昆明微网站搭建免费做拍卖网站
本文主要介绍了sqlserver字符串拼接的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值。
1. 概
在SQL语句中经常需要进行字符串拼接,以sqlserver,oracle,mysql三种数据库为例,因为这三种数据库具有代表性。
sqlserver:
| 1 |
|
oracle:
| 1 2 3 |
|
mysql:
| 1 |
|
注意:SQL Server中没有concat函数(SQL Server 2012已新增concat函数)。oracle和mysql中虽然都有concat,但是oracle中只能拼接2个字符串,所以建议用||的方式;mysql中的concat则可以拼接多个字符串。
在SQL Server中的“+”号除了能够进行字符串拼接外,还可以进行数字运算,在进行字符串拼接时要小心使用。下面以“Users”表为例,进行详细分析:

2. 数字 + 字符串
2.1 int + varchar
| 1 2 |
|
| 1 |
|
2.2 decimal + varchar
| 1 |
|
| 1 |
|
由此可见,系统会将字符串varchar类型转化为int,若不能转换则提示错误,转换成功则进行数字计算。
3. 数字 + 数字
数字指的是int、decimal等类型。数字 + 数字,则进行数字相加,若某字段为NULL,则计算结果为NULL。
| 1 |
|
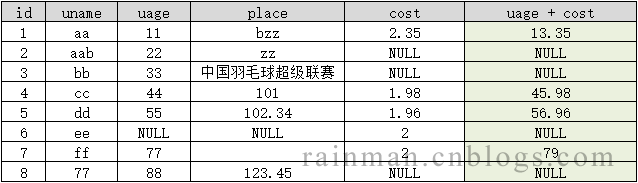
4.字符串 + 字符串
字符串 + 字符串,则直接进行拼接。若某字段为NULL,则计算结果为NULL。
| 1 |
|
5. 使用CAST和CONVERT函数进行类型转换
通过上述实例,可以看出若要使用“+”进行字符串拼接或数字计算,最稳妥的方法是进行类型转换。
- CAST()函数可以将某种数据类型的表达式转化为另一种数据类型
- CONVERT()函数也可以将制定的数据类型转换为另一种数据类型
要求:将“678”转化为数值型数据,并与123相加进行数学运算。
| 1 2 |
|
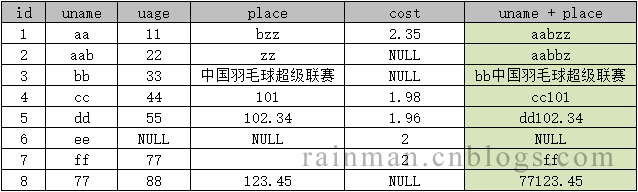
要求:id列和place列进行字符串拼接。
| 1 |
|
字符串拼接后的字符串不能简单作为“筛选字段”
有时,需要列A = 变量1,列B = 变量2的筛选,为了简化SQL语句 列A + 列B = 变量1 + 变量2。这种方法并不完全准确
| 1 |
|

| 1 |
|
![]()
为了防止上述情况的发生,可以再列A和列B之间加上一个较特殊的字符串。
| 1 |
|
到此这篇关于sqlserver字符串拼接的实现的文章就介绍到这了。