seo网站关键词优化快速官网怎样申请企业邮箱账号
文章目录
- 前言
- 1. 服务器本机安装U8并调试设置
- 2. 用友U8借助cpolar实现企业远程办公
- 2.1 在被控端电脑上,点击开始菜单栏,打开设置——系统
- 2.2 找到远程桌面
- 2.3 启用远程桌面
- 3. 安装cpolar内网穿透
- 3.1 注册cpolar账号
- 3.2 下载cpolar客户端
- 4. 获取远程桌面公网地址
- 4.1 登录cpolar web ui管理界面
- 4.2 启动远程桌面隧道
- 4.3 获取远程桌面公网随机临时地址
- 5. 实现远程桌面控制
- 5.1 打开远程桌面客户端
- 5.2 使用cpolar所生成的公网tcp地址远程桌面
- 5.3 输入账号密码
- 5.4 远程访问用友U8,可随意进行账套的查看及修改
前言
搭建在公司或家里局域网内的如:财务软件、ERP、OA、CRM等电脑主机在没有公网地址的情况下是如何实现远程访问,在没有提供公网地址的,只能使用同账号同地域的公司或家里局域网之间内网连接,那我们想要从外部来远程访问财务软件要怎么办呢?
想要从外部远程访问公司或家里局域网内的财务软件,还有一种解决方案是使用远程访问工具。这些工具允许你通过互联网连接到远程主机,以便远程访问和操作财务软件。你可以选择使用[cpolar](cpolar - 安全的内网穿透工具)来实现远程访问。
1. 服务器本机安装U8并调试设置
在数据服务器上打开 :控制面板–管理工具–服务,找一下用友的数据库SQLSERVER(实例名) 是否是自动启动的。如果没有自动启动,右键设为“自动启动”。建议把各种杀毒软件关闭掉。可能是杀毒软件引起无法自动启动的。
U8是面向大中型企业应用的,所以系统环境要求高一些。
系统环境问题,可能是安装文件释放时没有按注册表路径。
1、打开安装程序,双击安装程序
2、开始安装,按提示操作,下一步
3、同意协议后,点击下一步
4、按提示操作,下一步
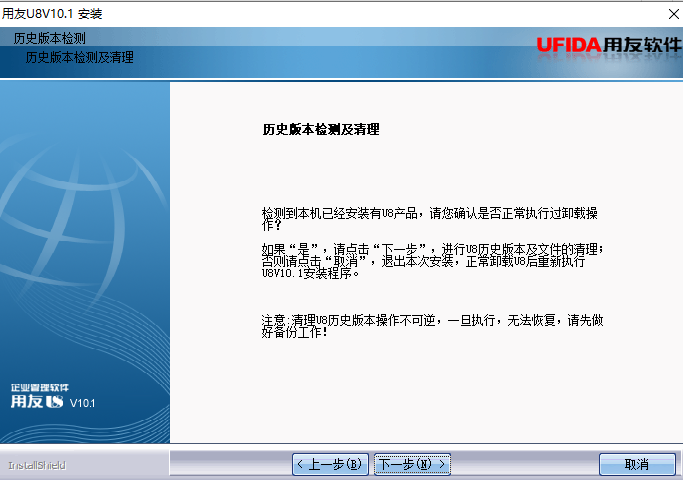
5、更改安装路径,下一步(备注:安装在非系统盘下,以免重做系统是把数据删除)
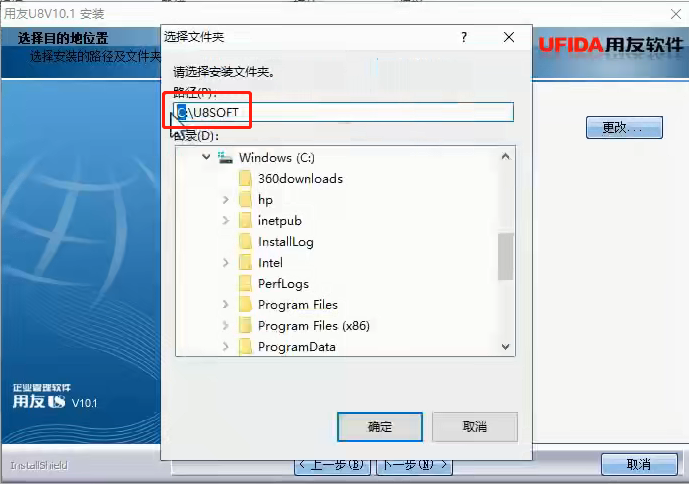
6、选择安装类型,如果是服务器,就安装全产品;客户端则选择客户端(绝大部分都是客户端,服务器在软件部署一般用友工程师和企业IT会安装好,普通企业员工平时选客户端安装即可)点击“下一步”
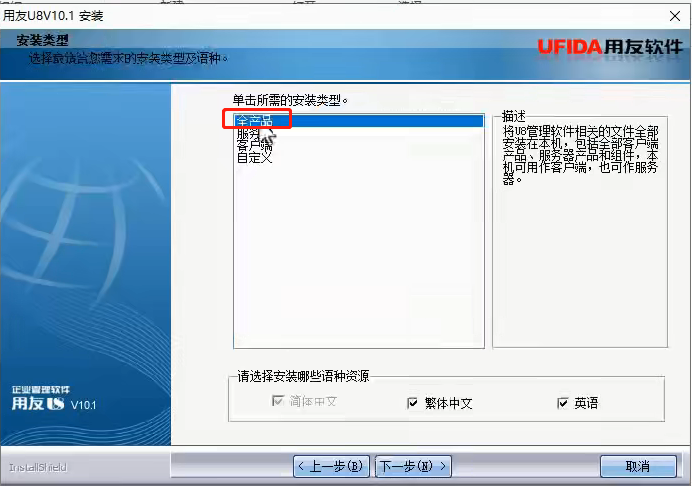
7、检测系统所需安装的组件
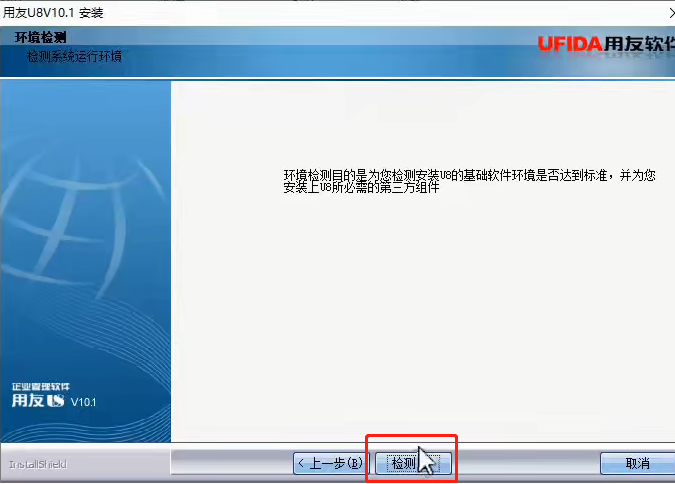
8、基础环境和缺省组件是必须安装的,红色的是当前系统缺少的组件,双击路径,会弹出 安装文件,双击安装就行
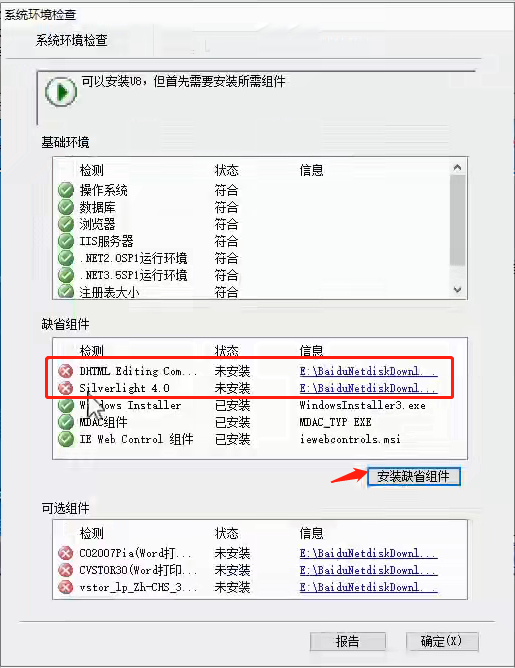
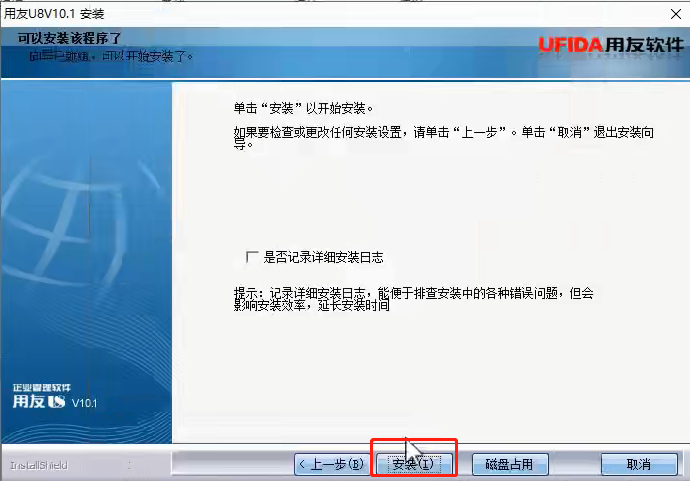
9、检测通过后,确定进行最终的安装界面,安装即可,等待程序安装(最好不勾选记录详细安装日志,这样安装会快点)
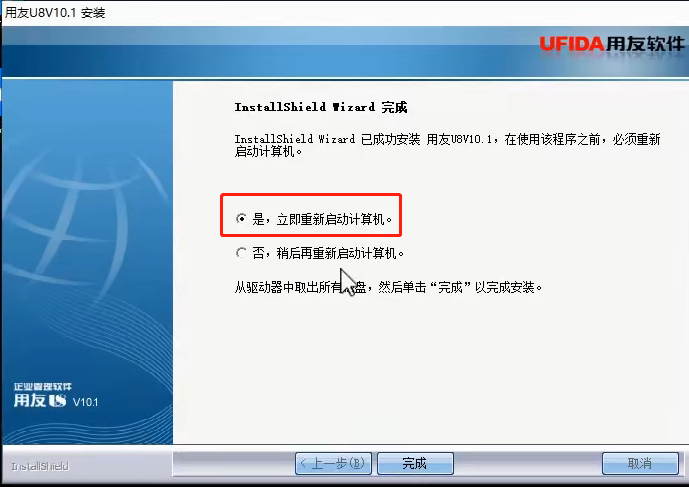
10、安装完成后,重新启动电脑
11、输入数据库名称和刚才设置的SA口令,点击测试连接

2. 用友U8借助cpolar实现企业远程办公
2.1 在被控端电脑上,点击开始菜单栏,打开设置——系统
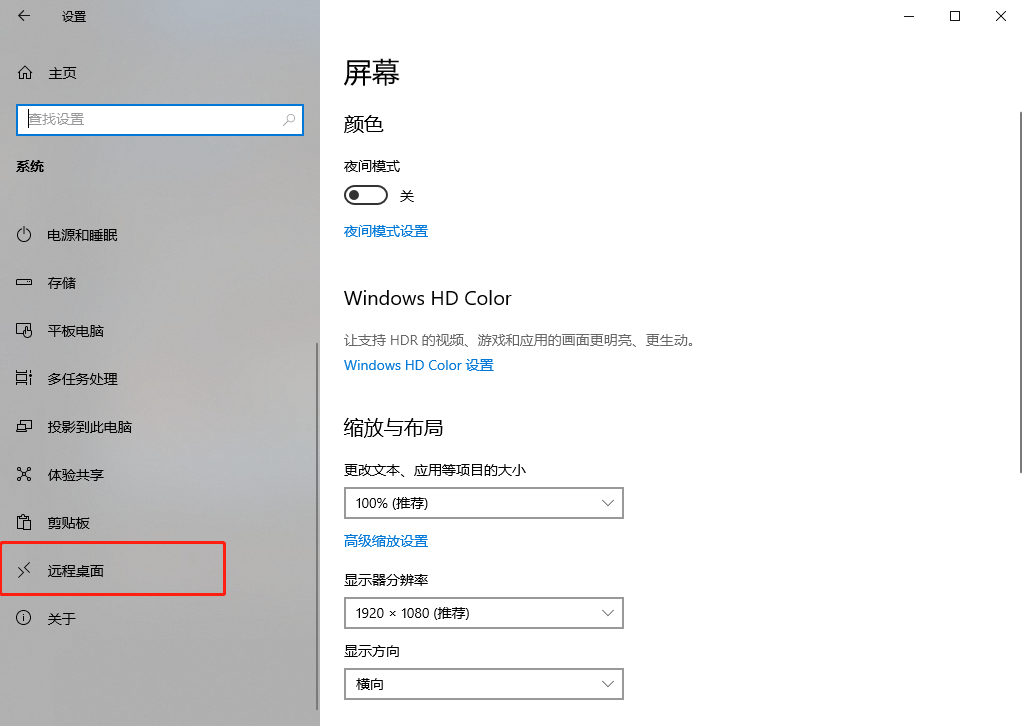
2.2 找到远程桌面
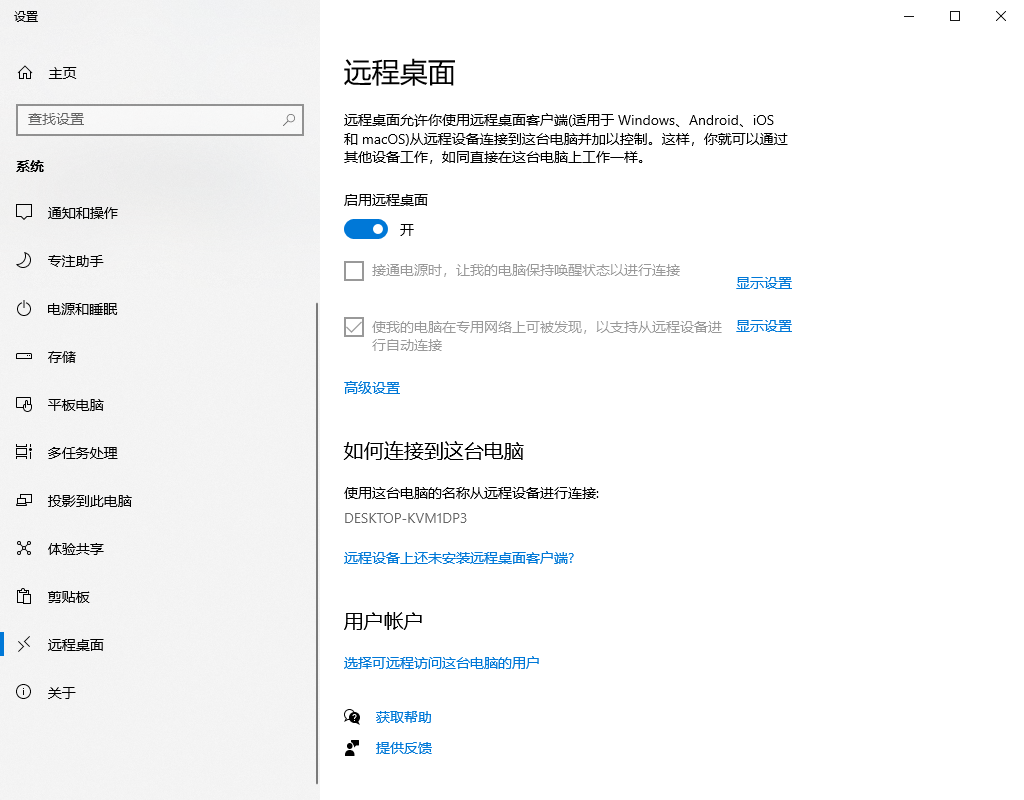
2.3 启用远程桌面
3. 安装cpolar内网穿透
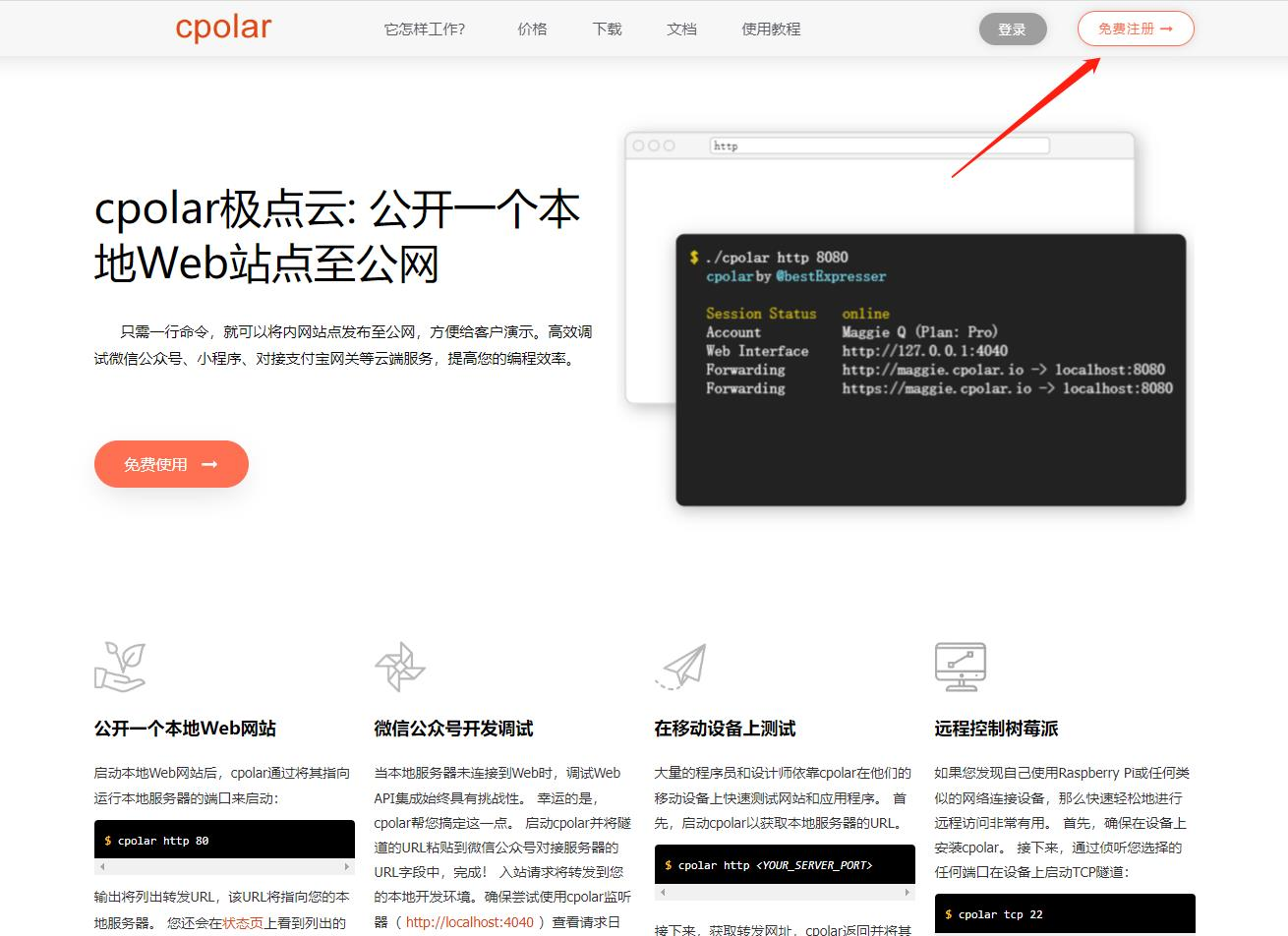
3.1 注册cpolar账号
进入cpolar官网,点击右上角的免费注册,使用邮箱免费注册一个cpolar账号并登录
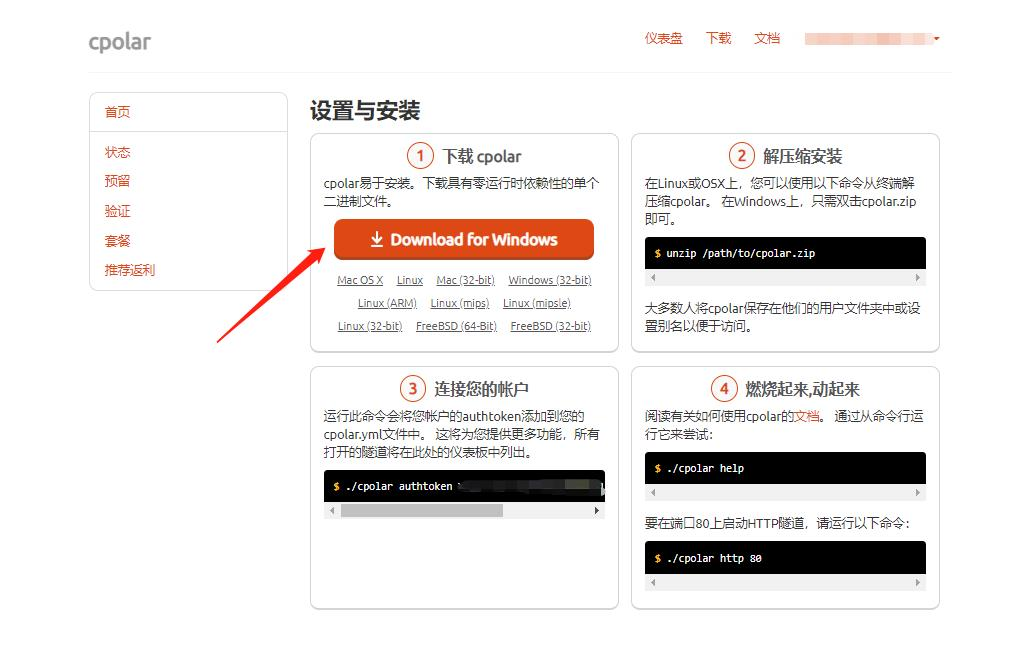
3.2 下载cpolar客户端
登录成功后,点击下载cpolar到本地并安装(一路默认安装即可)
cpolar安装成功后会默认安装两个样例隧道(可自行修改或删减):
- remoteDesktop:指向本地3389端口,tcp协议
- website:指向本地8080端口,http协议
本次我们可以直接使用remoteDesktop远程桌面隧道。
4. 获取远程桌面公网地址
4.1 登录cpolar web ui管理界面
在浏览器上访问127.0.0.1:9200,使用所注册的cpolar邮箱账号登录cpolar web ui管理界面(默认为本地9200端口)
4.2 启动远程桌面隧道
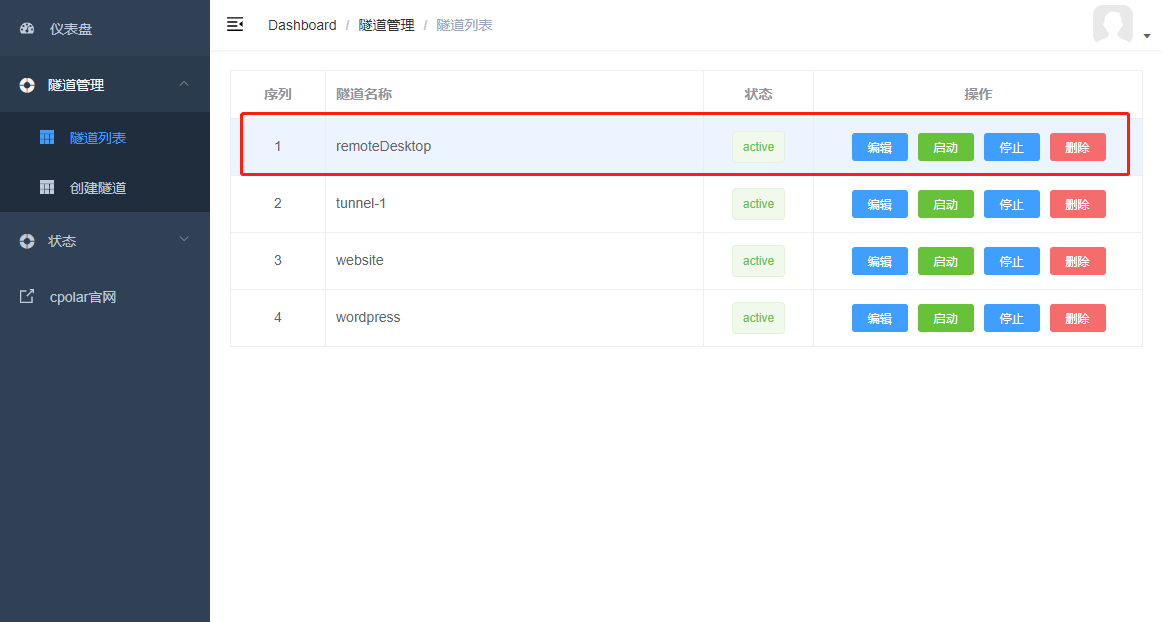
登录成功进入主界面后,我们点击左侧仪表盘的隧道管理——隧道列表,找到远程桌面隧道,并点击启动该隧道
4.3 获取远程桌面公网随机临时地址
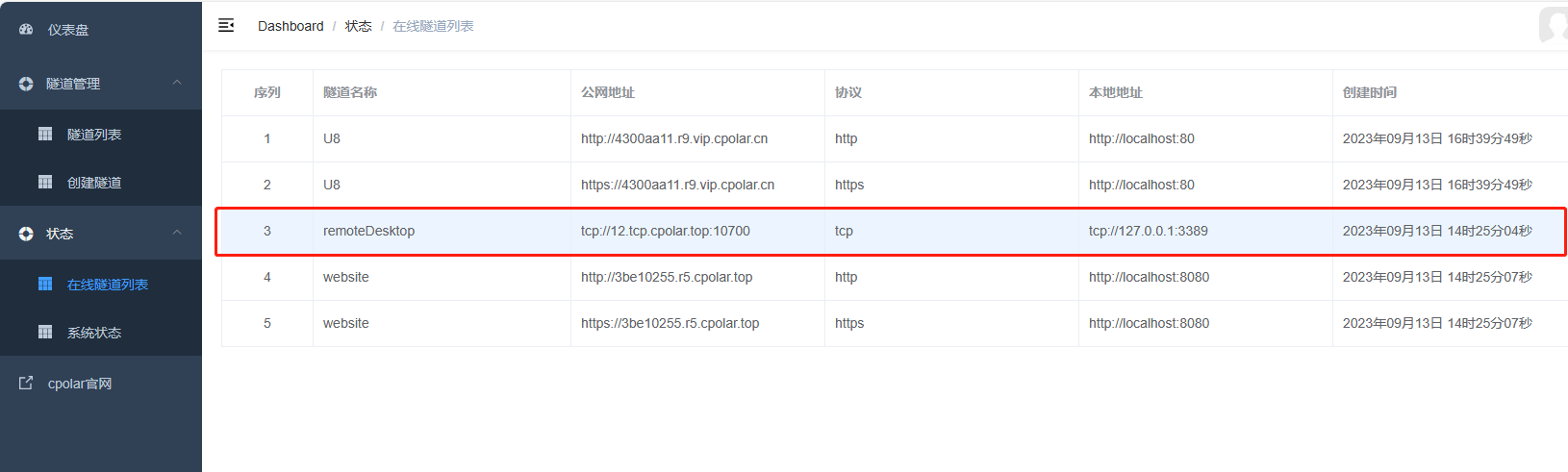
隧道启动成功后,我们点击左侧仪表盘的状态——在线隧道列表,可以看到远程桌面隧道已经有生成了相应的公网地址,我们将公网TCP端口地址复制下来(注意tcp://无需复制)。
由于以上使用cpolar所创建的隧道使用的是随机公网地址,24小时内会随机变化,不利于长期远程访问。因此我们可以为其配置二级子域名,该地址为固定地址,不会随机变化【ps:cpolar.cn已备案】
注意需要将cpolar套餐升级至基础套餐或以上,且每个套餐对应的带宽不一样。【cpolar.cn已备案】
5. 实现远程桌面控制
5.1 打开远程桌面客户端
在控制端电脑上,点击桌面左下角的搜索栏,搜索远程桌面连接,并打开
5.2 使用cpolar所生成的公网tcp地址远程桌面
在远程桌面连接窗口,在计算机栏位输入:您获取得到tcp随机隧道地址:(本例中: tcp://12.tcp.cpolar.top:10700,您的地址可能不同),如下图所示:
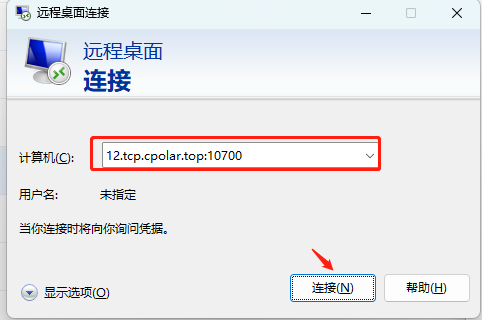
5.3 输入账号密码
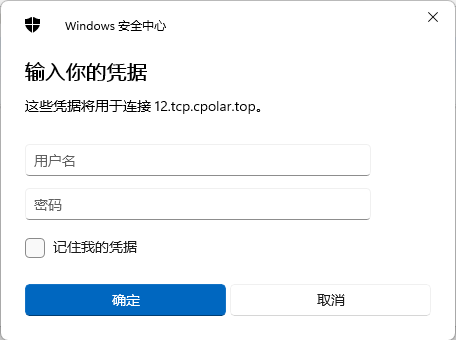
输入被控端电脑的账号及密码,即可远程桌面登录了。
注:您的账号需要是超级管理员权限,或者有远程桌面远程的账号,才能登录。如果您的PC机原来没有密码,请设置密码后,再远程桌面。安全第一。
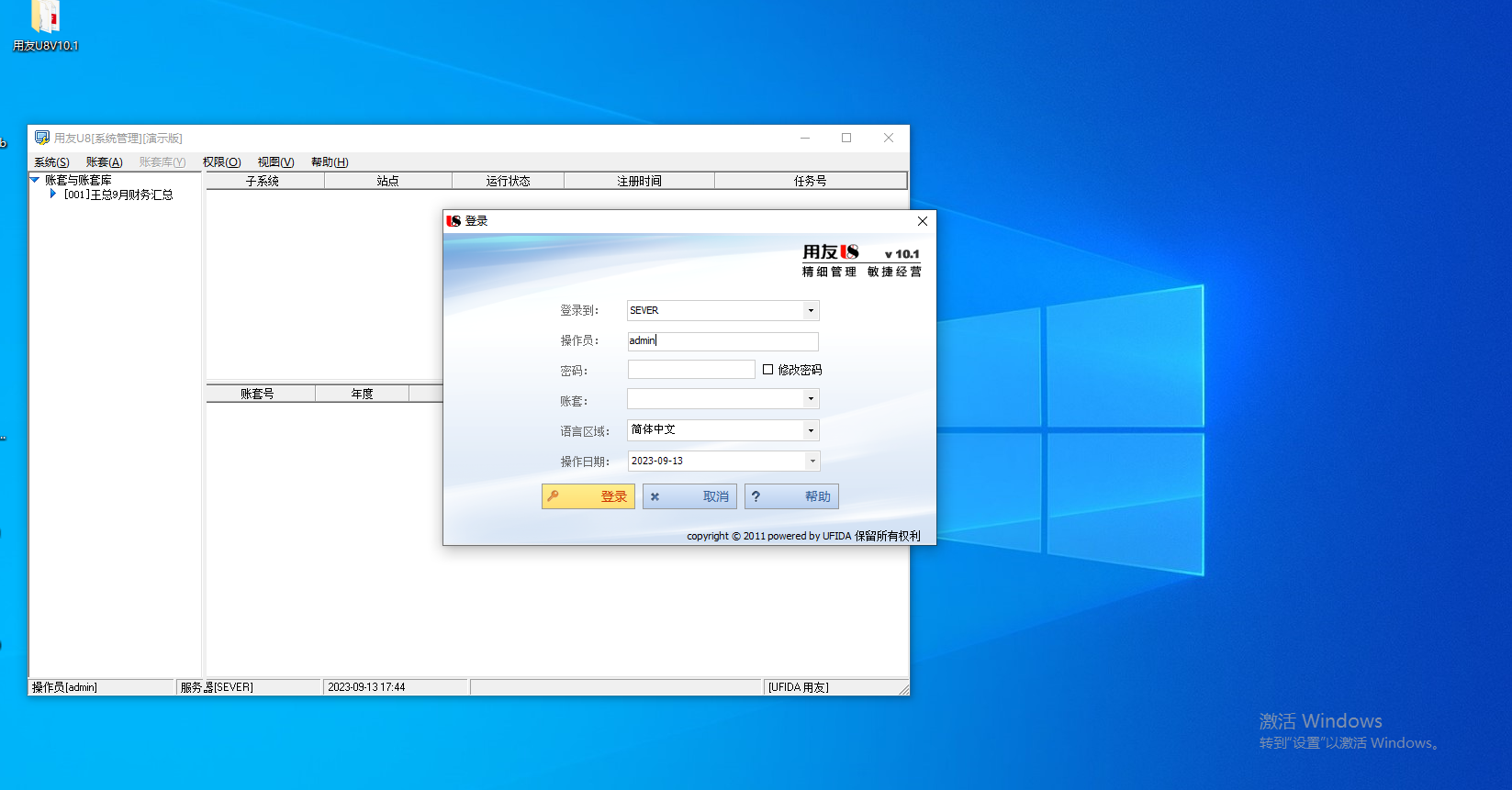
5.4 远程访问用友U8,可随意进行账套的查看及修改
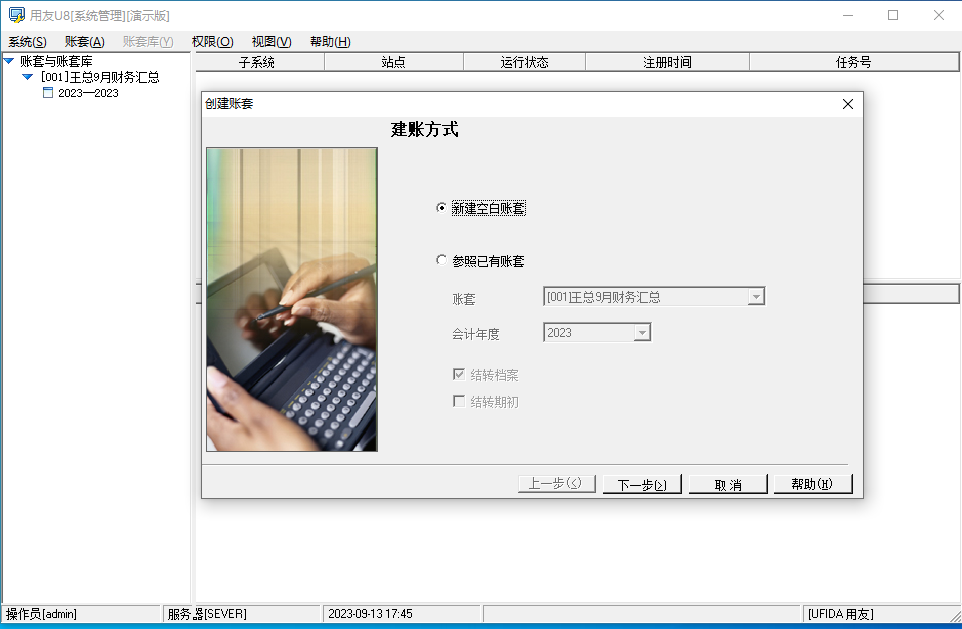
远程建立账套、修改账套
转载自cpolar极点云文章:U8用友ERP本地部署实现异地远程访问,随时随地查看公司账套!