微网站建设完 不知道怎么推广咋办深圳西乡建网站
1、首先登录腾讯云官网控制台 进入对象存储页面
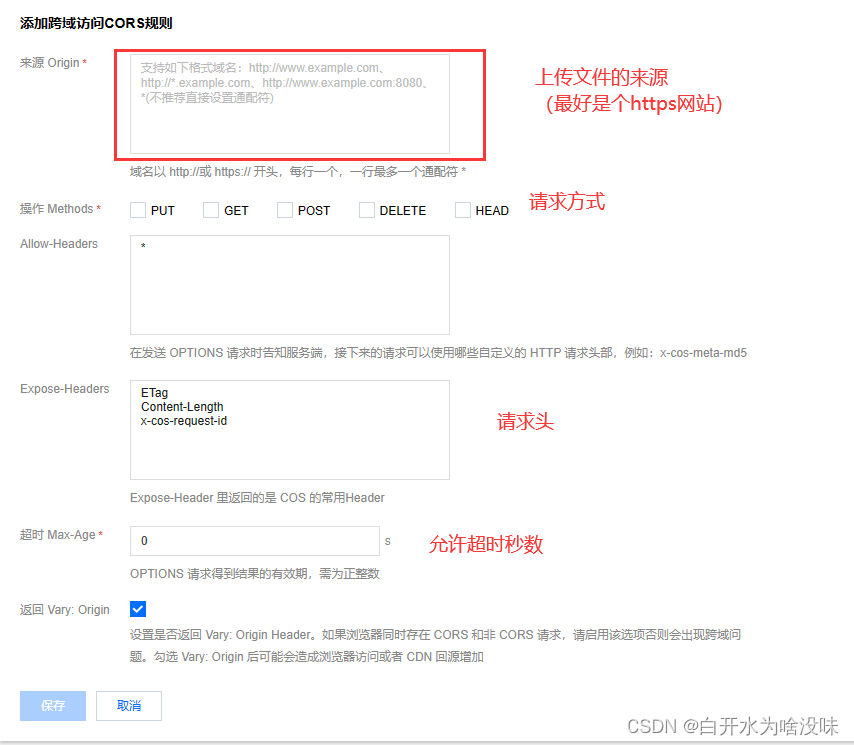
2、找到跨越访问CIRS设置 配置规则

点击添加规则

填写信息
3、书写代码
这里用VUE3书写
第一种用按钮出发事件形式
<template><div><input type="file" @change="handleFileChange" /></div>
</template><script>
import COS from "cos-nodejs-sdk-v5"; // 导入cos-nodejs-sdk-v5包export default {methods: {handleFileChange(event) {const file = event.target.files[0];const cos = new COS({SecretId: "YOUR_SECRET_ID",SecretKey: "YOUR_SECRET_KEY",});// 替换成你的 Bucket 名称和 Regionconst bucket = "YOUR_BUCKET_NAME";const region = "YOUR_BUCKET_REGION";// 生成对象存储桶中的图片路径const key = `images/${file.name}`;// 将图片上传到腾讯云对象存储桶cos.putObject({Bucket: bucket,Region: region,Key: key,Body: file,},(err, data) => {if (err) {console.error("上传失败:", err);this.$message.error("上传失败")} else {console.log("上传成功:", data.Location);this.$message.success("上传成功")}});},},
};
</script>
4、测试
点击选择文件

选择图片
等待结果


第二种用el-upload
<el-upload v-if="imageUrl===null"class=""list-type="picture-card":show-file-list="false":before-upload="beforeUpload"action="":on-change="handleUploadChange"><el-icon class="el-icon-plus"><plus></plus></el-icon>
</el-upload>beforeUpload(file) {// 预览图片this.file = file;this.imageUrl = URL.createObjectURL(file);console.log("头像链接为"+this.imageUrl)return new Promise((resolve, reject) => {const cos = new COS({SecretId: "", // 身份识别 IDSecretKey: "", // 身份密钥});// 替换成你的 Bucket 名称和 Regionconst bucket = "";const region = "";// 生成对象存储桶中的图片路径const key = `user_information/avatar/${this.user.username}/${file.name}`;let key1='';console.log("key为"+key)// 将文件转换为 Blob 对象const blob = new Blob([file.raw], { type: file.type });console.log("blob"+blob)// 将图片上传到腾讯云对象存储桶cos.putObject({Bucket: bucket,Region: region,Key: key,Body: file,},(err, data) => {setTimeout(()=>{if (err) {console.error("上传失败:", err);this.$message.error("上传失败");reject(err);} else {// console.log("打撒笔"+this.user.avatarUrl)console.log("上传成功:", data.Location);if(this.user.avatarUrl!==null){key1 = this.user.avatarUrl.replace("https://"+bucket+".cos."+region+".myqcloud.com/", "");// 删除文件console.log("key1:", key1);cos.deleteObject({Bucket: bucket,Region: region,Key: key1,}, (err, data) => {if (err) {console.log('Error deleting file:', err);} else {console.log(data)console.log('云端路径为:'+key1+"的图片已经被删除");}});}this.form.avatarUrl="https://"+ data.Locationthis.user.avatarUrl="https://"+ data.LocationlocalStorage.setItem("user", JSON.stringify(this.user));// 刷新当前页面location.reload();this.save1();console.log(data)// this.$message.success("上传图片成功");resolve(false); // 阻止 Element-UI 的默认上传行为}},1000)});// if(key1!==''){// }});},也可以把el-upload嵌套button包装成这种形式
<el-uploadclass="":show-file-list="false":before-upload="beforeUpload"action="":on-change="handleUploadChange"style="margin-right: 15px"><el-button v-if="this.user.avatarUrl" style="background-color: #3f72af;color: white;border-radius: 15px;width: 100px;height: 40px" type="" >更改头像</el-button>
</el-upload>
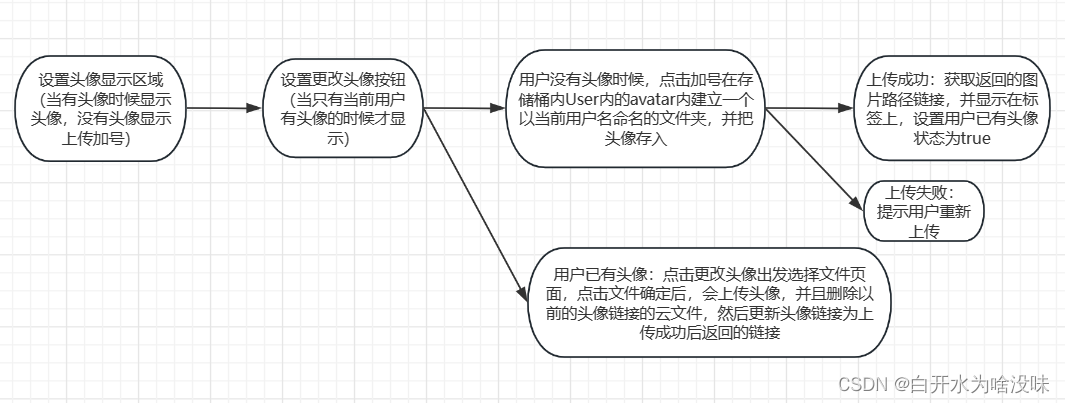
按照这个逻辑上传头像的整体代码 (写的不好 待优化 欢迎大神优化)
<div v-if="this.user.avatarUrl" class="avatar"><el-image id="elimg" class="preview-image":src="this.user.avatarUrl"style="width: 170px; height: 170px; position: relative; justify-content: center" ></el-image ></div><div v-else class="avatar" id="avatar"><el-image id="elimg" v-if="imageUrl" class="preview-image":src="imageUrl":preview-src-list="[imageUrl]" style="width: 170px; height: 170px; position: relative; justify-content: center" ></el-image ><el-icon size="large" v-if="imageUrl" class="el-icon-close" @click="cancelUpload"><close></close></el-icon><el-upload v-if="imageUrl===null"class=""list-type="picture-card":show-file-list="false":before-upload="beforeUpload"action="":on-change="handleUploadChange"><el-icon class="el-icon-plus"><plus></plus></el-icon></el-upload></div>import {Close, Plus} from "@element-plus/icons";
import COS from "cos-js-sdk-v5";export default {name: "UserInfo",components: {Plus,Close},data(){return {form:{},user: localStorage.getItem("user") ? JSON.parse(localStorage.getItem("user")):{},imageUrl: null,file: null,}},} beforeUpload(file) {// 预览图片this.file = file;this.imageUrl = URL.createObjectURL(file);console.log("头像链接为"+this.imageUrl)return new Promise((resolve, reject) => {const cos = new COS({SecretId: "", // 身份识别 IDSecretKey: "", // 身份密钥});// 替换成你的 Bucket 名称和 Regionconst bucket = "";const region = "";// 生成对象存储桶中的图片路径const key = `user_information/avatar/${this.user.username}/${file.name}`;let key1='';console.log("key为"+key)// 将文件转换为 Blob 对象const blob = new Blob([file.raw], { type: file.type });console.log("blob"+blob)// 将图片上传到腾讯云对象存储桶cos.putObject({Bucket: bucket,Region: region,Key: key,Body: file,},(err, data) => {setTimeout(()=>{if (err) {console.error("上传失败:", err);this.$message.error("上传失败");reject(err);} else {// console.log("打撒笔"+this.user.avatarUrl)console.log("上传成功:", data.Location);if(this.user.avatarUrl!==null){key1 = this.user.avatarUrl.replace("https://"+bucket+".cos."+region+".myqcloud.com/", "");// 删除文件console.log("key1:", key1);cos.deleteObject({Bucket: bucket,Region: region,Key: key1,}, (err, data) => {if (err) {console.log('Error deleting file:', err);} else {console.log(data)console.log('云端路径为:'+key1+"的图片已经被删除");}});}this.form.avatarUrl="https://"+ data.Locationthis.user.avatarUrl="https://"+ data.LocationlocalStorage.setItem("user", JSON.stringify(this.user));// 刷新当前页面location.reload();this.save1();console.log(data)// this.$message.success("上传图片成功");resolve(false); // 阻止 Element-UI 的默认上传行为}},1000)});// if(key1!==''){// }});},cancelUpload() {// 清除预览图片和文件this.imageUrl = null;this.file = null;},save1(){this.request.post("/saveuser",this.form).then(res => {if(res){this.$message.success("保存图片成功")}else{this.$message.error("保存图片成功")}})},