绍兴专业做网站的公司模拟wordpress
本节前言
在写作本节的时候,本来呢,我正在写的专栏,是 MFC 专栏。而 VS2010 和 VS2019,正是 MFC 学习与开发中,可以使用的两款软件。然而呢,如果你去学习 Windows API 知识的话,那么,这两款软件,你也是可以使用的。
所以呢,本节的内容,我既把它放在 MFC 专栏里面,也把它放在 Win32 API 专栏里面、
说起来的话,MFC 也好, Win32 知识也好,这都是一个体量比较大的学科。所以呢,需要大家能够耐下心来,好好地来学习这样的两个科目。时间呢,肯定是需要一些的。
这两本教材,每一本,都是1000多页的东西。它本身的内容的量,就很大。同时呢,有很多的章节,难度呢,又很大。所以呢,想要学习这么两个科目,它不是一件轻松的事情。可是呢,如果你能够将它们俩,都给学习下来,那么,这对你的编程能力的提升,相信会是一个很好的助力。
加油啊。
下面,我们开始本节内容的讲解。
一. VS2010 的下载与解压缩
Visuai Studio 软件,它是一个IDE 工具,可以用来编译 C/C++,MFC, C#等等的好多的东西,它功能非常强大。然后呢,平时,我们在称呼这个软件的时候,也常常将其简称为【VS】,这是选取了【Visual Studio】两个单词的首字母,而形成的简称。
另外呢,我们还常常会加上版本号,2010版的【Vsual Studio】软件,我们常常将其称作是 【VS2010】。同理,2012,2013,2015,2017版本的【Visual Studio】软件,我们会分别将其称作【VS2012】,【VS2013】,【VS2015】,【VS2017】。
本节呢,我们要去下载和安装的,是【VS2010】。
下面,我给出一个网盘链接。
链接:https://pan.baidu.com/s/1BmqNW4mVqddW12JI_Q7MVQ
提取码:yhql
--来自百度网盘超级会员V4的分享
提取码就是一个密码,你点击了连接以后,想要获取里面的资料,就需要输入提取码。
链接里面的内容,是我自己,在我的网盘里面,设置的一个共享文件夹,叫做【水饺共享包】。这个共享文件夹,我是打算永久设置的。但是呢,里面的文件组织结构,有可能,以后,我会去调整。但是呢,水饺共享包本身,我是打算长期设置的。
如果你在阅读本文的时候,你按照我所指示的路径,没有获取到对应的课件,那么,你可以来联系我的。
进入了水饺共享包以后,我们需要依次点击进入以下的文件夹。
【Windows编程】,【软件】,【Visual-Studio】,【VS2010】,进入里面以后,在【VS2010】文件夹里面,有一个名为【cn_visual_studio_2010_ultimate_x86_dvd_532347.iso】的文件。这个便是我们本节所说的【VS2010】软件的安装包。
你需要把这个安装包给下载回去。
下载回去以后,你还需要去打开它。怎么打开呢?
我这里,经常使用的一个方法,就是使用解压缩软件,将其解压缩。
在电脑端,我本人经常使用的压缩与解压缩软件,是【2345好压】。你可以选择使用这个解压缩软件,也可以选择使用其他的解压缩软件,将我们本节分享的安装包,给解压缩。
注意,解压缩的目标路径,最好是不要含有中文,空格以及其他的特殊字符。
我们在下载和安装一些个软件的时候,常常遇到说,某些软件,要求安装路径中不能够含有中文。实际上,有的软件的安装路径中,是可以有中文的,有的则不允许有中文,空格等特殊字符。在这里,我也不清楚【VS2010】的具体要求。
在不清楚具体要求得情况下,我们尽量地按照严格一些的标准来作要求,保证你的安装包的解压缩的路径中,不含有中文,空格等特殊字符,那么,不论软件本身的要求是宽松还是严格,我们都可以符合要求,还省去了区分是否允许含有中文与空格的麻烦。
在这里,下载与解压缩,我就算是讲完了。接下来,我要来谈一谈安装方法了。
二. VS2010 的安装
解压缩以后,解压后的文件夹里面的东西有好多。我们来看一下。
然后呢,我们重点需要关注的,是如下图所示的两个东西。
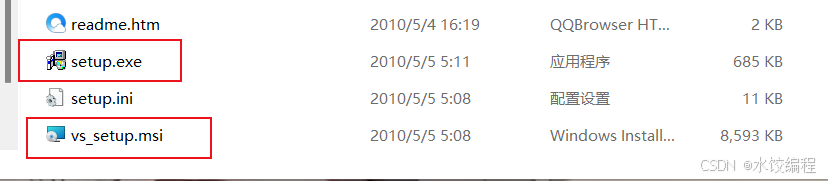
如图2中的红色框线所示,有两个文件,我们需要重点关注。一个是【setup.exe】,另一个,是【vs_setup.msi】。这俩文件,双击它们,都可以用来安装 VS2010 。
在这里,我们选择【setup.exe】,双击它,弹出如下界面。
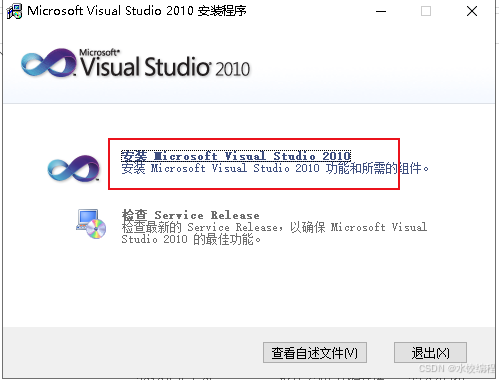
在图3所示的界面里,我们单击红色框线所示的选项。
过一会儿,会弹出如下图所示的界面。
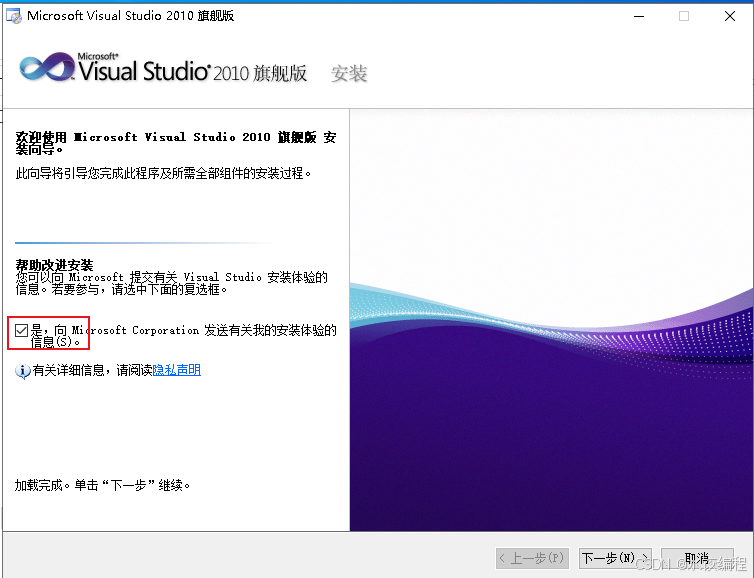
在图4里面,我们点击红色框线所示的复选框,将复选框里面的对号给取消。然后呢,鼠标单击右下角的【下一步】按钮,结果如下图所示。
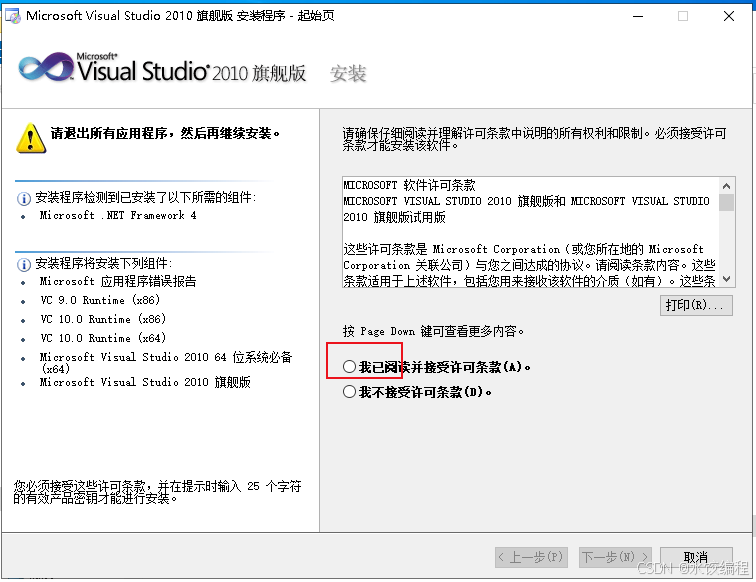
在图5所示的界面里,我们点击红色框线所示的单选按钮,将其选择上。然后呢,我们再去点击右下角的【下一步】按钮。结果如下图所示。
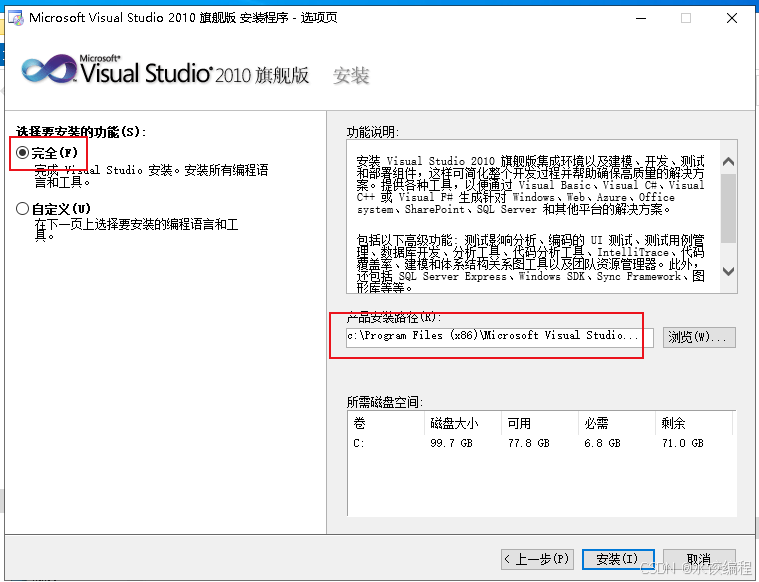
在图6所示的界面里,首先呢,我们点击左侧的红色框线所示的单选按钮。这个单选按钮与它下面的【自定义】字样的单选按钮,是两种安装方式。其中,红色框线所示的【完全】方式,它是说,将VS2010的所有组件,都给安装上。而下面的【自定义】单选按钮,它是说 ,我们可以自己根据需要,来选择安装的组件。
在这里,VS2010 的体积,相比于后来的 VS2017, VS2019等等,要小得多。所以呢,我们将其完全安装下来,就可以了。所以呢,我们选择点击左侧的红色框线所示的【完全】安装方式,以将VS2010的全部的组件,都给安装上。
然后呢,我们还得来看一看右侧的红色框线的位置,它是问你,要将VS2010安装在什么路径。
关于安装路径,一般地,我们自己在安装应用软件的时候,都会将其安装在C盘以外的硬盘分区里面。在我这里,我是在自己的虚拟机里面,来进行演示的。我的虚拟机 ,里面只有C盘一个分区。而大家的物理电脑上,一般的呢,都会至少有两个分区。除了C盘之外,至少地,你还会有一个D盘、
建议呢,将安装路径中的C盘盘符,改为其他盘的盘符。比如D盘,或者E盘啥的。选择盘符的时候,
当前呢,图6里面显示的路径,为【c:\Program Files (x86)\Microsoft Visual Studio 10.0\】。我们呢,可以点击一下图6的右侧的红色框线所示的输入框,将左边的【c】改为【D】或者【E】。在我的演示里,我将其改为【D】,形成的新的路径为【D:\Program Files (x86)\Microsoft Visual Studio 10.0\】。这样一来呢,路径,我们就改好了。
修改路径的盘符的时候,还需要注意,你的安装VS2010的目标盘符的所在分区,它的剩余空间,足够用来安装VS2010。
从图6来看,在右下角,有一个显示区域,显示了VS2010所需的空间,是6.8G,我们的虚拟机,当前可用的空间,是77.8G,足够用来安装VS2010了。
点选了左侧的红色框线所示的【完全】单选按钮,并且在右侧的红色框线所示的文本框里面,修改好了盘符,设置好了安装路径以后,我们点击右下角的【安装】按钮。
安装过程比较漫长。如果你是用笔记本来安装的话,简易你最好播放一个视频,防止电脑中途睡眠。经过一段时间,软件会完成安装。完成了以后,弹出如下图所示的界面。
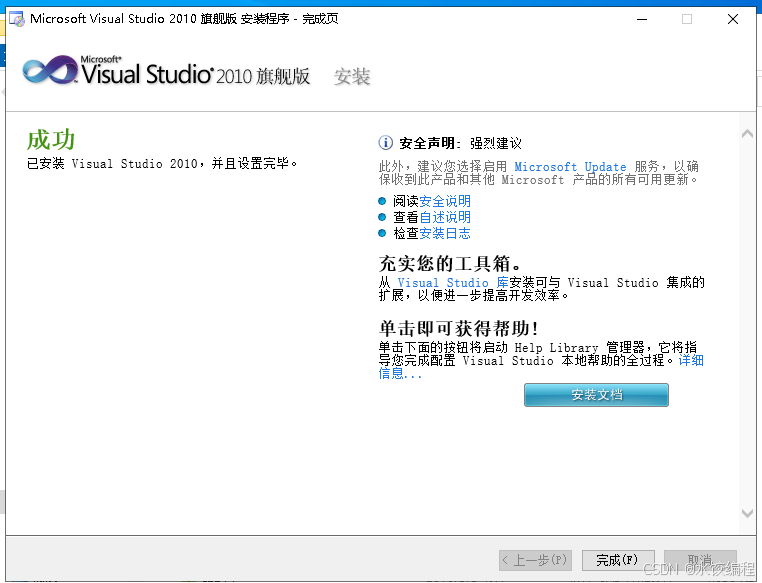
在图7所示的界面里,点击右下角所示的【完成】按钮。
略等一会儿,会弹出下图所示的界面。
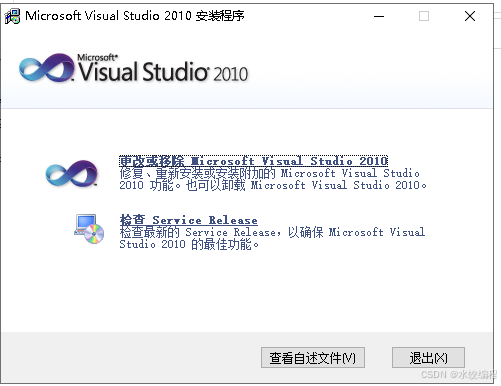
在图8里面,点击右下角的【退出】按钮。
到这里为止,我们就算是安装完 VS2010 了。不过,我们还需要运行一次 VS2010 。
三. 首次运行 VS2010
点击桌面上的开始按钮,然后找到【Microsoft Visual Studio 2010】文件夹,点开它,在里面找到【Microsoft Visual Studio 2010】选项,如下图所示。
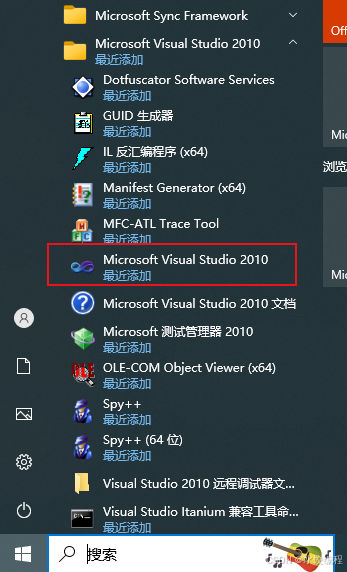
点击红色框线所示的【Microsoft Visual Studio 2010】选项,启动 VS2010 。略等一会儿,会弹出如下图所示的界面。
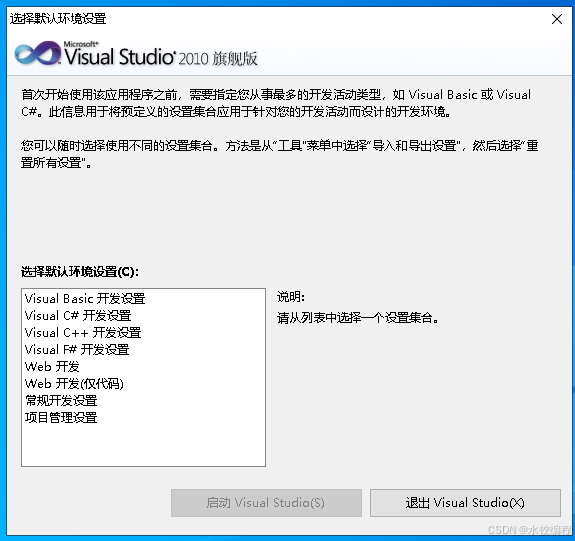
在图10左下角,有一个选择框。选择框上方,是【选择默认开发环境】的字样。在这个选择框里面,点击选择【Visual C++开发设置】,然后单击左下角的【启动 Visual Studio】按钮。启动过程要花费一点时间,过一会儿功夫,软件启动,如下图所示。
我们点击软件右上角的关闭按钮,关闭软件,就可以了。
四. 安装 VS2010 的理由
也许,会有人有疑问,在我写作的当前,是2025年。在这个时候,最新的 Visual Studio 软件的版本为2022版。相比 2022版软件,VS2010就显得太旧了。
为啥要去安装这么旧的 VS2010 呢?
我在学习 MFC 教材与 Win32 教材的时候,教材的写作年份,都是1999年左右。这个时候,Microsoft Visual C++ 6.0 还在盛行着。
VC++ 6.0 是一个很旧的软件。它在Windows XP系统上,可以流畅稳定地运行,而在Win7 系统上,已经是有了兼容性问题了。在Win10系统上,它就更是会有兼容性问题了。
用较新的版本的 Visual Studio 软件去运行1999年左右的教材的代码,有的时候,会出现运行不了的情况,这是因为,1999年的教材的内容,有部分的内容,还是显得太旧了。VS2017,VS2019,这俩版本的软件,去运行着我们本专栏所依据的1999年的 WIn32与 MFC 教材的代码,都可能会有着兼容性的问题。
可是,如果我们选择用VS2010来编译运行1999年版的 Win32 与 MFC 教材,则基本上是没有代码的新旧版本的兼容性问题的。
而VS2010软件,它既可以运行在Windows XP系统上,也可以运行在 Win7,Win10 和 Win11 系统上。
这样一来,VS2010,可以在新旧Windows系统上,运行着1999年版的Win32与MFC教材的代码,所以,我们是需要安装 VS2010 软件的。
然而,在讲解 Win32 与 MFC 的内容时,我并不打算以 VS2010 作为主要的开发工具,我会以 VS2019作为主要的操作软件。然而,对于某些代码,我还是会采用 VS2010,来编译运行代码。
结束语
本节的内容不难。
以后,渐渐地,我们会遇到一些个难点知识。
希望大家能够学习好 Win32 与 MFC 的知识。