湖南衡阳网站建设3e网站建设
find命令:

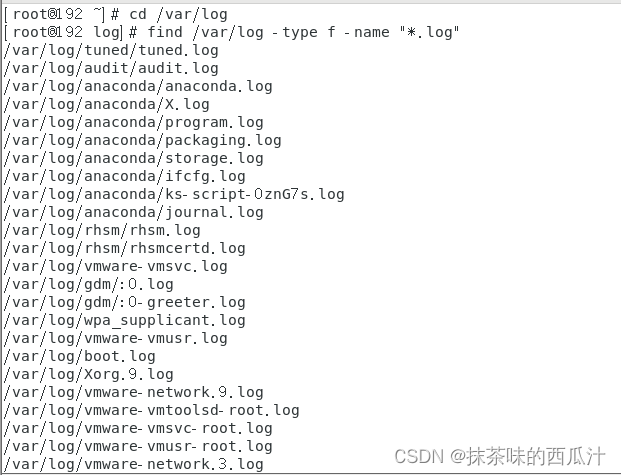
d查找目录:
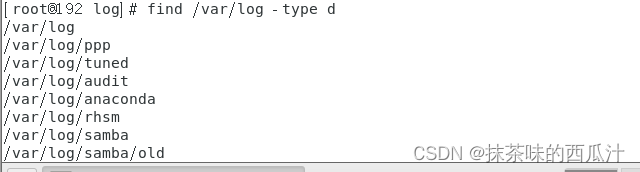
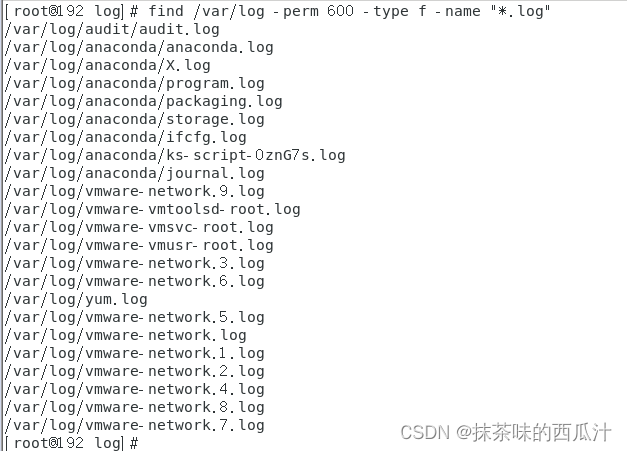
按照文件权限查找:
600全部权限:
-user根据所属主:
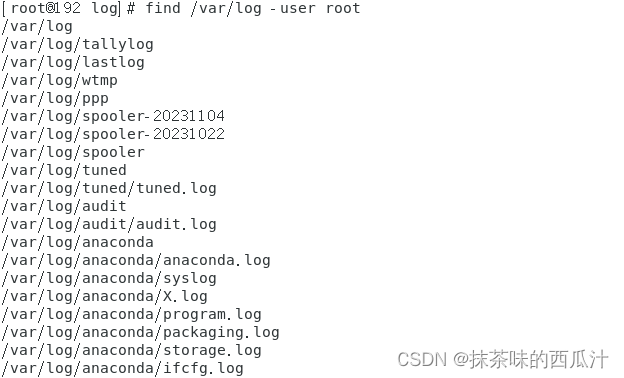
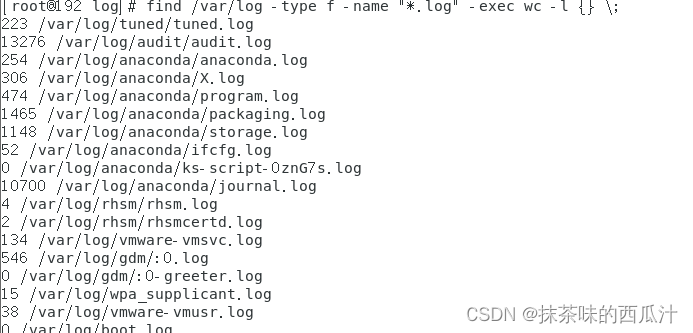
上面的例子是找出文件并打印有多少行。
我们也可以把我们查询到的结果复制到其它文件位置中去:

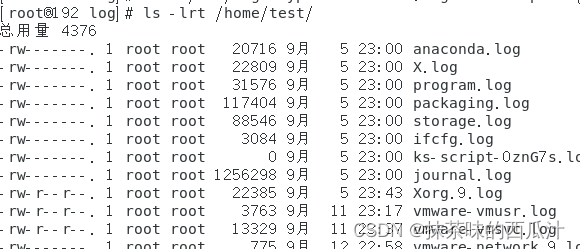
复制成功。
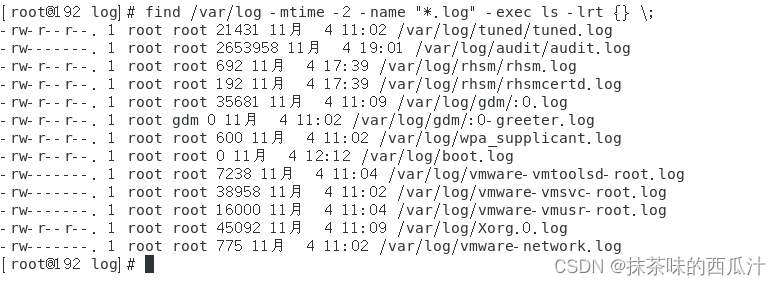
-mtime根据修改时间查找:
查找两天内修改过的文件的详细信息:
防火墙以及selinux介绍:


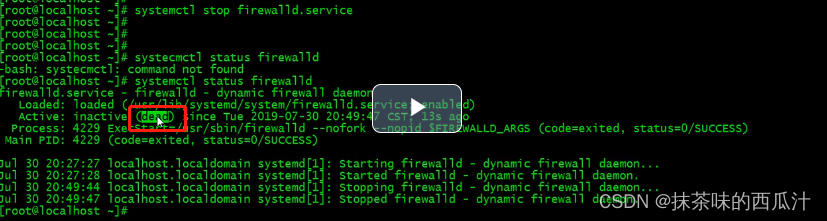
查看服务状态:

关闭,开启,重启防火墙:
开启和重启分别使用:start和restart命令。

也可也使用这种方式查看防火墙的状态。

有时候我们会使用到telnet命令,我们要先去进行下载:

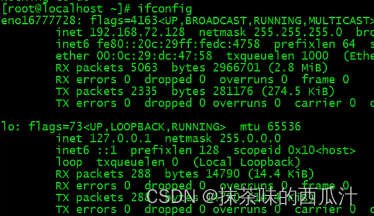
if config也可以查看ip地址。也可以使用 ip addr命令。
我们先去查看80端口是否占用:

发现80端口是占用着的。

在新的一台服务器里我们发现我们的80端口是没有连接的。
![]()
我们把之前的防火墙关闭。

这样另一个服务器的80端口就可以使用了。
开放80端口:
firewall-cmd --permanent --add-port=80/tcp
![]()
- firewall-cmd -permanent --list-port 查看某个规则下开放的端口列表
![]()
每次我们对端口进行修改,要记得使用reload去重新加载:

查看指定端口是否开放:

关闭80端口:

以上就是防火墙的简单使用,查看防火墙状态,打开,关闭防火墙。添加端口,查看端口是否开发,关闭端口。
我们想对端口进行操作,必须保证想要操作的端口是监听的,netstat -tunlp 能查到的才可以操作。
telnet和scp命令:


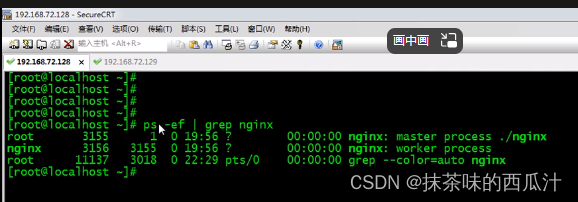
这台机器上配置了一个nginx系统。
在页面直接访问是访问不了的。
curl localhost 80 本机访问80端口
![]()
那遇到这种本机可以访问,外部访问不了的情况,我们应该怎么做呢?
工作中也时常会出现这种情况。
目前我们确定网络是通了的。

在cmd上我们可以断定是80端口出现了问题。不然它是可以一直出现连接信息的。

我们发现防火墙是关闭着的。
我们打开防火墙:

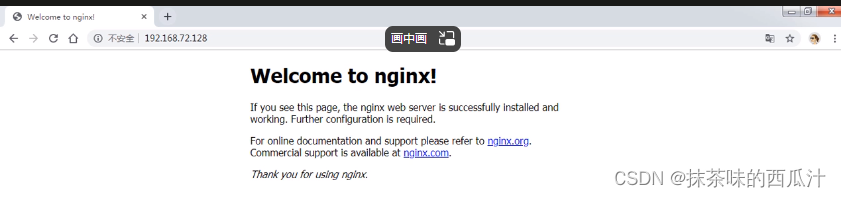
现在我们发现可以访问到nginx了。
笔记中有教我们安装的方法。
scp命令:
用于服务器之间文件或文件目录的拷贝。
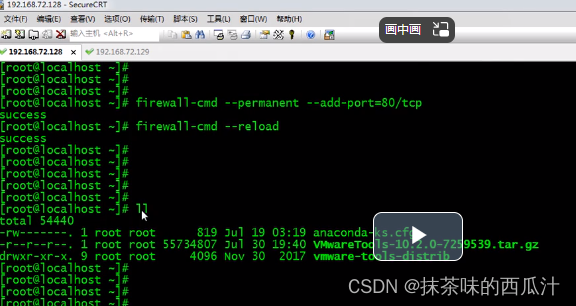
我们现在想把128服务器中的内容拷贝到129服务器中去。

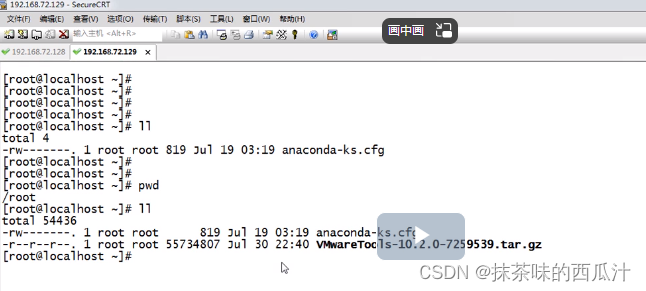
这样就拷贝成功了。
除了这样以外,还有第二种用法:
还可以把别的机器上的内容拷贝到本机上来:
还可以使用-r参数进行递归:

使用-r可以对目录进行拷贝。
ps-ef命令
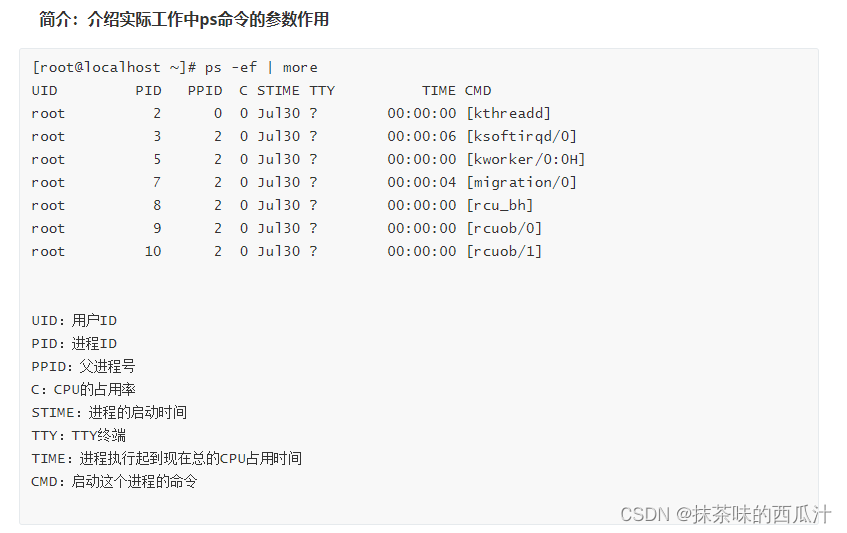
ps -aux:
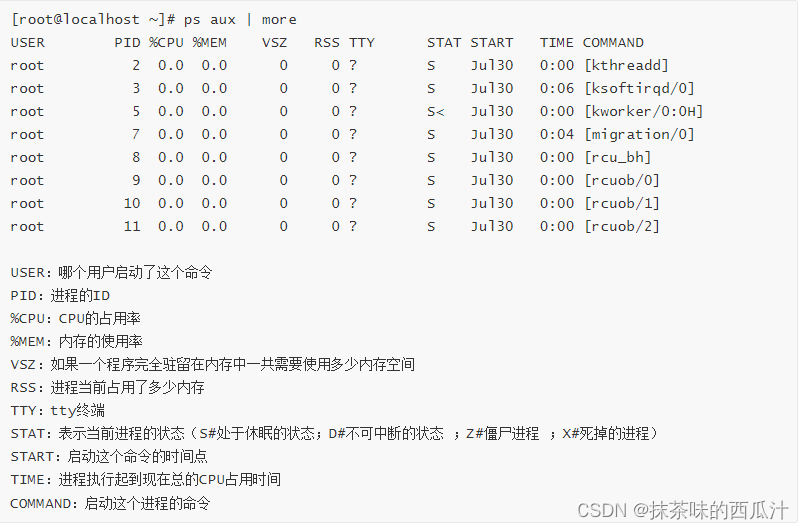
一般执行ps -ef 或者ps aux 命令是查看我们的进程是否启动成功,或者找出进程号,对进程的kill强制关闭.

可以查看到进程是否启动成功。