响应式网站尺寸微信公众号怎么创建步骤
详细介绍
PdfFactory,PDF文档虚拟打印机,无须Acrobat即可创建Adobe PDF文件,创建PDF文件的方法比其他方法更方便和高效。支持将多个文档整合到一个PDF文件、增加字体和便签、PDF加密、去水印、压缩优化。
FinePrint,Windows虚拟打印机驱动程序,控制和增强打印输出节省墨水、纸张和时间。支持整合打印,双面打印、多页打印、装订线支持、PDF水印、表单和信笺、通过FinePrint节省纸张和墨水,节省打印时间。
功能特色
pdfFactory 产品提供了比其他程序更简单、更有效率和更少的花费的创建 PDF 文件的解决方案。pdfFactory标准版本用来创建 pdf 文件,专业版用于需要安全的PDF(法律文档、公司信息等)和其他高级功能的用户。
• 创建 PDF 和打印到纸上: 仅 pdfFactory 允许不用打印两次而打印到纸上和 PDF 文件中。打印不需要 Acrobat。
• 多个文档整合到一个 PDF 文件中:通过创建一个包含多个内容的单独的 PDF 文件,增加了交换的方便。这个功能是自动的。
• 预览: 允许快速、精确地预览 PDF,包括 400% 缩放,不需要先保存文件也不需要用 Acrobat 打开。
• 预览:允许改变加密,内嵌字体,链接处理和书签而无需重新打印原始文档。
• 内嵌字体:确保文档中使用的原始字体能被正确显示,即使接受者的计算机中没有安装相应的字体。
• 页面插入和删除:允许在 PDF 文件创建前删除不必要的部分。这对于从一个长的报告、E-mail 和 web 页创建 PDF 文件有用。
• 通过 E-mail 发送:把 PDF 文件使用默认的 E-mail 客户端发送 。
• 自动保存:自动保存 pdfFactory 打印过的完整内容,所以你可以重新得到以前打印完成得 PDF 文件。
• 动态 URL 链接:自定义类型、下划线和颜色的链接,单击你的鼠标来打开网页和 Email 地址。
• 简单的服务器部署:在服务器上做为共享打印机安装,请查看我们的 服务器版本。
• 书签和目录表: 自动或手动创建书签来在复杂文档中管理和导航。页码,页眉,页脚和水印: 可根据需• 要增加文档的页码,页眉页脚及水印。
• 创建PDF信笺: 专业版中您可以把您的文档保存成信笺,进而应用到不同文档中。
• 整合的任务标签: 显示所有任务并允许你重新排列它们。
• 自定义驱动: 把你的配置保存为多个打印机驱动,所以你对指定任务能快速选择它们。
• 设置初始 Acrobat 显示属性: 例如缩放比例、层和标签配置。
pdfFactory Pro8破解版安装教程
1、在本帖下载并解压,得到如下文件(下载地址文章底部)

2、双击运行开始安装原程序,进入安装向导,选择简体中文语言,进行下一步;

3、勾选我接受许可协议

4、软件安装中,请耐心等待

5、软件安装完成,勾选显示图标桌面上,点击完成,退出安装向导

6、选择桌面快捷方式右键-属性-打开文件文件位置,将破解补丁复制到安装目录下,选择替换目标中的文件

7、打开软件,任意输入名称,和序列号“M5X6U-HX4UW-UYTWE”点击确认

8、软件破解完成

如何使用pdfFactory Pro虚拟打印机打印PS制图
一、打开路径
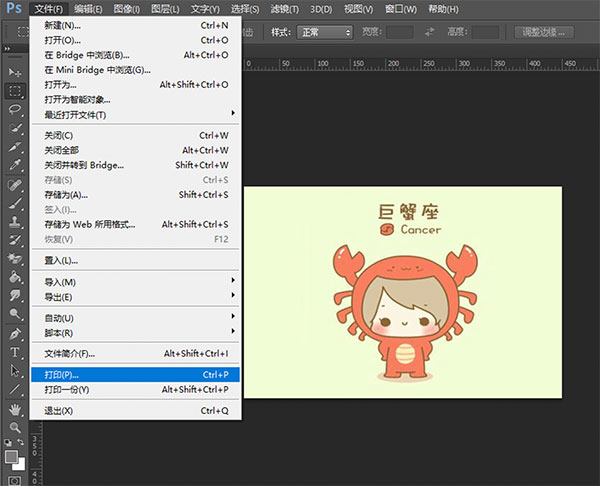
将图片于PS内打开,或者使用PS制图完毕后,通过“文件——打印”路径打开PS的“打印设置弹窗”

PS的打印设置弹窗可设置内容较多,这里介绍三部分内容,一是打印机的选择,打印份数以及打印的纵横方向;二是“打印标记”,在这里可以设置一些角裁剪标,添加说明等内容,便于打印后的裁剪工作;三是“函数”,主要是呈像效果,“药膜朝下”为镜像打印,“负片”为“胶片底板呈像”。
简单设置后单击“打印”,便可将图片导入pdfFactory Pro虚拟打印机。
导入虚拟打印机后,看看pdfFactory Pro虚拟打印机能做哪些调整吧。
二、虚拟打印机设置图片
1、调色

图片导入pdfFactory Pro虚拟打印机后,勾选左侧“作业”栏内“灰度”可将彩色图片变为黑白色,勾选“变浅”,并调整滑动按钮,可调整图片的色泽深浅。向左滑动式颜色加深,反之颜色变浅。
2、调整尺寸
为了节省资源,还可利用“快照”工具移动图片。

首先,使用“快照”工具圈定图片,再使用“箭头”工具按住被圈定图片,拖拽移动即可。

鼠标为“快照”工具状态时,按住四周其中一个触控点,拖拽图片可调节图片大小。按住图片顶部“旋转按钮”进行移动,可调整图片显示的倾斜程度。
软件下载与注册码
pdfFactory/FinePrint百度网盘: https://pan.baidu.com/s/1kcp4rB1zeLMshqwr7qGjSA?pwd=mmv5 提取码: mmv5
pdfFactory:AHMST-YMMYZ-K10TF (工作站版)XHXNK-T84R5-3ZB5Q
如果注册码失效了,或者无效,估计被他人使用过,请移步百度网盘下载
pdfFactory Pro 8/FinePrint11注册码:https://pan.baidu.com/s/1d-TkPKuYyZ6gFRMrRiga5A?pwd=hbyy 提取码:hbyy

希望我的回答对你有帮助!!!