淘宝刷单的网站建设建设网站的用途
大家好,我是HxShine。
今天分享一篇符尧大佬的一篇数据工程(Data Engineering)的文章,解释了speed of grokking指标是什么,分析了数据工程(data engineering)包括mix ratio(数据混合比例) + data format(数据格式) + data curriculum(数据课程)以及模型规模对speed of grokking的影响,同时用一个生动的随机数生成的例子讨论语言模型学习的本质,干货十足,分享给大家~
一、概述
Title:An Initial Exploration of Theoretical Support for Language Model Data Engineering. Part 1: Pretraining
文章地址:https://yaofu.notion.site/An-Initial-Exploration-of-Theoretical-Support-for-Language-Model-Data-Engineering-Part-1-Pretraini-dc480d9bf7ff4659afd8c9fb738086eb
1 Motivation
- 最近大模型开源社区研究热点开始从model engineering转移到data engineering,大家开始意识到数据质量的重要性。
- data engineering的理论还不太成熟,例如:好数据的准确定义是什么?,如何优化数据的结构组成?我们的优化目标是什么?
- 对data engineering进行理论分析可以帮助我们在正式跑实验前预测每个task最终的performance,openai在gpt4的技术报告中提到了这点,非常有意义。
2 Methods
本文不提出优化数据的具体方法,仅讨论数据工程(data engineering)时应该解决的问题是什么,以及指导我们的基本原则。具体来说,我们讨论预训练和 SFT 数据优化的以下目标:
- 预训练阶段数据优化:找到最优的混合比例+数据格式+数据课程=>使学习速度最大化。
- 监督微调/指令阶段调整数据优化:寻找最小的query-response pairs(最小的训练数据)=>使用户偏好分布的覆盖范围最大。
3 Conclusion
- 解释了可能更好的衡量评估指标speed of grokking(获取某技能的速度)是什么,其可能更具有泛化性并且更贴近于特定的skill能力。
- 分析mix ratio(数据混合比例) + data format(数据格式) + data curriculum(数据课程?)以及模型规模对speed of grokking的影响。
- 讨论llm模型最终学习到的是什么,以及可能的一些更好衡量模型效果的metrics。
二、详细内容
1 预训练能力评估指标:speed of grokking(获取某技能的速度)
1.1 grokking是什么?
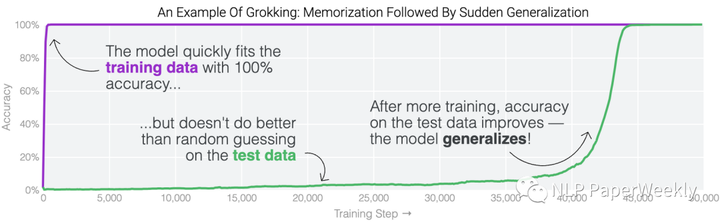
Aggregating curves of different skills lead to an overall loss curve.[1]
如上图,在训练开始时,模型记忆了训练数据,但测试精度比较低并且没有变化。随着训练的进行,从第35k步到第45k步有一个相变期,模型突然从记忆过渡到泛化,在测试集上显示出 100% 的准确率。学习过程中的这种阶段性变化被称为“grokking”。
1.2 speed of grokking和loss函数的优缺点是什么?
通常预训练模型评估指标:下一个单词预测损失(考虑到它与无损压缩的联系,信息量很大),但是loss函数并不能反映其在具体下游任务上的性能表现。
本文提到的评估指标:考虑speed of grokking摸索速度(模型获得特定技能的速度)可能是一个不错的选择替代指标。
说明:模型学习不同粒度技能的速度是不一样的,例如以下技能的难易程度不一样,模型能够学会解决这些问题所需要的时间也不一样,通过比较不同data engineering方法学习同一技能的速度(speed of grokking),可能是一个不错的评估方式。
不同粒度的技能对比:
- 单一技能:如两位数加法 => 难度低,学习速度块
- 聚合技能:一位数加法+两位数加法+两位数减法+…… => 难度中,模型所需要的学习时间中等
- 下游表现:GSM8k 数学作业题表现 => 难度大,模型所需要的学习时间最长
2 数据因素对speed of grokking的影响
本节主要讨论观察到的影响学习速度的数据因素,重点关注data format, mixture, and curriculum 这几个方面对模型的影响。
2.1 Format of data(训练数据格式)对模型的影响
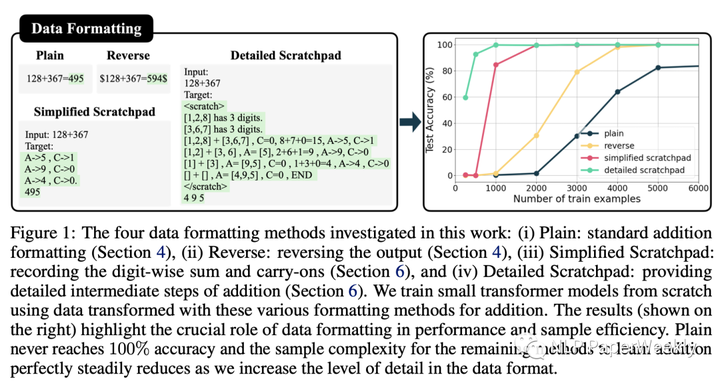

Different format of the data gives different speed of learning. Also note that they are the same data — same equation same answer, only the formats are different.[2]
数据说明:
- Plain:没有任何COT中间结果
- Reverse:倒过来
- Simplified Scratchpad:提供部分中间COT推理结果作为训练数据
- Detailed Scratchpad:提供详细的COT推理结果作为训练数据
结果:
- 利用越详细的COT中间结果来训练模型,模型学习的速度越快。
- 并不是其他Format of data不能学习到最终的结果(2,3,4的精度最后都到100%了),而是看谁的学习速度最快。
2.2 Curriculum of data(数据课程:按照一定的课程顺序编排训练数据,使模型学到的效果最佳)
什么是data curriculum?
假设:我们想要模型具备文本生成和代码生成能力,我们有 10B 文本和 10B 代码,计算资源只允许我们训练 10B 数据。希望使模型的代码生成能力最强。以下是三种可能的解决方案:
- 方法1(仅限代码):直接馈送10B代码数据
- 方法2(均匀混合):将5B文本和5B代码数据均匀混合,然后将它们同时输入模型
- 方法3(data curriculum):先输入5B文本,然后输入5B代码
哪一个能表现得最好?
- 如果模型从文本数据中学习的技能对代码数据没有帮助,那么我们可以直接执行方法1,仅利用代码数据来 训练模型,就像StarCoder和AlphaCode的情况一样。
- 如果模型从文本数据中学习的技能可以转移到代码数据中,那么我们可能想做方法2,均匀混合
- 如果学习代码技能需要模型先有文本技能,也就是说文本和代码之间有依赖关系,并且文本必须先有,那么我们需要做方法3,data curriculum(数据课程)。Codex 和 CodeLLaMA 就是这种情况(尽管他们可能不是故意选择这样做的)。
参考结论
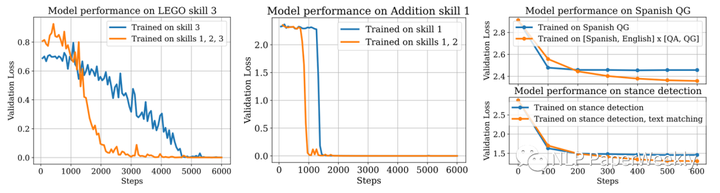

Different source of data induces different skills. Training on a particular ordering of data can give faster learning speed than training on skill-specific data.[3]
(a):想提高skill 3任务的效果,对比只在skill 3数据上训练和在skill 1,2,3数据上训练,发现在skill 1,2,3任务上训练收敛的速度更快。
(b):想提高skill 1任务的效果,对比只在skill 1数据上训练和在skill 1,2数据上训练,发现在skill 1,2任务上训练收敛的速度更快。
(c):想提上Spanish QG的效果,对比只在Spanish语料和同时在【spanish、English】语料训练,发现在【spanish、English】语料收敛速度慢点,但是最终效果更好。
(d):stance detection任务,也是在stance detection和text matching数据上同时修炼,最终的效果更好。
总结:叠加其他类型的数据,按照一定顺序来训练模型,可能比只在单一任务上训练效果更好,收敛速度更快。
2.3 Mix ratio(各部分数据比例对模型的影响)
LLaMA各部分数据占比
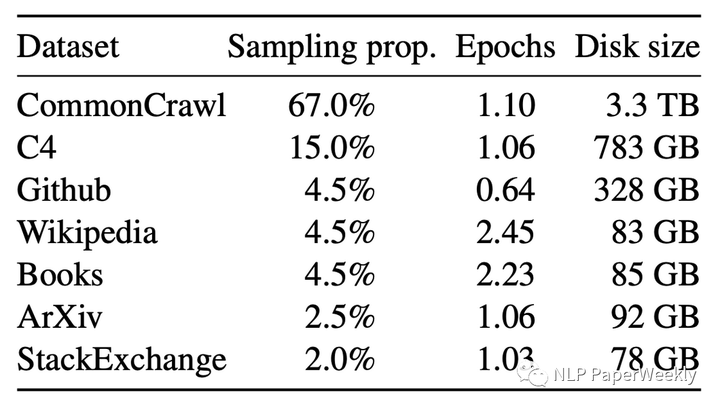
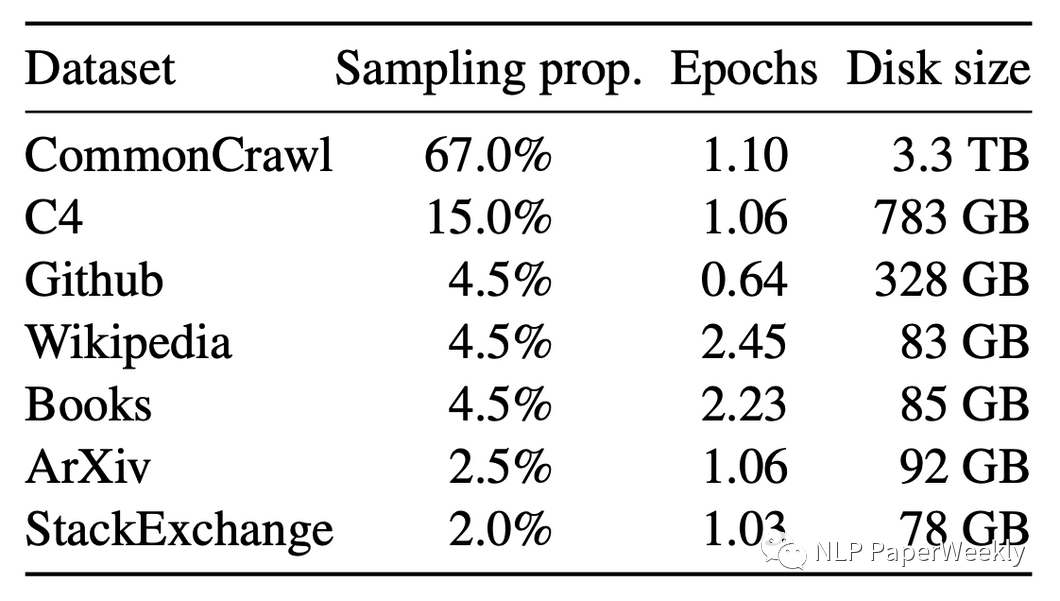
LLaMA data mix ratio. This ratio down weights code data like Github and StackExchange, also it down weights paper data like Arxiv.[4]
总结:
- LLaMA数据中Github的数据占比不高,他的coding表现也不太好,而starcode,大部分采用code数据训练,在coding task上效果比较好。
- LLaMA数据中Paper类的训练数据像Arxiv比较少,看起来科学推理效果也不高,而Galactica模型,大部分采用papers的数据,在科学推理上效果比较好。
不同的mix ratio可能造成不同的speed of learning:
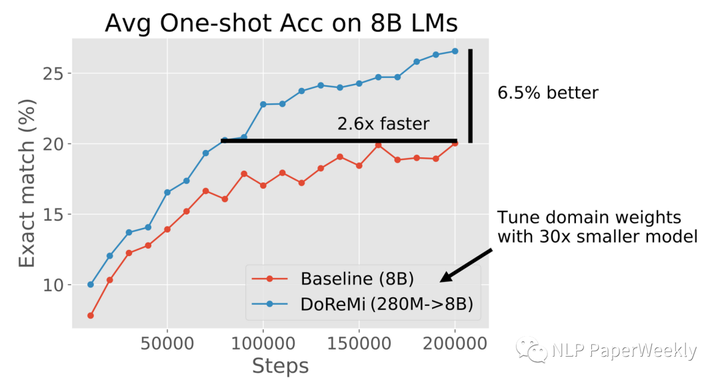
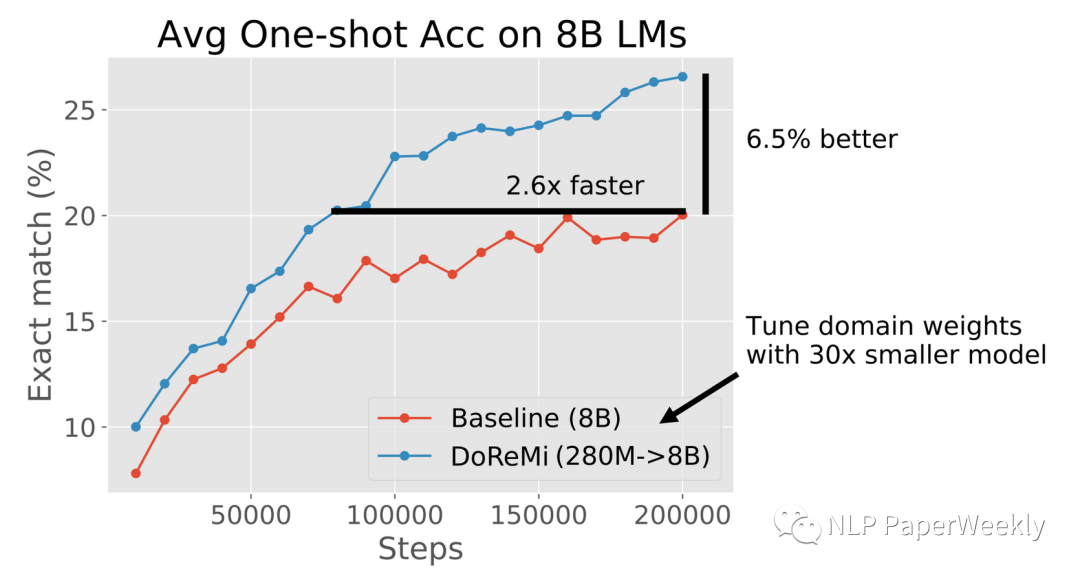
Different mix ratio of data improves speed of learning.[5]
结论:好的混合比例pile提上了模型的表现,使其有更好的学习曲线,让模型能给更快的从数据中进行学习。
2.4 Caveat:model scaling(模型尺寸大小对数据工程的影响):小于30B模型上data engineering有效果不代表大于70B的模型上该方法也会有效果
例如:代码数据真的能提升模型的推理能力吗?
- 7B模型:添加代码数据后,可以提升符号推理像Symbolic reasoning, like BABI and BBH-Algorithmic的效果,以及提升符号数据和语言数据的翻译能力,像such as structure-to-text or text-to-sql能力。
- 70B模型:对BBH-Algorithmic效果没有提升
- 代码数据对自然语言推理,像Natural language reasoning, like BBH-Language数据效果没有提升,对数学推理,像Math reasoning, like GSM8K的效果也没有提升。
总结:代码数据对小模型像7B模型的推理能力可能有一定帮助,但对大模型70B就没有帮助了。一些其他的观察也有出现这样的情况。如果真是这样,那可能不需要来做数据工程了,像data format / curriculum / mix ratio都没必要再做了,只需要做一些数据清洗工作就够了。
3 其他
3.1 不同skll学习曲线和整体loss曲线的关系
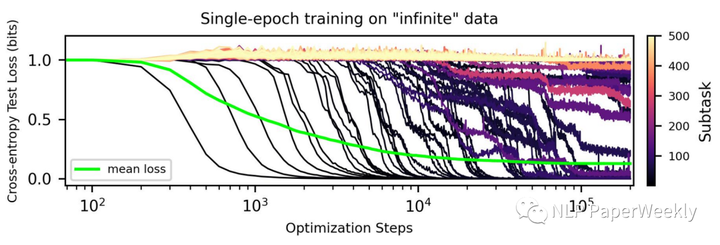
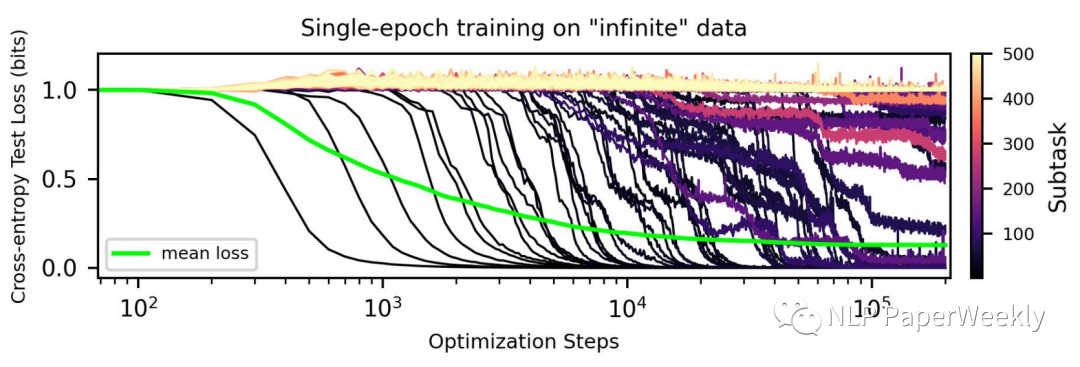
Aggregating curves of different skills lead to an overall loss curve.[6]
总结:
- 单技能的学习曲线通常表现出相变形状(在某个时间节点突然顿悟了)
- 模型学习不同skill的speed是不同的
- 集成多个skill到一块,我们可以获得一个平滑的log形状的loss曲线,说明loss函数可能只能反映一个整体的表现,而非每个具体task的效果。
3.2 loss和single-skill accuracy评价指标的优缺点
- LOSS:优点:可预测,和整体表现强相关,能解释成压缩比例。缺点:不能直接翻译成下游任务的表现。
- Single-skill accuracy(meso or macro level):只能衡量single skill的效果。
- 其他可能的metrics:
- 与能力方向很好地结合(比如推理)Aligns well with a direction of capability (say reasoning)
- 可以从第一原理推导出来(如信息论)Can be derived from first principles (like information theory)
- 衡量我们与“真正的生成过程”的接近程度,例如某种相互信息 Measures how close we are to the “true generative process”, like some sort of mutual information
3.3 模型学习是真正人类生存语言的过程而非记住数据(以随机数生成为例)
说明:这里以随机数无损压缩揭示了模型学习真实的生成的过程,说明模型是学习生成过程,而非随机生成的100B或者50B的随机数
- 随机数生成算法。例如,[Python随机数生成算法](https://github.com/python/cpython/blob/3.11/Lib/random.py)有904行代码,31.4 kb 磁盘内存。
- 使用此算法生成 100B 伪随机数。
- 将这100B随机数发送给朋友并要求朋友对其进行压缩。
- 在不了解底层生成过程(算法)的情况下,如果使用一些常见的压缩软件(例如 gzip),他们最终可能会得到 50B 左右的文件,压缩率很低。
- 如果以某种方式弄清楚了随机数生成算法和初始种子,只需存储算法和种子,只需要 31.4kb 磁盘内存,这是极高的压缩比。
- 大型神经网络及其学习算法,类似于上述过程,使用大量观察来恢复底层生成过程(数据生成算法)。压缩比/训练损失越高,他们恢复潜在生成过程的可能性就越大。
三、总结
本文回顾了语言模型学习的一些现象grokking, log-linear scaling law, emergent abilities,以及影响学习速度的数据因素data format, mix ratio, and curriculum(数据格式、混合比例和课程)。
总结1: 数据工程的目标是建立一种理论并指导我们做数据(以及其他重要的学习因素),以便我们可以在没写一行代码时就可预测每项任务的最终表现(而不仅仅是预训练损失)。例如OpenAI 报道称,在 GPT-4 的开发过程中,他们在实验前预测了 HumanEval 的性能。我们相信这种预测可以通过一个未知定理来统一,该定理能够预先预测所有下游性能。
总结2: 不同的data format, mix ratio, and curriculum确实可能会提升模型的学习速度,甚至最终的效果。例如为了提升代码能力,code-LLaMA2先在文本数据上训练,然后在代码数据上训练。
总结3: 一些数据工程对小模型有提升,但不意味着在大尺寸的模型上也有效果。例如code数据只对7B大小的模型的推理能力有帮助,对70B的模型效果没有提升。
模型4: 语言模型学习的是真正的语言生成过程,而非记住数据。这里以随机数压缩的例子说明模型之所以能够学习,是因为模型学习在无损压缩的角度下近似真实的生成过程。
总结5: 不同skill模型学习的speed是不一样的,模型的loss函数不能真正反映模型学习各种task的能力,它只是一个整体的表现评估指标。
四、参考
[1] Michaud E J, Liu Z, Girit U, et al. The quantization model of neural scaling[J]. arXiv preprint arXiv:2303.13506, 2023.
[2] Lee N, Sreenivasan K, Lee J D, et al. Teaching Arithmetic to Small Transformers[J]. arXiv preprint arXiv:2307.03381, 2023.
[3] Chen M F, Roberts N, Bhatia K, et al. Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models[J]. arXiv preprint arXiv:2307.14430, 2023.
[4] Touvron H, Martin L, Stone K, et al. Llama 2: Open foundation and fine-tuned chat models[J]. arXiv preprint arXiv:2307.09288, 2023.
[5] Xie S M, Pham H, Dong X, et al. DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining[J]. arXiv preprint arXiv:2305.10429, 2023.
[6] Michaud E J, Liu Z, Girit U, et al. The quantization model of neural scaling[J]. arXiv preprint arXiv:2303.13506, 2023.
五、更多文章精读
LLama2详细解读 | Meta开源之光LLama2是如何追上ChatGPT的?
大模型开源之光LLaMA2今天发布了,再来读下LLaMA1原文吧
Meta AI | 指令回译:如何从大量无标签文档挖掘高质量大模型训练数据?
TOT(Tree of Thought) | 让GPT-4像人类一样思考
OpenAI | Let’s Verify Step by Step详细解读
进技术交流群请添加我微信:FlyShines
请备注昵称+公司/学校+研究方向,否则不予通过
如果觉得文章能够帮助到你,点赞是对我最好的支持!