江门h5模板建站门户网站建设解决方案
化工厂每年需要现场检修很多机器,比如泵、压缩机、管道、塔等等,现场检查人员都是使用照相机,现场拍完很多机器后,回办公室整理乱糟糟的照片,但是经常照了之后无法分辨是哪台设备,而且现场经常漏拍,而且现场检修时候,有许多检修公司负责各种工序,前后衔接不确定,所以需要一个统一的可视指挥调度平台,发布实时的机器状态。
比如我的这台塔拆好了,等待清洗;
这台塔洗好了,等待检查;
这台塔检查好了,等待签字确认;
这台塔完全好了,等待回装,预计几号吊装;

解决方案
通过手持式4G工作记录仪+可视指挥调度平台VMS/smarteye。
AIoT万物智联,智能安全帽、智能头盔、头盔记录仪、执法记录仪、车载DVR/NVR、布控球、智能眼镜、智能手电、无人机4G补传系统等统一接入大型融合通信可视指挥调度平台VMS/smarteye 。
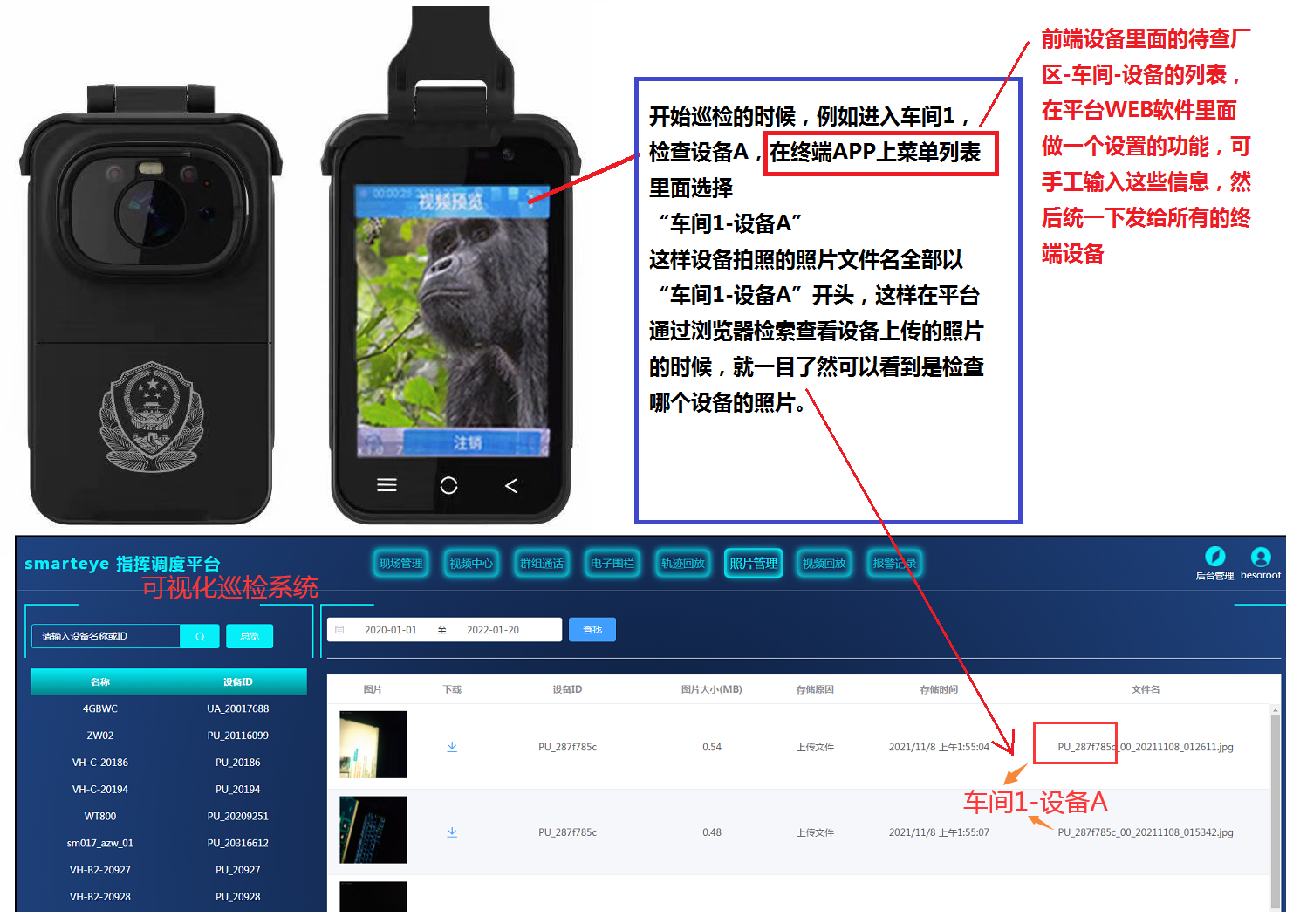
在smarteye主服务器上设定好文件夹(如CM1-E303上管板、精馏塔1的密封面、CH1-T203保温层等),
手持前端选择某个文件夹,再拍照片,照片就会自动上传到选择的文件夹里,
这样就不需要我的检查人员,从现场回来之后分类照片,
手持前端可以编辑简单的文字或表格,现场的检查人员,根据检查的状况,编辑文字,发送到服务器,
服务器汇总所有手持前端的文字,根据时间,形成一个文档或者表格,这样就可以自动形成现场所有的状态。
服务器可以发布表格或文字信息,手持前端可以查看,或者微信可以查看,或者电脑可以查看,这样管理者就可以统一发布计划、信息、状态。
百川汇流万物智联尽入优视融合通信~大型融合通信可视指挥调度平台smarteye
5G执法记录仪+5G智能安全帽/头盔摄像头+5G智能AI布控球+融合同学可视指挥调度平台smarteye
#物联网#IoT+5G互联+AI智能视频分析#边缘计算#+大数据+遥感+#GIS#,八仙过海齐汇聚,保障安全无所惧!
#智能安全帽#/#头盔摄像头#+#4G记录仪#+#智能布控球#+#无人机4G回传#,移动视频四剑客,天生绝配,联手打造立体化全方位安全生产可视监管系统。
万物智联AIoT+5G智能感知图传,一切尽在合肥优视大型可视指挥调度平台VMS/smarteye 。