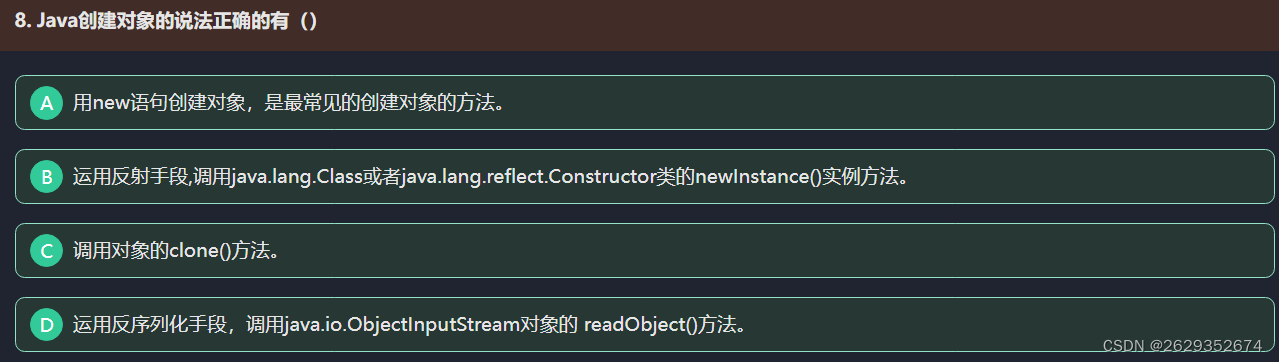
1.new
2.对象克隆clone()方法
3.反射Constructor类的newInstance()方法
4.反射的Class类的newInstance()方法
5.反序列化的readObject()方法
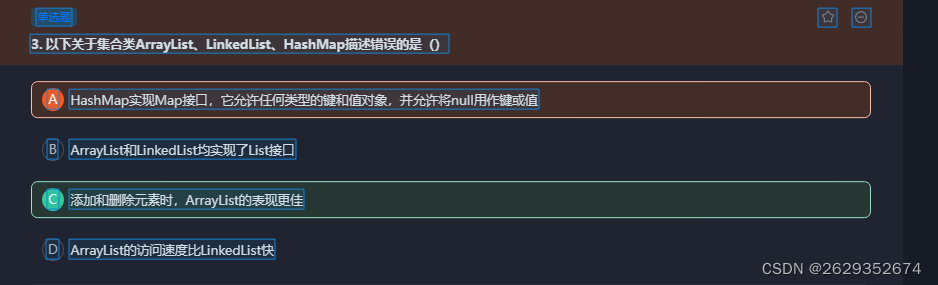
ArrayList的实现是基于数组,LinkedList的实现是基于双向链表。对于随机访问ArrayList要优于LinkedList,ArrayList可以根据下标以O(1)时间复杂度对元素进行随机访问,而LinkedList的每一个元素都依靠地址指针和它后一个元素连接在一起,查找某个元素的时间复杂度是O(N)。对于插入和删除操作,LinkedList要优于ArrayList因为当元素被添加到LinkedList任意位置的时候,不需要像ArrayList那样重新计算大小或者是更新索引。因此选项C错误。
-
List 是一个有序集合,可以存放重复的数据 (有序:存进是什么顺序,取出时还是什么顺序)
(1).ArrayList 底层是数组适合查询,不适合增删元素。
(2).LiskedList 底层是双向链表适合增删元素,不适合查询操作。
(3).Vector 底层和ArrayList相同,但是Vector是线程安全的,效率较低很少使用 -
Set 是一个无序集合,不允许放重复的数据 (无序不可重复,存进和取出的顺序不一样)
(1).HashSet 底层是哈希表/散列表
(2).TreeSet 继承sartedSet接口(无需不可重复,但存进去的元素可以按照元素的大小自动排序) -
Map 是一个无序集合,以键值对的方式存放数据,键对象不允许重复,值对象可以重复。
(1).HashMap实现不同步,线程不安全。 HashTable线程安全 (2).HashMap中的key-value都是存储在Entry中的。 (3).HashMap可以存null键和null值,不保证元素的顺序恒久不变,它的底层使用的是数组和链表,通过hashCode()方法和equals方法保证键的唯一性
现在的jdk版本底层是数组➕红黑树
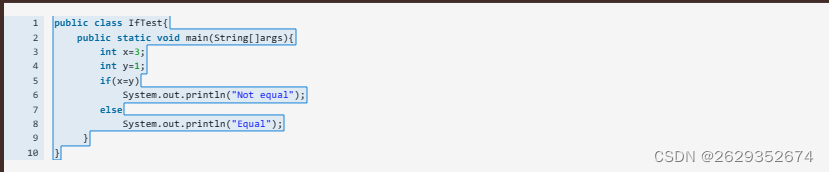
1、Java中,赋值是有返回值的
,赋什么值,就返回什么值。比如这题,x=y,返回y的值,所以括号里的值是1。
2、Java跟C的区别,C中赋值后会与0进行比较,如果大于0,就认为是true;而Java不会与0比较,而是直接把赋值后的结果放入括号。

main()函数即主函数,是一个前台线程,前台进程是程序中必须执行完成的,而后台线程则是java中所有前台结束后结束,不管有没有完成,后台线程主要用与内存分配等方面。
前台线程和后台线程的区别和联系:
1、后台线程不会阻止进程的终止。属于某个进程的所有前台线程都终止后,该进程就会被终止。所有剩余的后台线程都会停止且不会完成。
2、可以在任何时候将前台线程修改为后台线程,方式是设置Thread.IsBackground 属性。
3、不管是前台线程还是后台线程,如果线程内出现了异常,都会导致进程的终止。
4、托管线程池中的线程都是后台线程,使用new Thread方式创建的线程默认都是前台线程。
说明:
应用程序的主线程以及使用Thread构造的线程都默认为前台线程
使用Thread建立的线程默认情况下是前台线程,在进程中,只要有一个前台线程未退出,进程就不会终止。主线程就是一个前台线程。而后台线程不管线程是否结束,只要所有的前台线程都退出(包括正常退出和异常退出)后,进程就会自动终止。一般后台线程用于处理时间较短的任务,如在一个Web服务器中可以利用后台线程来处理客户端发过来的请求信息。而前台线程一般用于处理需要长时间等待的任务,如在Web服务器中的监听客户端请求的程序,或是定时对某些系统资源进行扫描的程序