企业建设网站是网络营销吗免费推广网站58
近期,围绕 Aptos 和 Sui,新兴的高性能 L1链 以及这些新链背后的 Move
智能合约编程语言引起了很多关注,社区也非常活跃,很多开发者和项目已经开始积极转向
Move。但Move相对Solidity差别较大,即使是相对比较接近的Rust也有很多不同。那么,如何才能用Move开发出优秀的Dapp,如何才能保障合约和业务的安全?这是一个至关重要的问题。
SharkTeam将就 Move合约开发和合约安全进行深入探讨。这是第一部分,我们重点聊一聊 Move 合约开发。
** 1 Move 发展史**
Move 是一种新型编程语言,是 Meta(原 Facebook)公司为其 Diem 项目开发的一种安全可靠的智能合约语言。
2019年,Meta(原 Facebook)公司发布了全球流通的稳定型数字货币项目 Libra,并且为其设计开发了一种安全可靠的智能合约语言 Move。
2020年12月,Libra 突然宣布更名为 Diem并确认将在2021年初上限。同时原 Libra 协会也更名为 Diem
协会。随后因监管限制被迫转型,最终,在2022年初1月选择出售,Diem 无疾而终,其加密货币的梦想宣告破灭。
虽然 Diem 项目没有给行业带来大的机会和改变,但其遗产—— Move 开发语言却引起来项目方和开发者的关注。原因是 Move 语言相比于
Solidity 更加适用于数字资产的开发,并且安全性更高,一定程度上弥补了 Solidity 和 EVM
中的漏洞和缺陷。由Move语言衍生出来的公链生态方兴未艾,比如 Aptos、Sui、Linera、Starcoin等。
** 2 Move 语言特性**
我们总结了Move语言的6大特性,如下:
(1)一等资源与数字资产
(2)权限分离与可操作性
(3)模块与灵活组合性
(4)泛型与编程灵活性
(5)形式化验证机制
(6)静态调用与虚拟机沙盒
** 2.1 一等资源与数字资产**
Move 语言是面向资源的语言,其面向资源的理念则是 Move 语言最受关注的地方。Move
可以自定义资源,资源具有可编程性和安全性。开发者可以通过编程自定义资源,真正意义上实现了独一无二的数字资产。
相比于 Solidity
中定义的资产只是一个数值,资产不具备独一无二的特性,更不具有唯一的特性,即仅仅实现了数字化,没有实现数字资产化。比如,Solidity 发行一种
Token,部署一个 Token 的合约,为一个账户 A 铸造一定数量的 Token,实际上只是在 Token 合约中为账户 A 赋予一定的值。而转账,比如
A 转账给 B,则是修改 Token 合约中账户 A 和账户 B 的值,即减少 A 的值同时增加 B 的值。
Move 创建资源 Token 后,为账户 A 铸造代币,则是创建 Token 资源并保存在 账户 A 中,该资源是独一无二的,只有账户 A
具有操作权限,真正实现了数字资产化,而不仅仅是数字化。
Move中的资源包含了 3 中特性:
(1)以数值形式表示数字资源的某些数值属性,比如,资源内部以数值的形式,表示数字货币的数量,作为数据结构被存储,可以作为参数以及返回值,类似于
Solidity 中的结构体;
(2)独一无二的数字资产,即不能复制、丢弃或重用,可以被安全地存储和转移,并且只能由定义该资源的模块进行创建和销毁,这种形式的资源实现了真正意义上的数字资产,而完全区别于
Solidity 中数值表示数字资产。这给让数字资产在创建、使用以及销毁的过程中更加安全,不会凭空产生、增减以及丢失,更可以避免 Solidity
中的重入漏洞。
(3)资源的存储和读取与账户绑定。资源被创建后,如果不销毁,则必须存储到某个账户下面,被取出后必须被使用。因此,只有分配了账户,才能够持有对应的资源,然后才能对资源进行操作。另外,读取账户中的资源时,可以选择不可变和可变两种类型,限制对资源的修改,提高合约的安全性。
** 2.2 权限分离与可操作性**
Move 语言中的资源定义与权限是分离的,默认权限是只可以移动,并且明确了资源的权限属于用户。相比于Solidity 中数据权限归于合约,这让资源更加安全。
另一方面,为了可以实现更多更复杂的业务,Move 另外定义了 4
种权限属性:可复制(copy)、可丢弃(drop)、可存储(store)、可检索(key)。这 4
种属性可以任意组合,在资源定义是可以明确指明资源的权限属性,方便用户定义各种权限的资源,带给用户更大更灵活的可操作性。比如:
- 使用 copy + drop + store + key 组合,定义的资源时最普通的,类似于 Solidity 中的结构;
- 使用 drop + store + key 组合,定义的资源不可以复制,可以避免复制增发的问题;
- 使用 copy + drop 组合,定义的资源不能存储和检索,可以用于临时性的可复制普通资源;
- 单独使用 drop,定义的资源只可以移动和丢弃,不能复制、存储、检索,可以用于临时性的唯一性资源;
- 不使用任何权限类型,则定义的资源只可以移动。
不同的应用场景,定义资源时需要组合使用不同的权限属性。出于安全性考虑,资源的权限选择需遵从最小原则。比如,如果资源没有复制的场景,则权限声明中不应该包含
copy。
** 2.3 模块与灵活组合性**
Move
语言使用了模块(module)和脚本(script)的设计。其中,模块类似于Solidity中的Contract,定义了合约中的资源数据以及相关的业务逻辑,而脚本定义了交易。
Move
语言本身是一种静态语言,采用静态调用的形式,合约调用被虚拟机沙盒中执行。在调用过程中,合约的状态通过编程语言内部的安全性进行隔离,而非依赖于虚拟机进行隔离,这使得不同的模块可以直接在虚拟机沙盒中更加灵活地进行相互组合调用。
当一个模块进行优化升级时,所有组合使用过该模块的其他合约都会自动调用升级后的最新版本。对比Solidity中合约升级带来的一系列复杂操作,Move
语言中的模块具有强大的可组合性、灵活性以及快速的合约优化升级速度。
安全性方面,模块不支持循环递归依赖,从根本上避免了合约重入的风险。
** 2.4 泛型与编程灵活性**
泛型的使用使得 Move 灵活性大大增加,我们可以为数据结构和函数方法引入泛型,从而使得功能相同的代码只需要被实现一次就可以应用到多个类型,类似于 C++
泛型编程。
** 2.5 形式化验证机制**
Move 语言有一个称为 Move 验证器(Move Prover, MVP) 的组件,支持形式化验证机制作为链下的静态安全验证工具。MVP
通过形式化验证领域的自动定理证明求解器来验证程序是否符合某种规范(Specification)。
这种形式化验证的方法需要需用详细的了解合约运行逻辑,并且自定义程序逻辑需要的规范,然后将其和程序一起传达给验证器 MVP。只有 MVP
通过验证后合约代码才可以在运行环境(VM runtime)中执行。
为了更好的实现形式化验证的规范,Move 自定义了规范预言 Move Specification Language。规范预言中定义了前置条件、后置条件、
中止条件、需求条件、确定条件、修改条件、恒定条件、假设和断言等来实现合约逻辑所需要的验证条件,包括语言层面的验证需求和业务层面的验证需求。
** 2.6 静态调用与虚拟机沙盒**
静态调用指程序调用时,在运行之前就已经确定了调用的对象,在运行过程中不改变调用对象。
Move
语言采用的就是静态调用系统,这是一种逻辑上的约束,可以在运行前发现一些编程中的低级错误和漏洞,比如,可在运行前发现整数溢出漏洞,可以避免动态系统中攻击者利用恶意合约调用项目方函数触发的攻击。相比于动态调用,静态调用可以在一定程度上避免动态调用存在的安全性问题,提高了智能合约运行的安全性,同时也提高了区块链交易运行的稳定性。
Move 虚拟机(MoveVM) 是一个带有静态类型系统的堆栈计算机,用于执行 Move 字节码表示的交易,包括两个主要的组件:核心 VM(core VM)
和 VM 运行时(VM runtime)。其中,核心 VM 包含了 MoveVM 的底层数据,VM 运行时提供了执行交易的环境。
合约执行与调用都在同一个 Move 虚拟机沙盒中,在此过程中,不同合约的状态主要是通过程序字节码内部的安全性进行隔离,其中的关键在于 Move
语言的模块、静态系统确定性特性以及 Move 资源与账户的绑定关系。
首先,模块的定义是静态的、确定性的、有一定封闭性的。模块中的函数只能修改该模块定义和创建的资源,这种修改是根据函数预先定义进行修改。要想访问和修改其他模块定义创建的资源,需要调用其他模块的函数,即静态调用。
对比 Solidity 动态调用,通过地址和签名来调用函数,只有在真正执行时才能确定调用的对象(如 call 函数),静态调用的确定性让 Move
函数执行更加安全。
资源与账户绑定,在修改资源数据时需要账户的授权。执行合约时只能修改相关账户的资源对于其他账户没有影响,这样做限制了合约的影响范围,即使合约存在逻辑漏洞,也不能一次性影响所有账户的资源。Solidity因为资产数据保存在合约中,合约若存在漏洞,收到影响的将是所有用的资产。比较之下,Move
合约的安全性更高。
** **3 Move & Solidity 安全性分析 ****
Move 是一种安全的面向资源的静态语言,对比 Solidity,我们从安全的角度总结了以下几点:
(1)资产安全
- Move 以资源的形式定义资产,具有唯一性,不能复制、丢失和重用,保证资产的安全性,可避免无限增发、资产被重用、资产丢失等风险;
- Solidity 以数值形式定义资产,可以复制、重用,这使得资产存在一定的风险,比如重入攻击中,资产被重用;资产无限增发、资产丢失等
(2)权限安全
- Move 中资源定义和权限是分离的,可以灵活组合使用 copy、drop、store、key 四种权限属性,对资源进行操作限制,这保证了资产的权限安全,同时由于自定义的原因,也可能因为权限产生风险。因此,在定义权限时需要谨慎。
- Solidiy 中由于资产就是数值,并没有更细粒度的权限区分,即任意资产都拥有全部的权限。
(3)验证安全
- Move 中除了编译器检查语法问题外,更重要的是 Move 验证器 MVP 以及自定义规范语言,MVP通过形式化验证来检验交易字节码是否满足规范定义的条件。由于规范条件是有用户自定义的,因此,在定义时需要熟悉详细的业务流程,尽可能地避免规范中出现漏洞,尤其是业务层面的一些规范条件。
- Solidity 中没有验证器,因此,更容易出现一些低级别安全漏洞,比如状态变量初始化漏洞等。
(4)静态安全
- Move 是静态语言,函数调用使用的是确定性的静态调用,而且不支持循环递归依赖,可以避免动态调用中存在的一些安全问题,如重入漏洞、相同的函数签名带来的风险、delegatecall带来的风险(如代理模式下状态变量顺序冲突)。
- Solidity 是动态语言,自然会存在动态调用引起的一些安全问题,如内置的 call函数更容易产生重入漏洞、代理升级模式中状态变量冲突引起的漏洞等。
(5)存储安全
- Move 中的资产存储在账户下,只有账户才可以进行操作,即使定义资产的模块存在逻辑漏洞,也不会对所有账户的资产造成威胁,只会影响少数资产,提高了资产存储的安全性。
- Solidity 中的资产以数值的形式保存在合约账户中,当合约存在漏洞时,所有用户的资产都将存在安全风险。
综上所述,Move
是一种安全级别较高的语言,基本上可以避免大多数语言层面的漏洞。但Move合约依然存在强烈的审计需求,原因是Move虽然自定义了规范语言,并且可以自定义业务校验,但需要对业务十分熟悉。因此,如果业务复杂程度高,或者开发者对业务熟悉程度低,合约中的业务规范就可能出现逻辑漏洞,对项目以及用户资产的安全性产生威胁。
** 4 总结**
通过以上分析,Move 是一种安全的面向资源的静态智能合约语言。语言本身的一些设计,以及形式化验证工具,提高了 Move
语言层面的安全性。也因此,项目在开发过程中可以避免很多低级别的漏洞,尤其是语言层面的漏洞,如重入、整数溢出、变量初始化漏洞等。这些是 Solidity
不具备的。这也是Aptos、Sui等公链选择 Move 的重要原因。
但是, Move 衍生公链尚处于发展阶段,真正运行的项目并不多,Move是不是真正能够经受住考验还需要时间来验证。
下一课,我们将重点讨论Move项目的安全审计要点。
尤其是语言层面的漏洞,如重入、整数溢出、变量初始化漏洞等。这些是 Solidity
不具备的。这也是Aptos、Sui等公链选择 Move 的重要原因。
但是, Move 衍生公链尚处于发展阶段,真正运行的项目并不多,Move是不是真正能够经受住考验还需要时间来验证。
下一课,我们将重点讨论Move项目的安全审计要点。
最后
分享一个快速学习【网络安全】的方法,「也许是」最全面的学习方法:
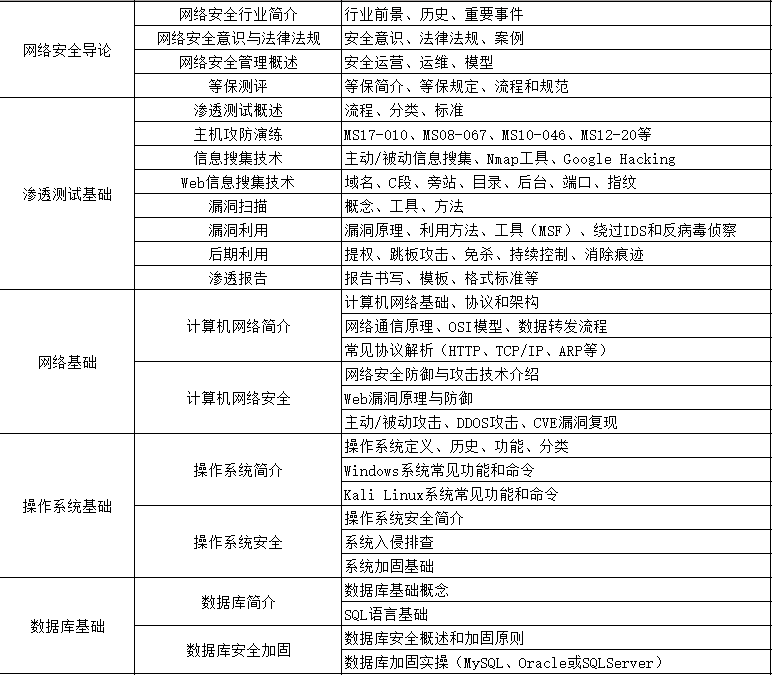
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k。
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
想要入坑黑客&网络安全的朋友,给大家准备了一份:282G全网最全的网络安全资料包免费领取!
扫下方二维码,免费领取

有了这些基础,如果你要深入学习,可以参考下方这个超详细学习路线图,按照这个路线学习,完全够支撑你成为一名优秀的中高级网络安全工程师:

高清学习路线图或XMIND文件(点击下载原文件)
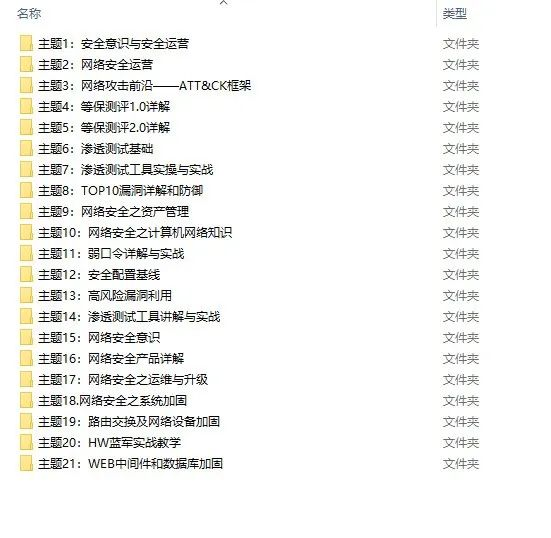
还有一些学习中收集的视频、文档资源,有需要的可以自取:
每个成长路线对应板块的配套视频:
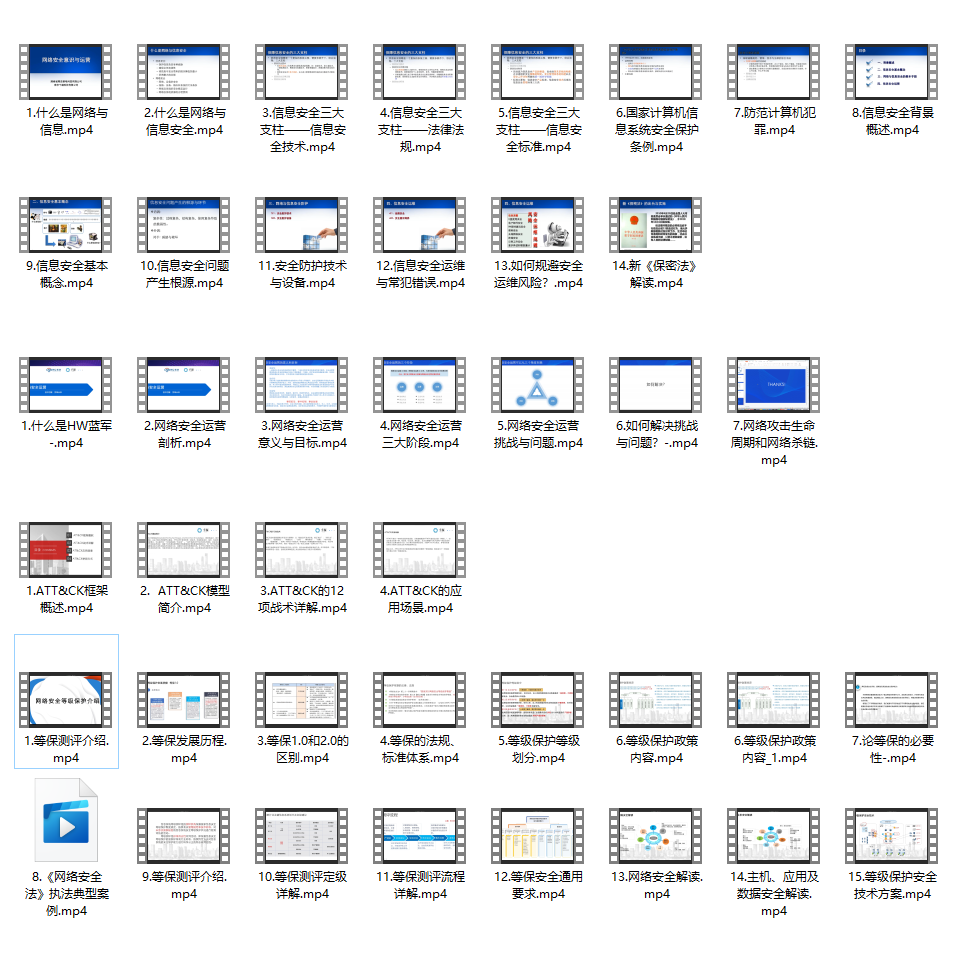
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

因篇幅有限,仅展示部分资料,需要的可以【扫下方二维码免费领取】