电商网站开发详细流程福州直播app开发公司
目标:主域名 imps.com 已完成配置,新增配置 kpi.imps.com 等二级域名并指向 8083 端口。
(此操作需要主域名已经通过备案3天后,最好指向的IP地址网站也通过了备案申请,否则会提示域名没有备案。)
操作流程:
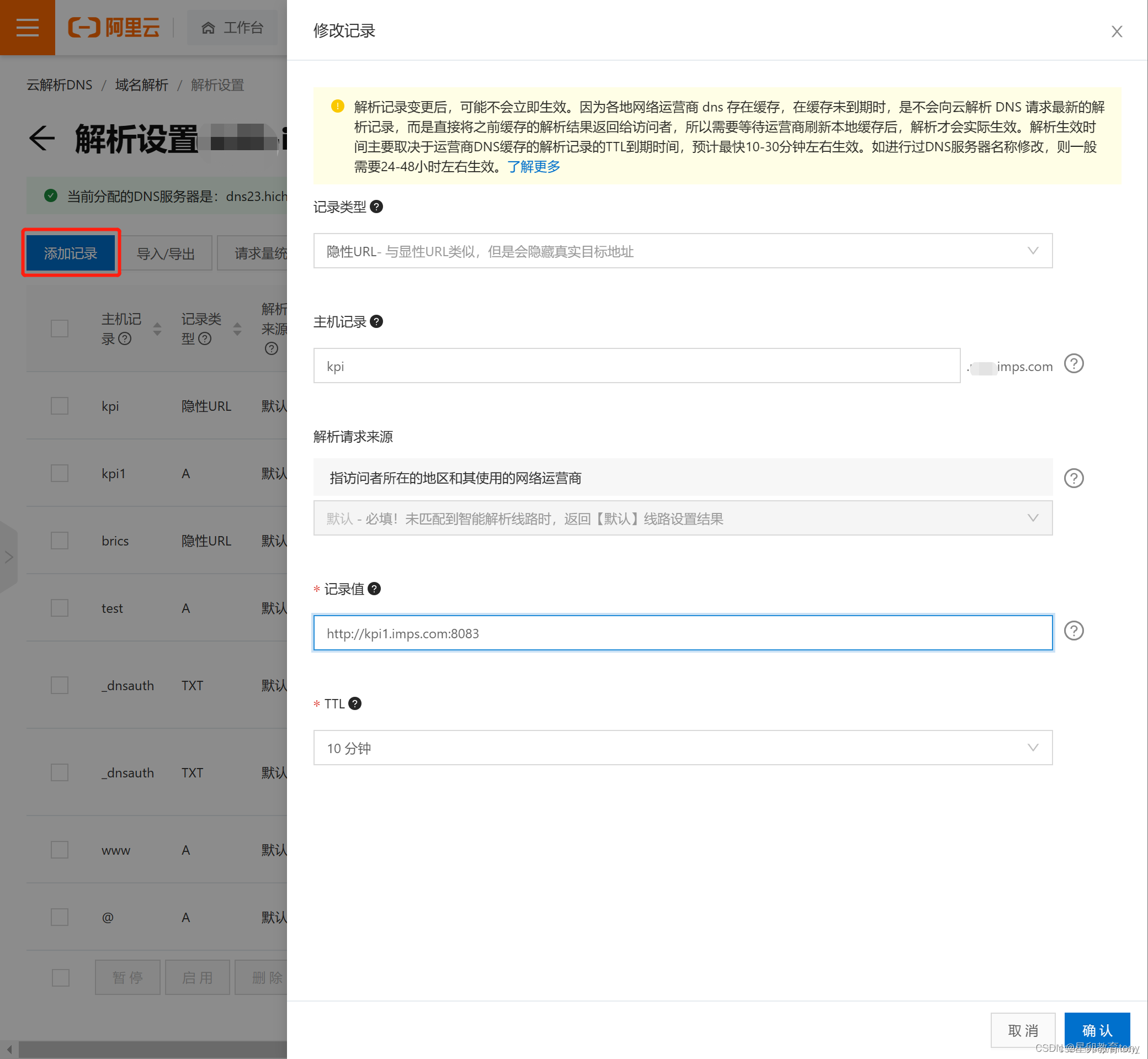
1.点击“添加记录”,新增记录配置如下:
记录类型:A
主机记录:kpi1(注:此处可配置任意字符)
解析请求来源:默认
记录值:主域名对应绑定的IP地址
TTL:默认值即可
2.再次点击“添加记录”,新增第二条记录配置如下:
记录类型:隐形URL (默认A记录 点开向下选择)
主机记录:kpi(此处配置想要的二级域名字符)
解析请求来源:默认
记录值:https://kpi1.imps.com:8083(kpi1 为第一条记录配置的“主机记录字段,8083 为二级域名希望解析到的其他端口) 主意 kpi1 和 kpi 的区别 ,相当于是个跳板。
TTL:默认值即可
3.配置完成,等待几分钟后二级域名 kpi.imps.com 可解析并解析到新的端口。
操作流程图以阿里云为例(腾讯云一样):
1.