东莞网站制作wordpress另一更新正在运行
1.将两台机器通过网线连接
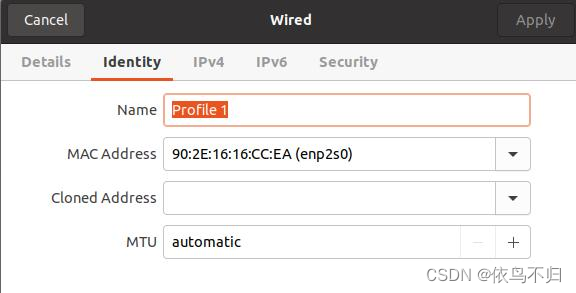
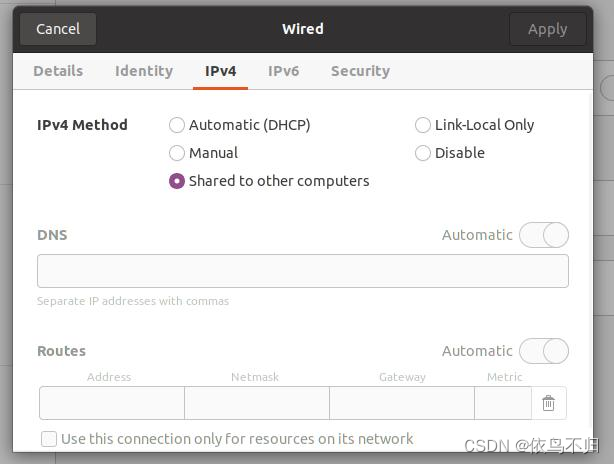
2.在pci ethernet中设置选择另一台机器的mac address,ipv4中选择share to other computer,另一台机器上设置为动态ip,连接上之后另一台机器即可上网。
1.将两台机器通过网线连接
2.在pci ethernet中设置选择另一台机器的mac address,ipv4中选择share to other computer,另一台机器上设置为动态ip,连接上之后另一台机器即可上网。