关于网站建设规划方书案例样式合肥最新通告今天
目录
LVGL简介
1、特点
2、LVGL的硬件要求
3、相关网站
4、LVGL源码下载
5、LVGL移植要求
5.1 移植过程-添加源码
2、更改接口文件
3、显示实现
4、添加外部中文字体的方法
5、编译下载后有几种情况
6、调用显示
6、GUI-Guider使用
6.1 安装软件
6.2 使用软件
6.3 移植到STM32
LVGL简介
LittlevGL是一个免费的开源图形库,提供了创建嵌入式GUI所需的一切,具有易于使用的图形元素、漂亮的视觉效果和低内存占用。

1、特点
- 强大的构建模组:按钮、图表、列表、滑块、图像等
- 先进的图形:动画、反锯齿、半透明、平滑滚动
- 多样的输入设备:触摸板、鼠标、键盘、编码器等
- 多显示器支持:支持同时使用多个TFT或单色显示器
- 多语言支持:格式文字编码
- 硬件无关:可用于任UTF-8意微控制器或显示器
- 可裁剪:用于小内存(64 KB FLASH,16 KB RAM)操作
- 外部支持:操作系统、外部存储以及GPU
- 单帧缓存:即可实现先进的图形效果
- C语言编写:以最大化兼容(C++ 兼容)
- 模拟器:无需嵌入式硬件就可以在电脑上开始GUI设计
- 文档:在线及离线
- 免费开源:基于MIT协议
2、LVGL的硬件要求

3、相关网站
- LVGL官网:LVGL - Light and Versatile Embedded Graphics Library
- LVGL代码库地址(Simulator、Source、Examples、Esp32、MicroPython):LVGL · GitHub
- LVGL源码下载地址:GitHub - lvgl/lvgl: Embedded graphics library to create beautiful UIs for any MCU, MPU and display type. It's boosted by a professional yet affordable drag and drop UI editor, called SquareLine Studio.
4、LVGL源码下载
在源码链接中下载一份源码,LVGL已经更新迭代了很多个版本,这里我们选择8.0.1版本来移植。

注意:不同版本之间有很大的不同,尽量使用与本文相同的版本,否则不予解释。
下载后得到的目录如下:

源码各文件作用
- github:github的配置文件,忽略即可。
- docs:说明文档。
- examples:示例代码。
- scripts:配置脚本,Linux平台会用到,Windows忽略即可。
- src:源代码。
- tests:测试代码。
5、LVGL移植要求
STM32工程,该工程应具备功能:
LCD显示(必备)
- TOUCH触摸(可选)
- DMA刷屏(可选)
- 内存管理(可选)
- 操作系统(可选)
5.1 移植过程-添加源码
在工程目录下创建LVGL文件夹,
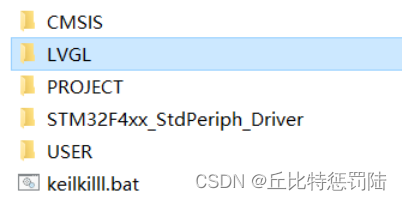
接着, 将LVGL的源码目录(lvgl-8.0.1\src)复制到本工程中的LVGL目录中
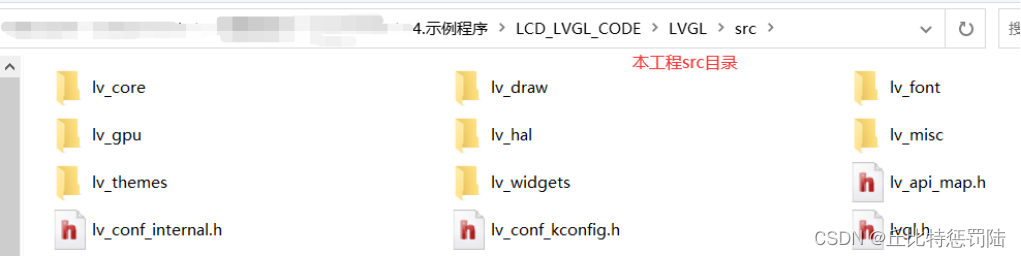
接下来,将LVGL的驱动接口文件目录(lvgl-8.0.1\examples\porting)复制到本工程中的LVGL文件夹中。其中共六个文件,disp为显示接口驱动文件(LCD),fs为文件系统接口驱动文件(FATFS),indev为输入设备接口驱动文件(TOUCH)

接着, 将LVGL源码中(lvgl-8.0.1)的lv_conf_template.h更名为lv_conf.h,随后将其与lvgl.h一同拷贝到本地工程中的LVGL目录下;
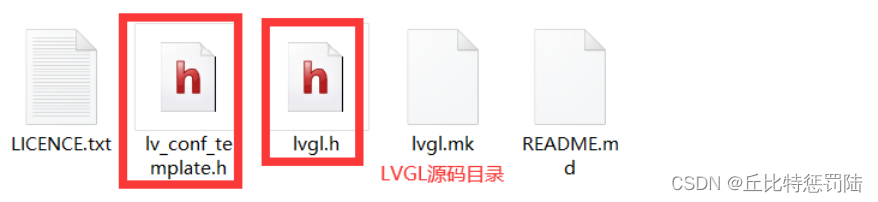
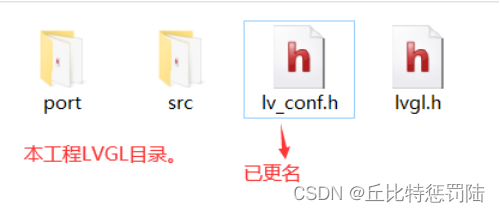
接着, 打开工程,在工程的目录结构中添加二个文件夹LVGL_SRC和LVGL_PORT,并把源码添加到其中。(可根据需要进行裁剪)。
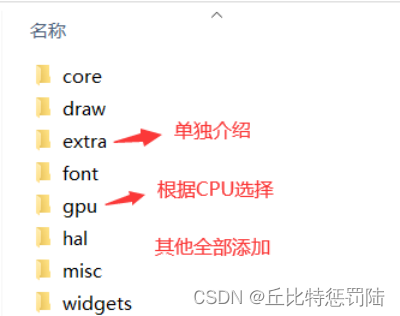
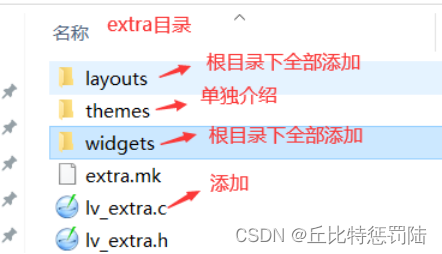

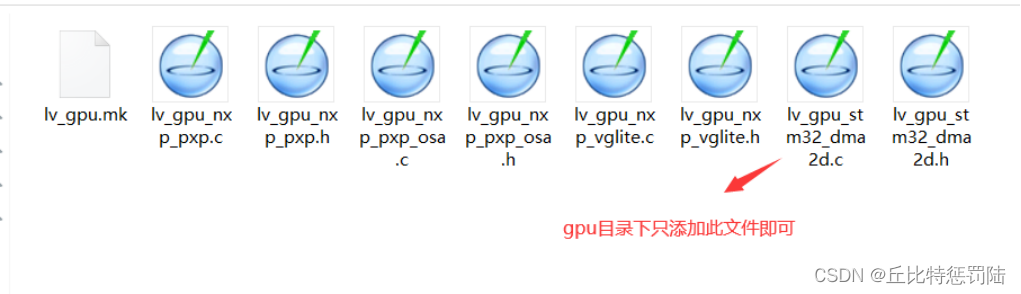
添加port文件
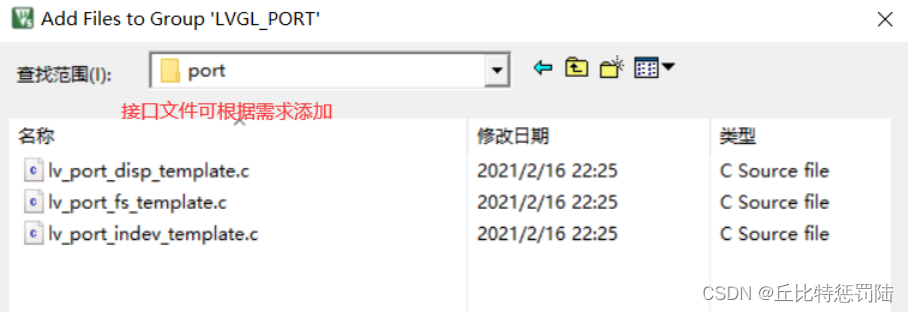
不知道就全部都添加。本示例只使用disp这个显示的模板。
接着,添加源码头文件路径;
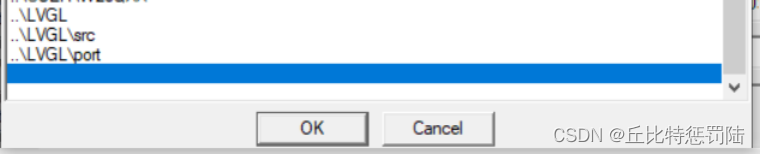
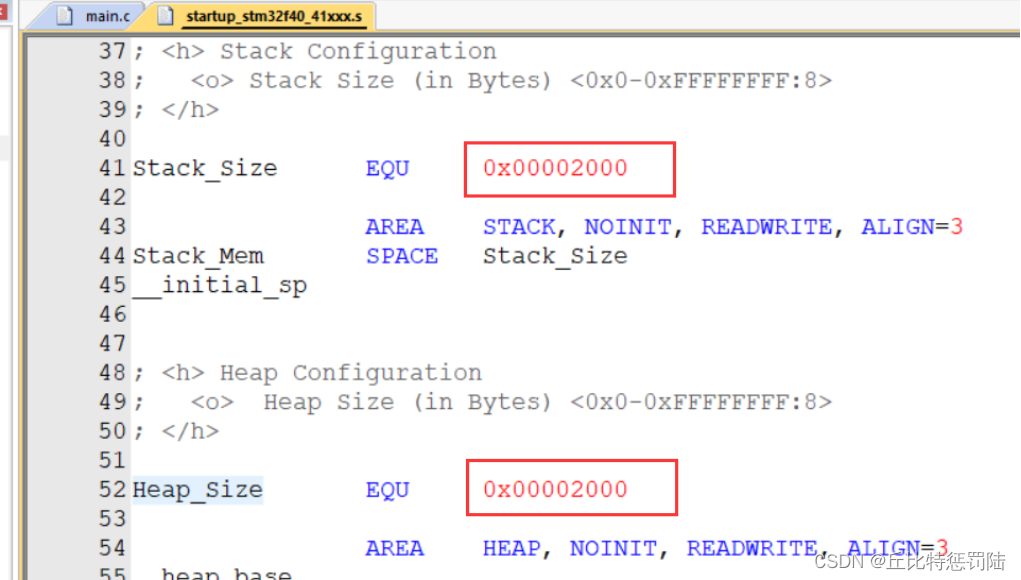
如果工程中没有内存管理,则需要修改启动文件中的堆栈。根据官方推荐我们可以把堆栈修改为4K,假如使用的功能比较多,还需要再适当增大;
LVGL的源码需要C99的支持,否则编译无法通过;
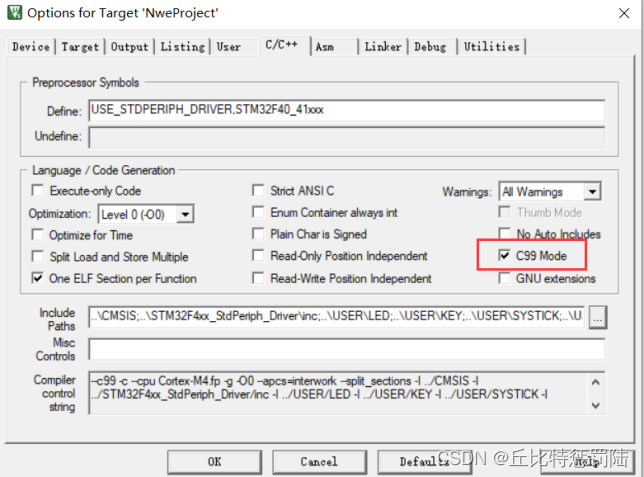
next,编译工程


双击错误定位到错误位置发现,该代码包含的头文件路径层级错误,根据目录层级修改。(原来是../../lv_conf,更改为../ lv_conf)
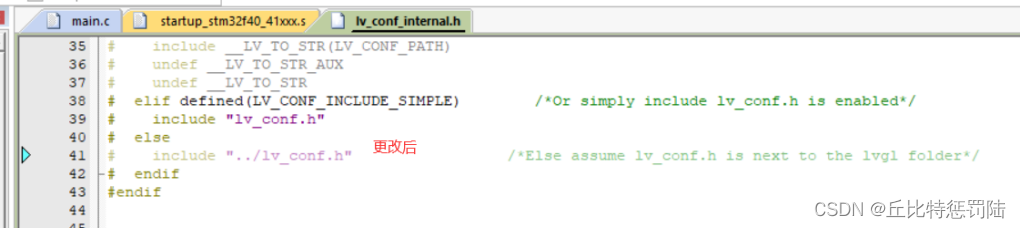
打开lv_conf文件中的条件编译。lv_conf的条件编译没有打开,去到此文件下打开该文件修改保存即可;

编译。如果出现以下错误:
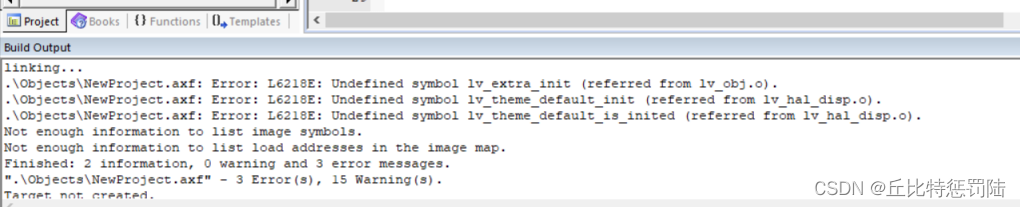
只剩3个错误了,原因是没有添加主题源文件(..\LVGL\src\extra\themes\default)。把下图中的文件添加到工程。
如果出现以下错误:
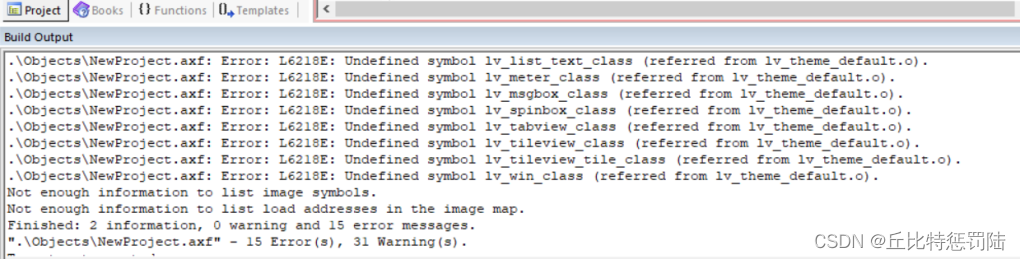
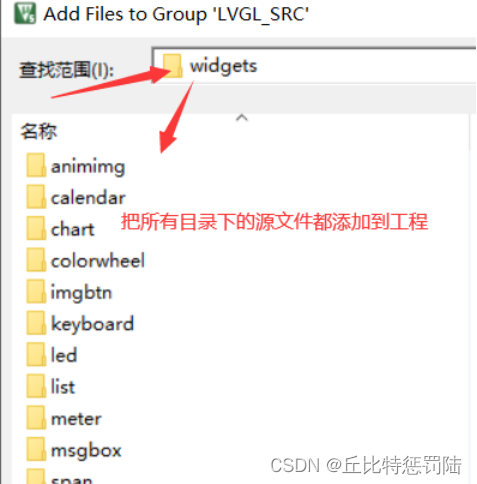
不这是因为没有添加控件的源文件,默认所有控件是使能状态的(lv_conf.h),我们把这些源文件(src\extra\widgets目录下)都添加到我们的工程中(如果在添加src文件时已经全部添加则不会出现这些错误)。
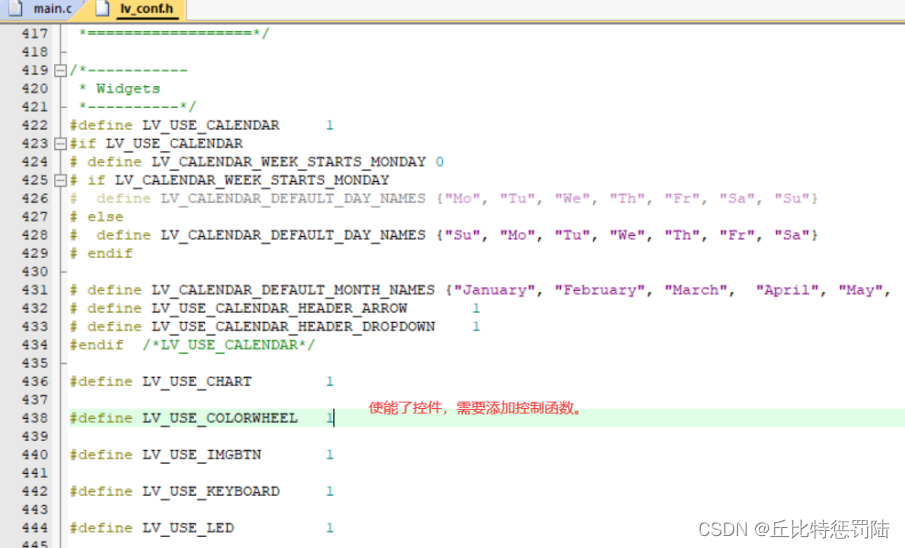
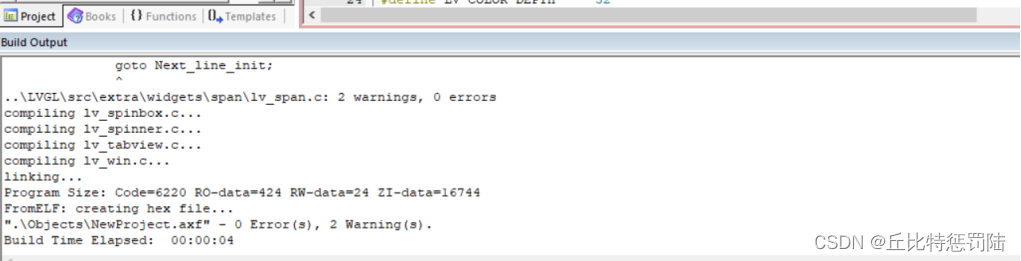
最终编译没有错误了。
移植成功了,但是还显示不了,我们还需要去实现显示的相关接口。
2、更改接口文件
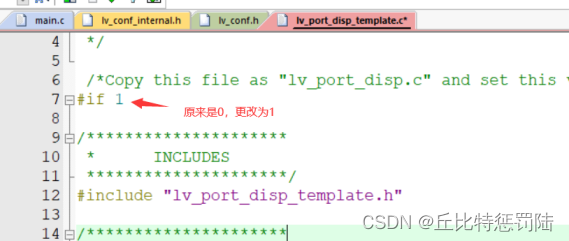
默认lv_port_disp_templ.c和lv_port_disp_templ.h的条件编译是关闭的,我们需要把他打开并修改包含目录层级。

更改lv_port_disp_templ.c 文件中lv_port_disp_init驱动函数。此函数提供了三种写缓存方式,保留其中一种即可,本示例采用方式二;
方式一:单缓存显示(10行),主控内存较小时选用此方式。
方式二:双缓存显示(两个10行),此方式支持DMA交替传输,缓存区越大,显示效果越好(有条件两个满屏缓存)。
方式三:双满屏缓存显示,相当于有条件的方式二
注释方式一和方式三,更改第二种方式如下:
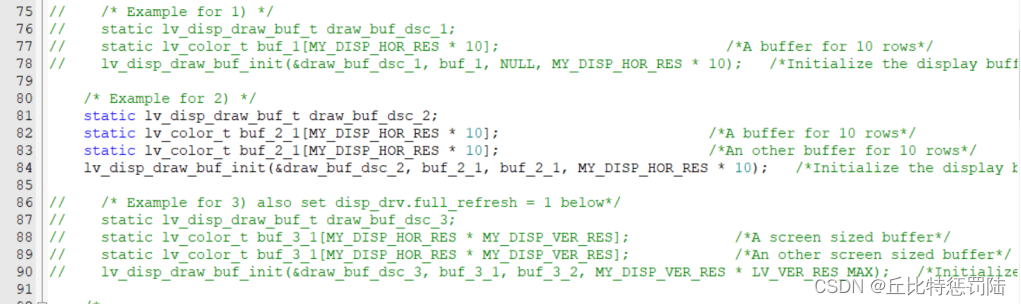
方式二更改如下:
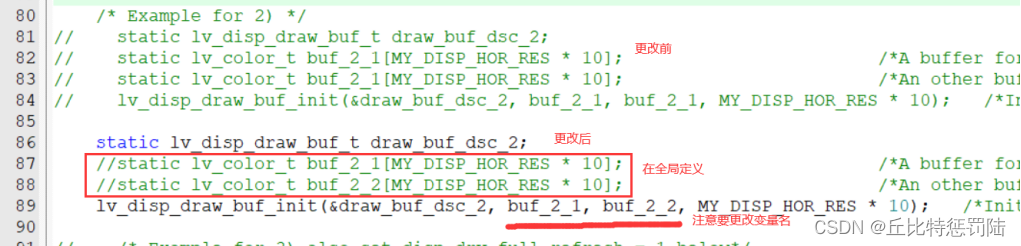

更改屏幕大小:

添加DMA实现代码,并在disp_init函数中调用DMA的初始化函数(如果不使用DMA,disp_flush函数中只需要保留LCD_Color_Fill、lv_disp_flush_ready这两个函数即可)。注意添加需要的头文件。如#include "lcd.h"
- 添加一个全局变量static lv_disp_drv_t *disp_drv_p;
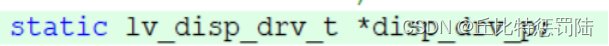
把以下代码添加到lv_port_disp_templ.c,
static void DisPlay_SPI_DMA_Init()
{DMA_InitTypeDef DMA_InitStructure = {0};NVIC_InitTypeDef NVIC_InitStruct = {0};RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_DMA1, ENABLE); //DMA1时钟使能DMA_DeInit(DMA1_Stream7);while(DMA_GetCmdStatus(DMA1_Stream7) != DISABLE) {} //等待DMA可配置/* 配置 DMA Stream */DMA_InitStructure.DMA_Channel = DMA_Channel_0; //通道选择DMA_InitStructure.DMA_PeripheralBaseAddr = (unsigned int)&SPI3->DR; //DMA外设地址DMA_InitStructure.DMA_Memory0BaseAddr = (unsigned int)buf_2_1; //DMA 存储器0地址DMA_InitStructure.DMA_DIR = DMA_DIR_MemoryToPeripheral; //存储器到外设模式DMA_InitStructure.DMA_BufferSize = sizeof(buf_2_2); //数据传输量DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable; //外设非增量模式DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable; //存储器增量模式DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_Byte; //外设数据长度:8位DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_Byte; //存储器数据长度:8位DMA_InitStructure.DMA_Mode = DMA_Mode_Normal; //使用普通模式DMA_InitStructure.DMA_Priority = DMA_Priority_High; //中等优先级DMA_InitStructure.DMA_FIFOMode = DMA_FIFOMode_Disable; //不使用fifoDMA_InitStructure.DMA_FIFOThreshold = DMA_FIFOThreshold_Full; //fifo全容量DMA_InitStructure.DMA_MemoryBurst = DMA_MemoryBurst_Single; //存储器突发单次传输DMA_InitStructure.DMA_PeripheralBurst = DMA_PeripheralBurst_Single; //外设突发单次传输DMA_Init(DMA1_Stream7, &DMA_InitStructure); //初始化DMA StreamSPI_I2S_DMACmd(SPI3, SPI_I2S_DMAReq_Tx, ENABLE); // SPI3使能DMA发送NVIC_InitStruct.NVIC_IRQChannel = DMA1_Stream7_IRQn;NVIC_InitStruct.NVIC_IRQChannelCmd = ENABLE;NVIC_InitStruct.NVIC_IRQChannelPreemptionPriority = 2;NVIC_InitStruct.NVIC_IRQChannelSubPriority = 2;NVIC_Init(&NVIC_InitStruct);DMA_ITConfig(DMA1_Stream7, DMA_IT_TC, ENABLE);DMA_Cmd(DMA1_Stream7, DISABLE);
}/*********************************************************************************************************
* 函 数 名 : DisPlay_SPI_DMA_Enable
* 功能说明 : 配置DMA并启动一次传输
* 形 参 : buf:需要搬运的数据的指针;size:搬运的数据量
* 返 回 值 : 无
* 备 注 : 无
*********************************************************************************************************/
void DisPlay_SPI_DMA_Enable(void *buf, unsigned int size)
{DMA1_Stream7->CR &= ~(0x01);while((DMA1_Stream7->CR&0X1)){}DMA1_Stream7->M0AR = (unsigned int)buf;DMA1_Stream7->NDTR = size;DMA1_Stream7->CR |= (0x01);
}
/*********************************************************************************************************
* 函 数 名 : DMA1_Stream7_IRQHandler
* 功能说明 : DMA1_Stream7发送完成中断
* 形 参 : 无
* 返 回 值 : 无
* 备 注 : 无
*********************************************************************************************************/
void DMA1_Stream7_IRQHandler(void)
{if(DMA_GetITStatus(DMA1_Stream7, DMA_IT_TCIF7) != RESET)//if(DMA1->HISR & (1<<27)){DMA_ClearITPendingBit(DMA1_Stream7, DMA_IT_TCIF7);//DMA1->HIFCR |= (1<<27);LCD_CS = 1;SPI3->DR; lv_disp_flush_ready(disp_drv_p); /* tell lvgl that flushing is done */}
}在disp_init函数中调用DMA的初始化函数。

修改disp_flush函数
/* Flush the content of the internal buffer the specific area on the display* You can use DMA or any hardware acceleration to do this operation in the background but* 'lv_disp_flush_ready()' has to be called when finished. */
static void disp_flush(lv_disp_drv_t * disp_drv, const lv_area_t * area, lv_color_t * color_p)
{/*The most simple case (but also the slowest) to put all pixels to the screen one-by-one*/// int32_t x;
// int32_t y;
// for(y = area->y1; y <= area->y2; y++) {
// for(x = area->x1; x <= area->x2; x++) {
// /* Put a pixel to the display. For example: */
// /* put_px(x, y, *color_p)*/
// color_p++;
// }
// }unsigned int size = (area->x2 - area->x1 + 1) * (area->y2 - area->y1 + 1) * 2;disp_drv_p = disp_drv;LCD_Address_Set(area->x1, area->y1, area->x2, area->y2+1); LCD_CS = 0;DisPlay_SPI_DMA_Enable(color_p, size);/*不使用DMA的显示方法*/
// LCD_Color_Fill(area->x1, area->y1, area->x2-area->x1, area->y2-area->y1+1, (unsigned short *)color_p);/* IMPORTANT!!!* Inform the graphics library that you are ready with the flushing*/
// lv_disp_flush_ready(disp_drv);
}最后编译;

还有一个错误;

最终编译无误。
lv_port_disp_templ.c 文件最终更改后如下;
#if 1
#include "lv_port_disp_template.h"
#include "lcd.h"#define MY_DISP_HOR_RES 240 //屏的大小
#define MY_DISP_VER_RES 240
static lv_color_t buf_2_1[MY_DISP_HOR_RES * 10]; /*A buffer for 10 rows*/
static lv_color_t buf_2_2[MY_DISP_VER_RES * 10]; /*An other buffer for 10 rows*/static lv_disp_drv_t *disp_drv_p;static void disp_init(void);static void disp_flush(lv_disp_drv_t * disp_drv, const lv_area_t * area, lv_color_t * color_p);/*********************************************************************************************************
* 函 数 名 : DisPlay_SPI_DMA_Init
* 功能说明 : SPI3 DMA1初始化
* 形 参 : 无
* 返 回 值 : 无
* 备 注 : DMA1_Stream7搬运显示数据到SPI3的DR寄存器
*********************************************************************************************************/
static void DisPlay_SPI_DMA_Init()
{DMA_InitTypeDef DMA_InitStructure = {0};NVIC_InitTypeDef NVIC_InitStruct = {0};RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_DMA1, ENABLE); //DMA1时钟使能DMA_DeInit(DMA1_Stream7);while(DMA_GetCmdStatus(DMA1_Stream7) != DISABLE) {} //等待DMA可配置/* 配置 DMA Stream */DMA_InitStructure.DMA_Channel = DMA_Channel_0; //通道选择DMA_InitStructure.DMA_PeripheralBaseAddr = (unsigned int)&SPI3->DR; //DMA外设地址DMA_InitStructure.DMA_Memory0BaseAddr = (unsigned int)buf_2_1; //DMA 存储器0地址DMA_InitStructure.DMA_DIR = DMA_DIR_MemoryToPeripheral; //存储器到外设模式DMA_InitStructure.DMA_BufferSize = sizeof(buf_2_2); //数据传输量DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable; //外设非增量模式DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable; //存储器增量模式DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_Byte; //外设数据长度:8位DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_Byte; //存储器数据长度:8位DMA_InitStructure.DMA_Mode = DMA_Mode_Normal; //使用普通模式DMA_InitStructure.DMA_Priority = DMA_Priority_High; //中等优先级DMA_InitStructure.DMA_FIFOMode = DMA_FIFOMode_Disable; //不使用fifoDMA_InitStructure.DMA_FIFOThreshold = DMA_FIFOThreshold_Full; //fifo全容量DMA_InitStructure.DMA_MemoryBurst = DMA_MemoryBurst_Single; //存储器突发单次传输DMA_InitStructure.DMA_PeripheralBurst = DMA_PeripheralBurst_Single; //外设突发单次传输DMA_Init(DMA1_Stream7, &DMA_InitStructure); //初始化DMA StreamSPI_I2S_DMACmd(SPI3, SPI_I2S_DMAReq_Tx, ENABLE); // SPI3使能DMA发送NVIC_InitStruct.NVIC_IRQChannel = DMA1_Stream7_IRQn;NVIC_InitStruct.NVIC_IRQChannelCmd = ENABLE;NVIC_InitStruct.NVIC_IRQChannelPreemptionPriority = 2;NVIC_InitStruct.NVIC_IRQChannelSubPriority = 2;NVIC_Init(&NVIC_InitStruct);DMA_ITConfig(DMA1_Stream7, DMA_IT_TC, ENABLE);DMA_Cmd(DMA1_Stream7, DISABLE);
}
/*********************************************************************************************************
* 函 数 名 : DisPlay_SPI_DMA_Enable
* 功能说明 : 配置DMA并启动一次传输
* 形 参 : buf:需要搬运的数据的指针;size:搬运的数据量
* 返 回 值 : 无
* 备 注 : 无
*********************************************************************************************************/
void DisPlay_SPI_DMA_Enable(void *buf, unsigned int size)
{DMA1_Stream7->CR &= ~(0x01);while((DMA1_Stream7->CR&0X1)){}DMA1_Stream7->M0AR = (unsigned int)buf;DMA1_Stream7->NDTR = size;DMA1_Stream7->CR |= (0x01);
}
/*********************************************************************************************************
* 函 数 名 : DMA1_Stream7_IRQHandler
* 功能说明 : DMA1_Stream7发送完成中断
* 形 参 : 无
* 返 回 值 : 无
* 备 注 : 无
*********************************************************************************************************/
void DMA1_Stream7_IRQHandler(void)
{if(DMA_GetITStatus(DMA1_Stream7, DMA_IT_TCIF7) != RESET)//if(DMA1->HISR & (1<<27)){DMA_ClearITPendingBit(DMA1_Stream7, DMA_IT_TCIF7);//DMA1->HIFCR |= (1<<27);LCD_CS = 1;SPI3->DR; lv_disp_flush_ready(disp_drv_p); /* tell lvgl that flushing is done */}
}void lv_port_disp_init(void)
{disp_init();static lv_disp_draw_buf_t draw_buf_dsc_2;lv_disp_draw_buf_init(&draw_buf_dsc_2, buf_2_1, buf_2_2, MY_DISP_HOR_RES * 10); /*Initialize the display buffer*/static lv_disp_drv_t disp_drv; /*Descriptor of a display driver*/lv_disp_drv_init(&disp_drv); /*Basic initialization*/disp_drv.hor_res = MY_DISP_HOR_RES;disp_drv.ver_res = MY_DISP_VER_RES;disp_drv.flush_cb = disp_flush;disp_drv.draw_buf = &draw_buf_dsc_2;lv_disp_drv_register(&disp_drv);
}static void disp_init(void)
{/*You code here*/DisPlay_SPI_DMA_Init();
}static void disp_flush(lv_disp_drv_t * disp_drv, const lv_area_t * area, lv_color_t * color_p)
{unsigned int size = (area->x2 - area->x1 + 1) * (area->y2 - area->y1 + 1) * 2;disp_drv_p = disp_drv;LCD_Address_Set(area->x1, area->y1, area->x2, area->y2+1); LCD_CS = 0;DisPlay_SPI_DMA_Enable(color_p, size);
}#else
typedef int keep_pedantic_happy;
#endif根据需求修改lv_conf.h的宏定义;
- LV_COLOR_DEPTH:屏幕的色彩深度,支持1bit、8bit、16bit、32bit。
- LV_COLOR_16_SWAP:字节交换,DMA刷屏的时候需要置1。
- LV_MEM_SIZE:GUI可支配的内存空间,根据使用的功能调节。
- LV_FONT_MONTSERRAT_*:字体大小,太小会很模糊。


如果需要更改默认字体大小,则把相应的宏设置为1.


3、显示实现
配置一个定时器为LVGL提供1ms的时钟心跳,该定时器的中断服务函数中调用lv_tick_inc(1);即可

主程序中调用lv_task_handler();函数处理事件

编写显示程序
#include "lvgl.h"
#include "lv_port_disp_template.h"
void Lvgl_Lable_Demo(void)
{_obj_t *scr = lv_scr_act();
lv_obj_t * label1 = lv_label_create(scr);lv_label_set_long_mode(label1, LV_LABEL_LONG_WRAP); lv_label_set_recolor(label1, true); lv_label_set_text(label1, "#0000ff Re-color# #ff00ff words# #ff0000 of a# label, align the lines to the center ""and wrap long text automatically."); lv_obj_set_width(label1, 150); lv_obj_set_style_text_align(label1, LV_TEXT_ALIGN_CENTER, 0); lv_obj_align(label1, LV_ALIGN_CENTER, 0, -40); lv_obj_t * label2 = lv_label_create(scr);lv_label_set_long_mode(label2, LV_LABEL_LONG_SCROLL_CIRCULAR); lv_obj_set_width(label2, 150); lv_label_set_text(label2, "It is a circularly scrolling text. "); lv_obj_align(label2, LV_ALIGN_CENTER, 0, 40);
}int main()
{
…..
Lcd_Init();lv_init(); // 初始化lvgllv_port_disp_init(); // 显示初始化Lvgl_Lable_Demo();….while(1){lv_task_handler();Delay_Ms(1);}
}4、添加外部中文字体的方法
打开字库生成工具,选择字体,选择TTF字体,加入常用字体,清除重复。目前抗齿距只能使用4,版本选择6.0以上,XBF字体,外部BIN。点击保存可以存出C文件,点击开始转换即可转换出BIN文件。
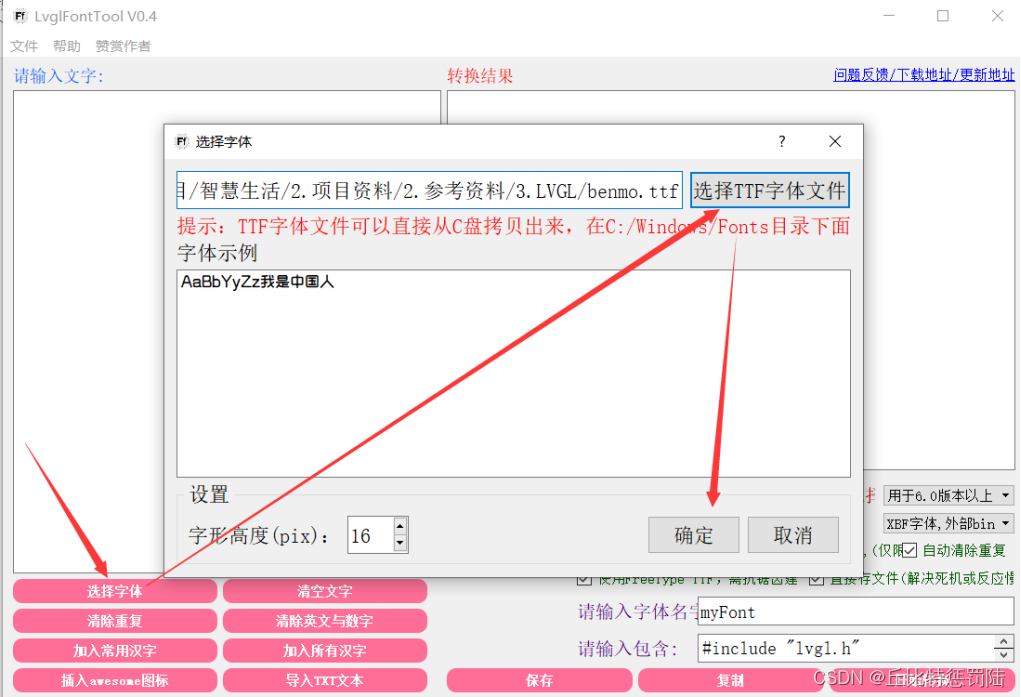
然后点击加入常用汉字à保存à开始转换;
得到以下两个文件;

myFont.bin烧写到自己的SPI FLASH相应的地址。烧写过程你懂的。
myFont.c添加到自己的LVGL工程中并添加自定义的字体
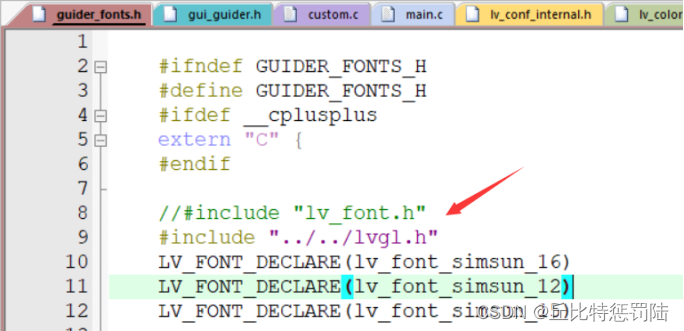
lvgl.h处添加用户字体声明;

将myFont.c中lv_font_t myFont结构体类型加上const修饰,其他需要修改的代码如。


5、编译下载后有几种情况
(1)乱码:抗齿距不是4,多试几种;FLASH读写异常,先测试是否能正常读写。
(2)只有英文:显示中文的C文件编码不是UTF-8,使用软件修改为UTF-8编码后编译报错,在C/C++选项卡中的Misc Controls选项中添加--locale=english
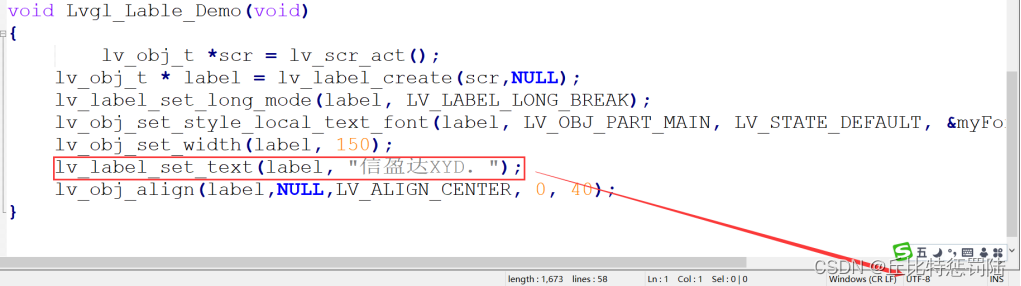

6、调用显示
void Lvgl_Lable_Demo(void)
{lv_obj_t *scr = lv_scr_act();
lv_obj_t * label1 = lv_label_create(scr);lv_label_set_long_mode(label1, LV_LABEL_LONG_WRAP); lv_label_set_recolor(label1, true); lv_label_set_text(label1, "#0000ff Re-color# #ff00ff words# #ff0000 of a# label, align the lines to the center ""and wrap long text automatically"); lv_obj_set_width(label1, 150); lv_obj_set_style_text_align(label1, LV_TEXT_ALIGN_CENTER, 0); lv_obj_align(label1, LV_ALIGN_CENTER, 0, -40); lv_obj_t * label2 = lv_label_create(scr);lv_label_set_long_mode(label2, LV_LABEL_LONG_SCROLL_CIRCULAR); lv_obj_set_width(label2, 150); lv_label_set_text(label2, "It is a circularly scrolling text.中国"); lv_obj_align(label2, LV_ALIGN_CENTER, 0, 40);
}6、GUI-Guider使用
GUI Guider是恩智浦为LVGL开发了一个上位机GUI设计工具,可以通过拖放控件的方式设计LVGL GUI页面,加速GUI的设计。
设计完成的GUI页面可以在PC上仿真运行,确认设计完毕之后可以生成C代码,再整合到MCU项目中。
GUI Guider(Version: 1.3.0-GA)的主要特征:
- 支持Windows 10和Ubuntu 20.04。
- 支持中文、英文。
- 兼容LVGL V7和LVGL V8版本。
- 支持拖放的所见即所得(WYSIWYG)用户界面设计。
- 多种字体支持及第三方字体导入。
- 可定制的中文字符范围。
- 小部件对齐方式:左、中、右。
- 自动产生LVGL C语言源代码。
- 支持默认样式和自定义样式。
- 演示应用程序集成。
- 实时日志显示。
- 集成上位机仿真器。
GUI-Guider会依赖JDK,因此需要安装jdk.
6.1 安装软件
GUI-Guider会依赖JDK,因此需要安装jdk.
6.2 使用软件
1、打开GUI-Guider-1.3.0-GA软件;
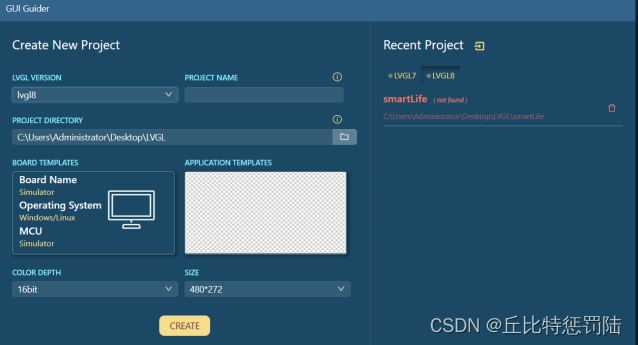
2、创建工程;
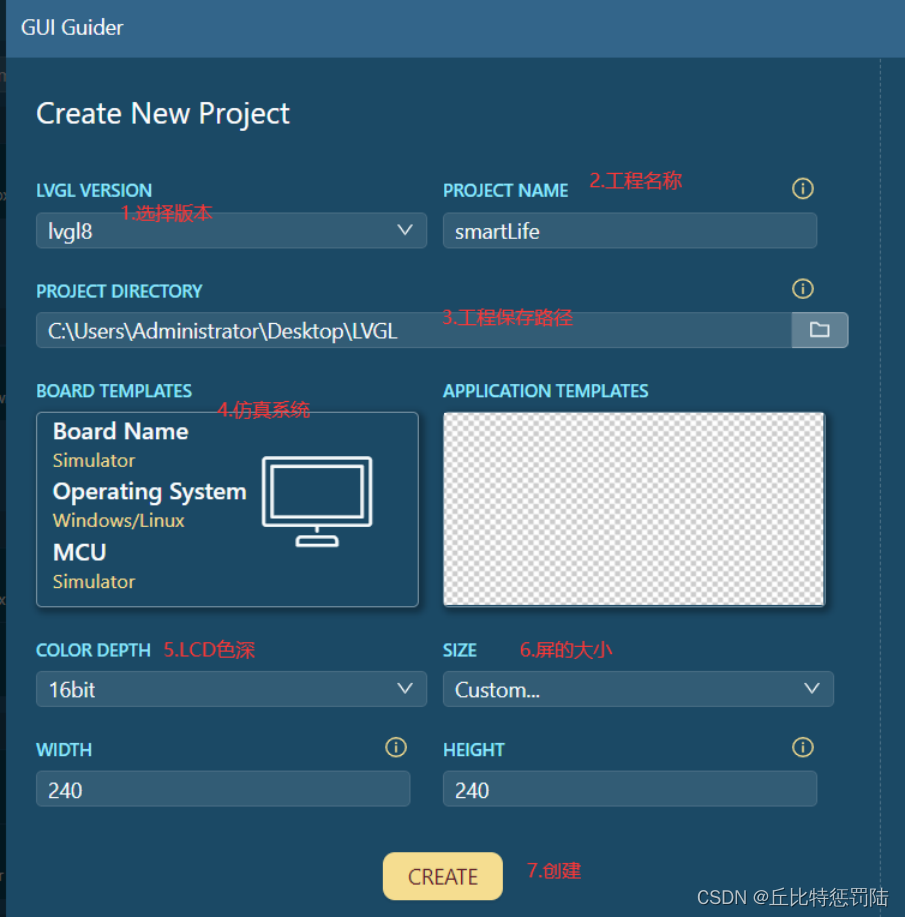
3、创建完成进入设计界面;
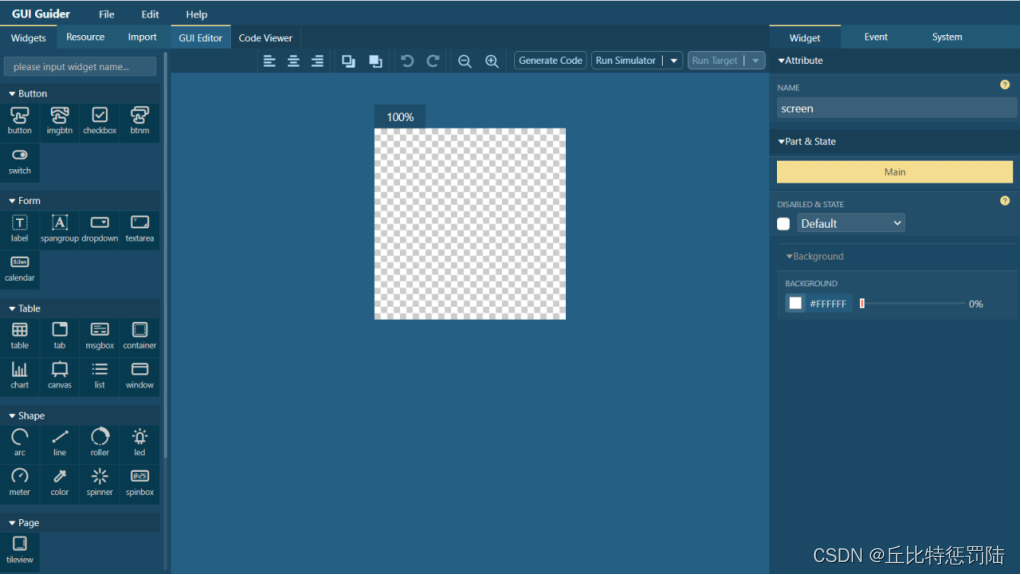
左侧是组件区,中间是设计区,右边是控件地属性设置区。按照自己需要设计GUI页面,
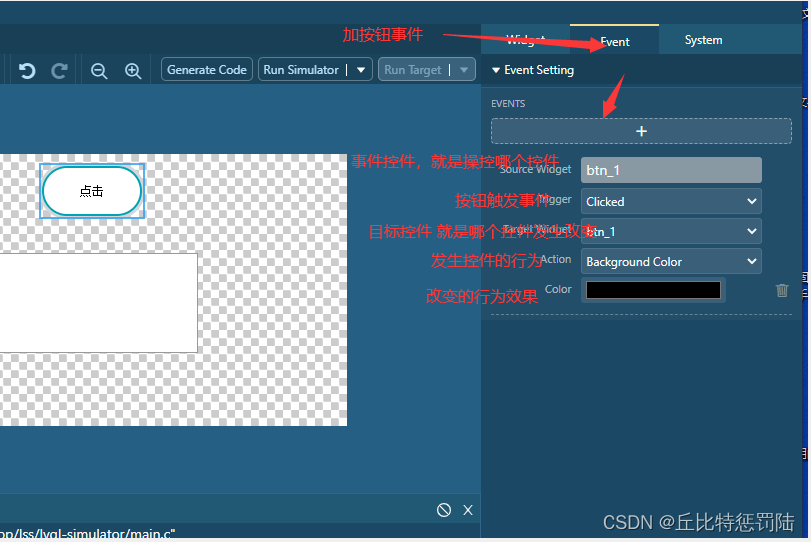
上图事件功能是按下按钮是把按钮的背景改为黑色。
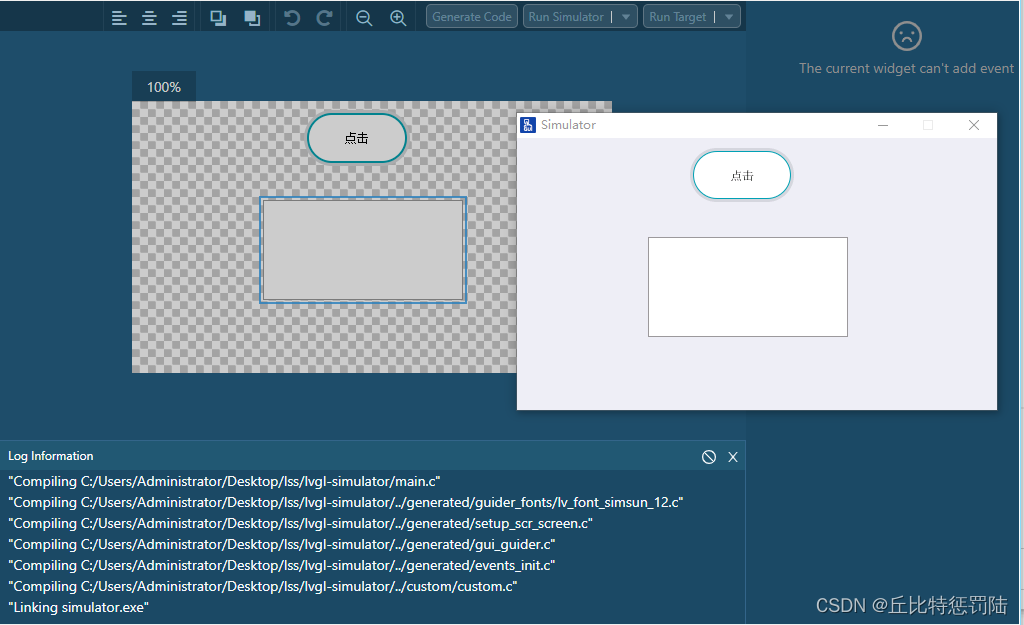
运行模拟器预览一下效果
没问题之后就可以生成代码(记得先保存工程),在Guider中也可以在代码窗口查看生成的代码.
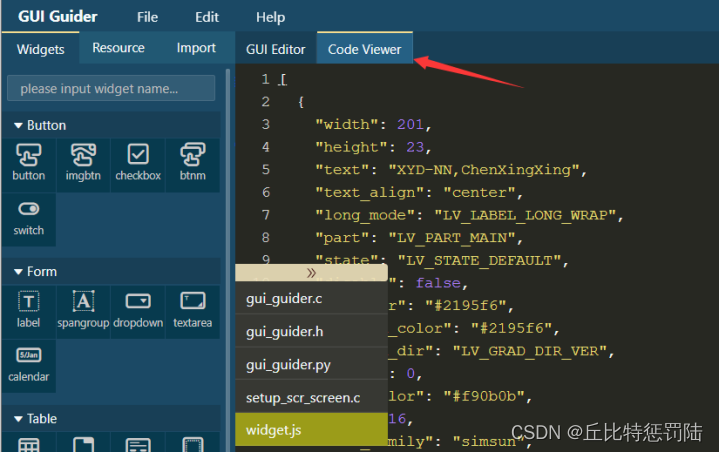
生成的代码在Guider工程目录的generated和custom文件夹下

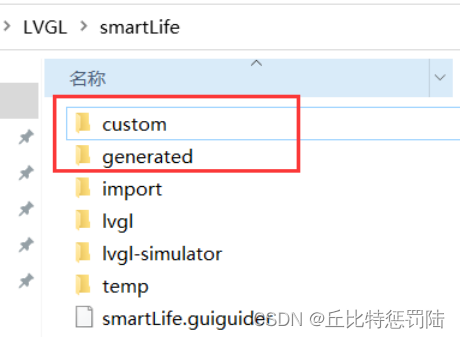
6.3 移植到STM32
把generated和custom文件夹工程整个复制到我们的keil工程目录中:
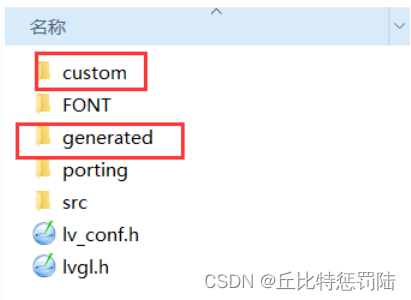
添加generated和custom文件夹相关源文件;
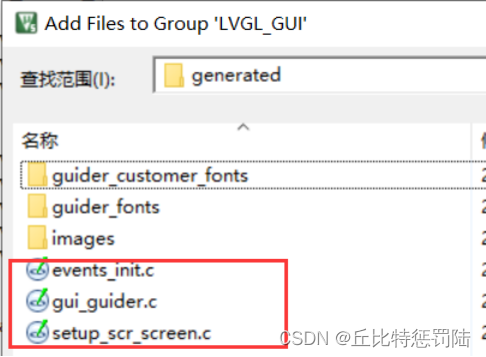
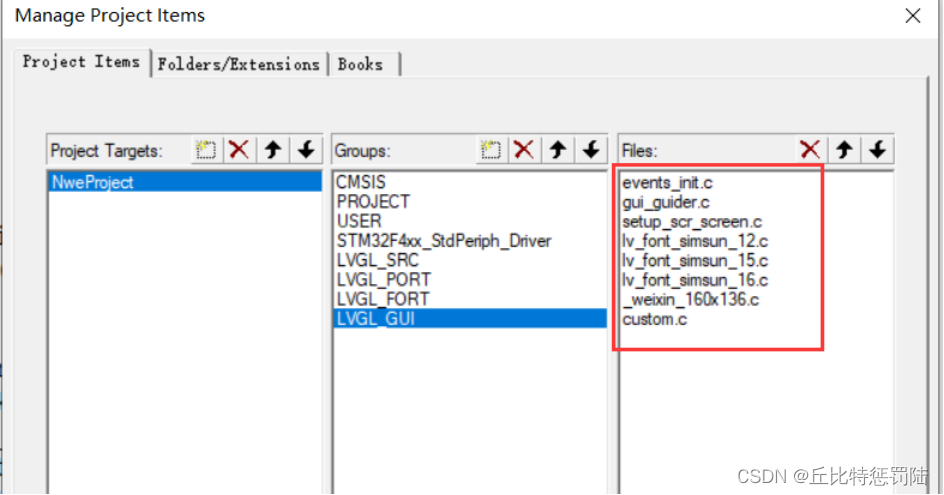
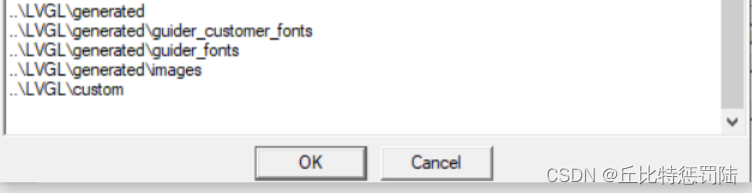
添加头文件路径
编写测试代码

更改错误:一般都是头文件路径不对,哪里不对改哪里。比如