网站后台忘了玉田做网站
引言:单图生成结构化 3 D 模型的技术突破
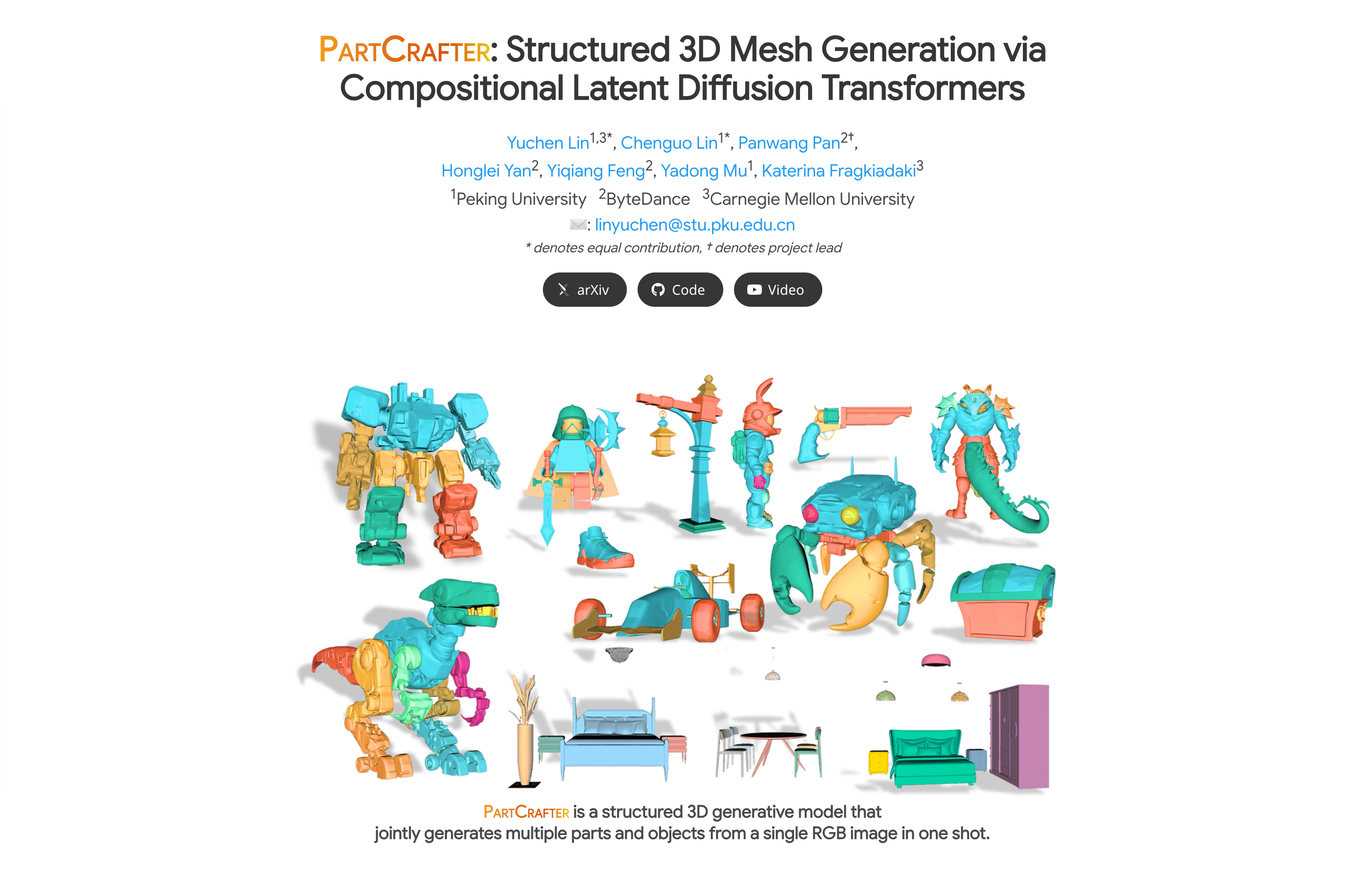
PartCrafter 由北京大学、字节跳动与卡耐基梅隆大学联合研发,是全球首个端到端生成结构化 3 D 网格的模型。它仅需单张 RGB 图像,即可在 34 秒内生成带语义分解的 3 D 部件(如机械关节、家具组件),跳过传统“分割-重建”流程,直接输出可编辑的零件级模型。其核心突破在于将物理世界的组合逻辑融入 AI 生成过程,甚至能推断图像中被遮挡的隐藏结构。
一、传统 3 D 建模的瓶颈与 PartCrafter 的革新
传统方法的两大局限:
- 整体生成法(如 TripoSR):输出单一网格,无法分离部件,二次编辑困难。
- 两阶段法(如 HoloPart):需先分割图像再独立重建部件,导致部件连接错误或悬空,且耗时长达 18 分钟。
PartCrafter 的解决方案:
- 统一生成架构:无需预分割输入,直接端到端输出多部件 3 D 模型。
- 物理逻辑内嵌:模型通过部件关系先验,自动补全被遮挡结构(如从椅面图像推断完整椅腿)。
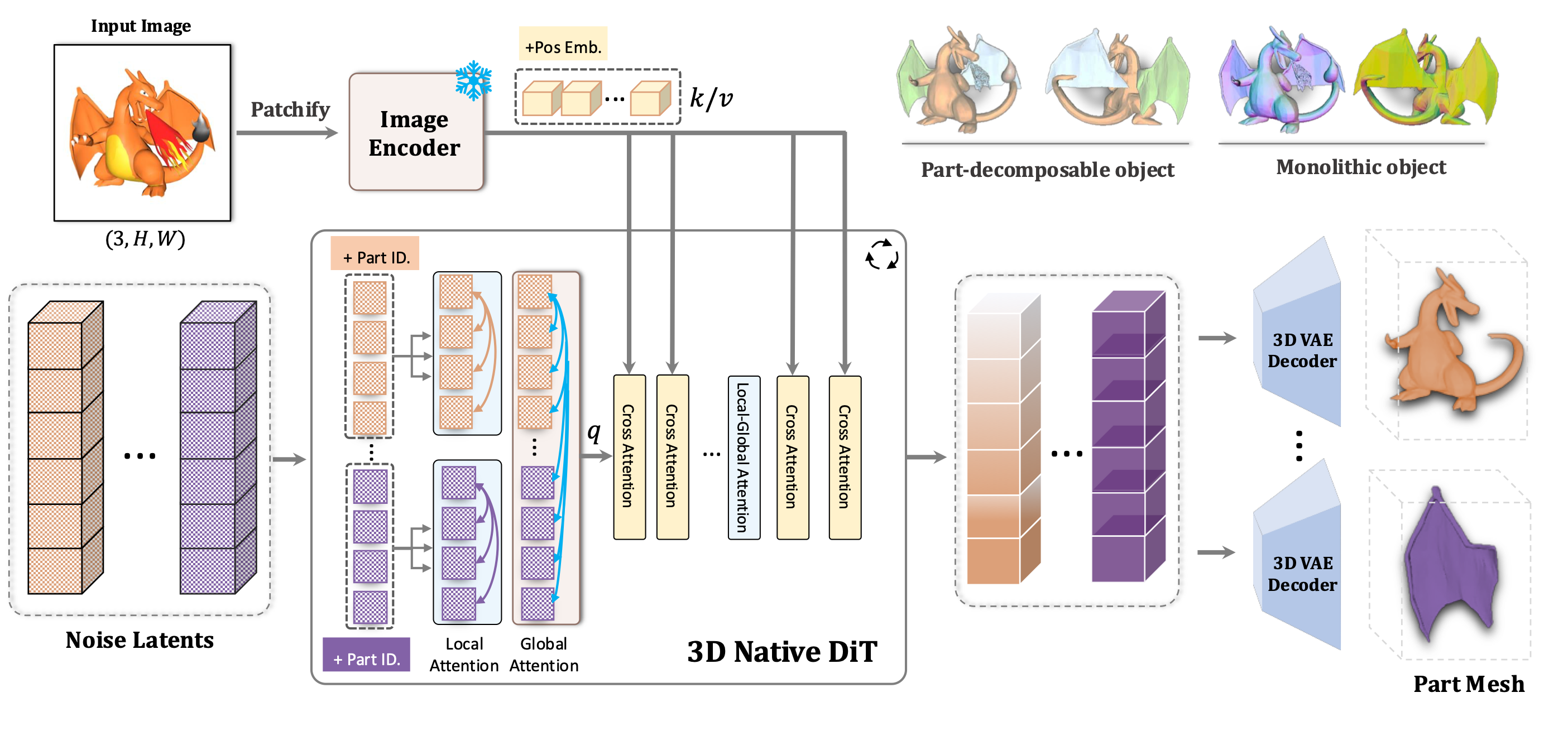
二、核心技术解析:组合生成与分层推理
1. 组合式潜在空间:像乐高一样编码部件
每个 3 D 部件由独立潜在令牌(Latent Tokens)表示,并绑定可学习的部件 ID 嵌入。这种设计支持:
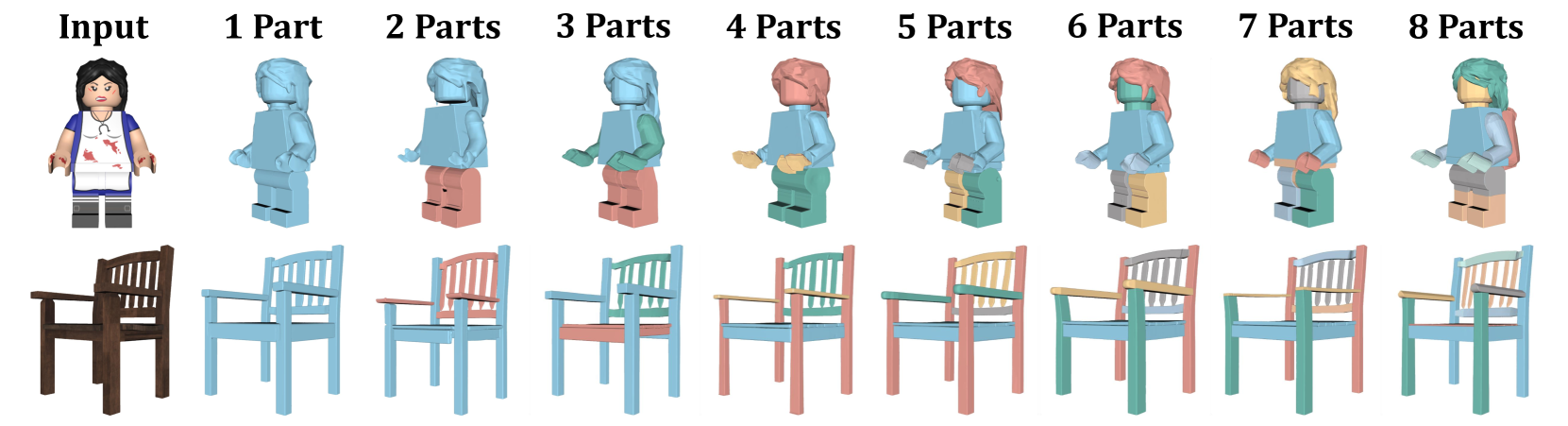
- 粒度控制:按需输出粗粒度(椅子=椅背+座垫)或细粒度分解(椅腿→连接件+支撑杆)。
- 独立编辑:生成后可直接调整单个部件的位置、旋转或缩放。
2. 分层注意力机制:双轨信息流协同
模型通过21 层交替的局部-全局注意力实现协同优化:
- 局部注意力(奇数层):聚焦部件内部细节(如齿轮齿距、曲面弧度)。
- 全局注意力(偶数层):协调部件关系(如轴承与轴孔对齐),避免碰撞或悬空。
3. 预训练模型迁移:继承与超越
复用预训练的 3 D 网格扩散 Transformer(DiT)的权重与解码器。实验证明,其生成保真度超越底层 DiT 模型(Chamfer 距离降低 18%),验证结构化理解提升整体质量。
三、性能实测:效率与精度双突破
生成质量(Objaverse 数据集):
| 指标 | PartCrafter | HoloPart | 提升 |
|---|---|---|---|
| Chamfer 距离 | 0.1726 | 0.2103 | ↓18% |
| F-Score@0.1 | 0.7472 | 0.6815 | ↑9.6% |
| 网格错误率 | 0.033 | 0.100 | ↓67% |
生成效率:
- 4 部件模型生成仅需 34 秒,比 HoloPart 快 30 倍;
- 支持 1080 P 图像输入,单张 NVIDIA RTX 3090 GPU 可部署。
四、真实应用场景
- 游戏开发:输入角色原画,生成带关节的恐龙尾部模型,直接导入 Unity 引擎。
- 工业设计:生成齿轮组+轴承的装配体,导出. STL 格式用于 3 D 打印。
- 教育可视化:分解内燃机模型,动态演示活塞运动过程。
- 建筑场景:输入室内草图,生成带门窗结构的可编辑房屋模型。


五、部署指南:本地运行步骤
环境要求:
- 系统:Ubuntu 20.04+
- GPU:NVIDIA RTX 3090(24 GB 显存)
- 依赖:Python 3.8+, PyTorch 2.0+
部署流程:
# 1. 克隆代码库
git clone https://github.com/wgsxm/PartCrafter # 2. 安装依赖
pip install -r requirements.txt # 3. 下载预训练权重(暂用占位符,7月15日前发布完整版)
wget https://partcrafter.models/pretrained_vae.pth # 4. 生成示例(输入图像+指定部件数)
python generate.py --input_image chair.jpg --part_count 4
输出格式:支持. obj/. glb,兼容 Blender、Maya 等工具。
注意事项:当前预训练权重为占位版本,完整版预计 7 月 15 日发布于 Hugging Face。
结语:结构化生成——虚拟与现实的几何桥梁
PartCrafter 的突破不仅在于速度,更在于将物理世界的组装规则编码进 AI。它证明:理解“椅子由椅腿和椅背组成”这一常识,能让 3 D 生成更合理、更易用。随着 7 月完整开源,这项技术或将重塑游戏、工业、教育领域的 3 D 内容生产流程。
延伸价值:若未来融入物理引擎约束(如动力学模拟),生成模型可直接用于机器人运动规划——结构化生成,正成为连接数字与物理世界的核心技术。
往期回顾:
【7 天 Python 速成指南】极客必备:从零到项目实战的高效路径
WWDC25 技术彩蛋三行代码调用30亿参数大模型:苹果为何赌定设备端AI?
当 Java 遇上大模型,LangChain4j 如何成为开发者的「AI 胶水」?
突破性轻量OCR:3B参数的MonkeyOCR如何吊打Gemini与72B巨头?
【本地部署教程】Qwen2.5-VL 阿里最新开源最强的开源视觉大模型,支持视频!
一键解锁智能文档问答新体验!开源 RAG 引擎 RAGFlow 重磅来袭