医药加盟网站模板wordpress修改二级域名
对于许多内容创作者来说,视频剪辑是一项必不可少的技能。然而,传统的视频剪辑方法需要耗费大量的时间和精力。如今,有一种全新的剪辑方式正在改变这一现状,那就是批量AI智剪。这种智能化的剪辑方式能够让你在短时间内轻松剪辑大量视频,省时又省力。

首先,要在浏览器中搜索并下载"固乔智剪软件"。这款软件基于人工智能技术,能够自动化地剪辑视频,大大提高了剪辑效率。
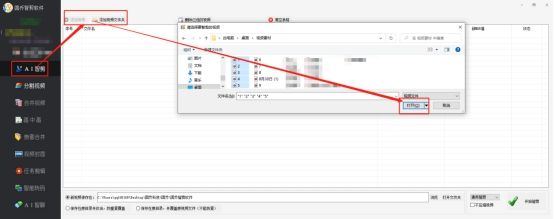
打开软件后,进入"AI智剪"操作页面。页面布局简洁明了,让用户能够快速上手。点击"添加视频"按钮,选择需要智能剪辑的视频文件。你可以一次性添加多个视频,软件支持批量处理。
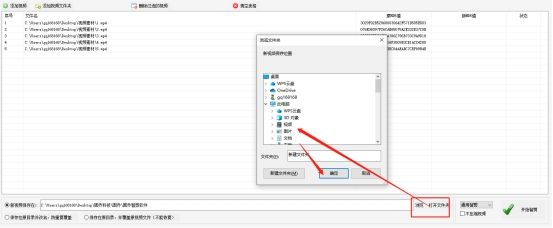
接下来,设置视频的保存位置。你可以选择将剪辑后的视频保存在电脑的任意位置,方便查找和使用。
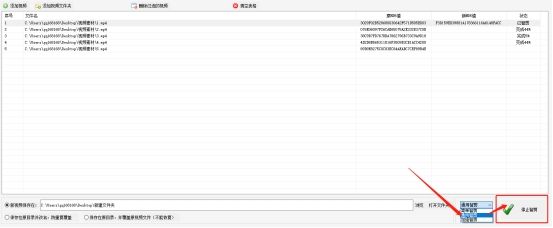
点击"开始智剪"按钮,批量AI智剪过程正式开始。在进度条和表格页面中,你可以实时查看每个视频的剪辑状态。整个过程无需人工干预,让你省心省力。
剪辑完成后,你就可以在指定位置找到剪辑好的视频了。对比一下原视频和剪辑后的效果,你会发现智剪出来的视频不仅质量高,而且节省了大量时间和精力。