网站建设公司销售技巧淘宝搜索词排名查询
安装好Intellij idea之后,进行如下的初始化操作,工作效率提升十倍。
一. 安装插件
1. Codota 代码智能提示插件
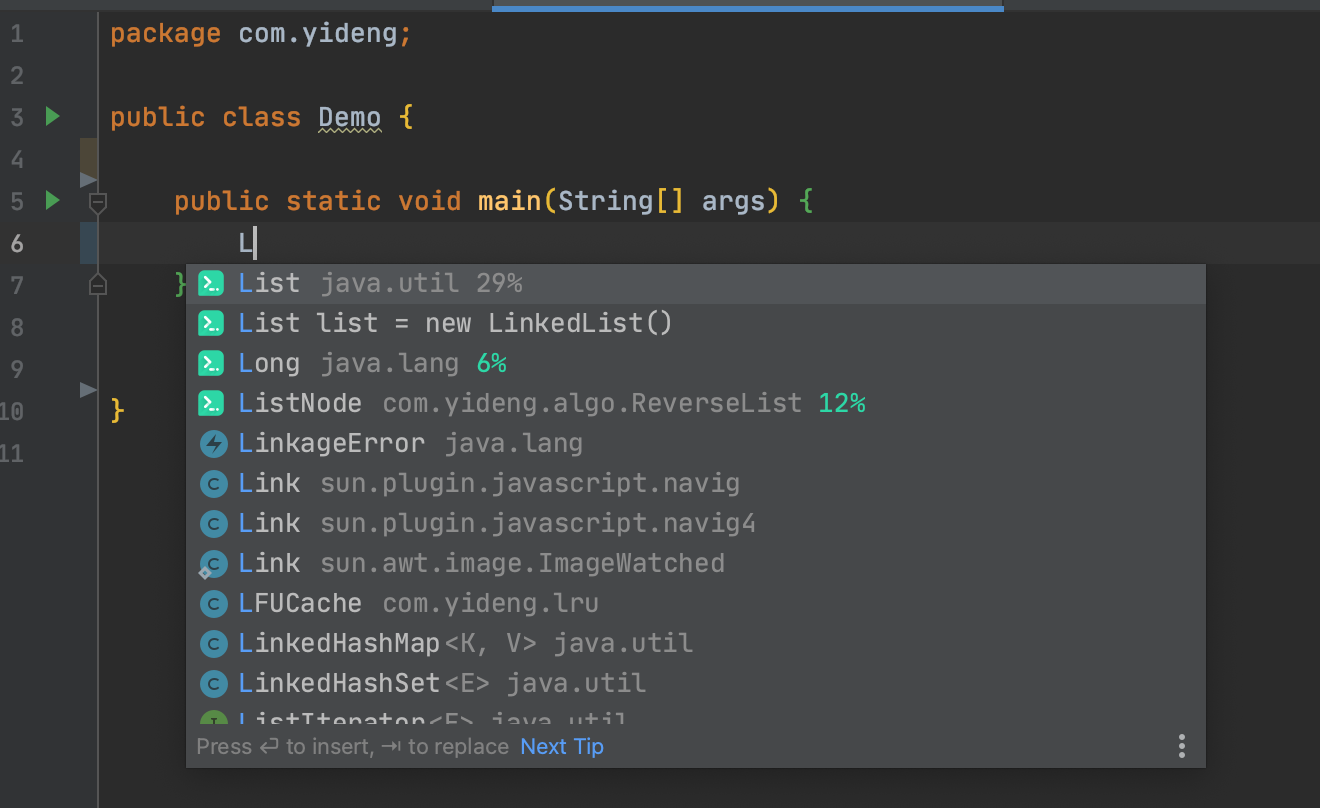
只要打出首字母就能联想出一整条语句,这也太智能了,还显示了每条语句使用频率。
原因是它学习了我的项目代码,总结出了我的代码偏好。
如果让它再加上机器学习,人工智能写代码的时代还会远吗?
2. Key Promoter X 快捷键提示插件
每次都会在右下角弹窗提示,帮助我们快速熟悉快捷键。
3. CodeGlance 显示代码缩略图插件
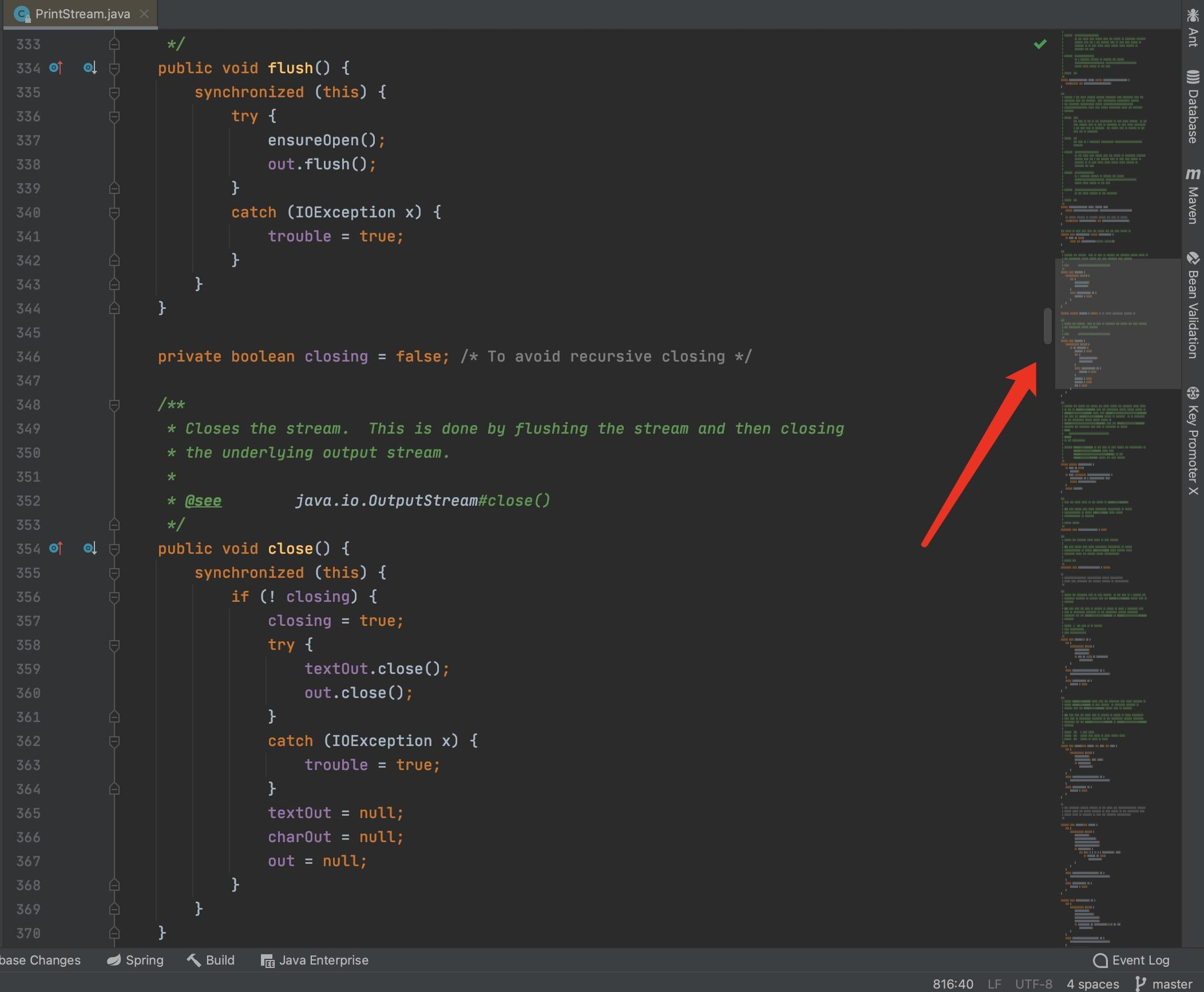
当代码很多的时候,方便查看,很有用。
4. Lombok 简化臃肿代码插件
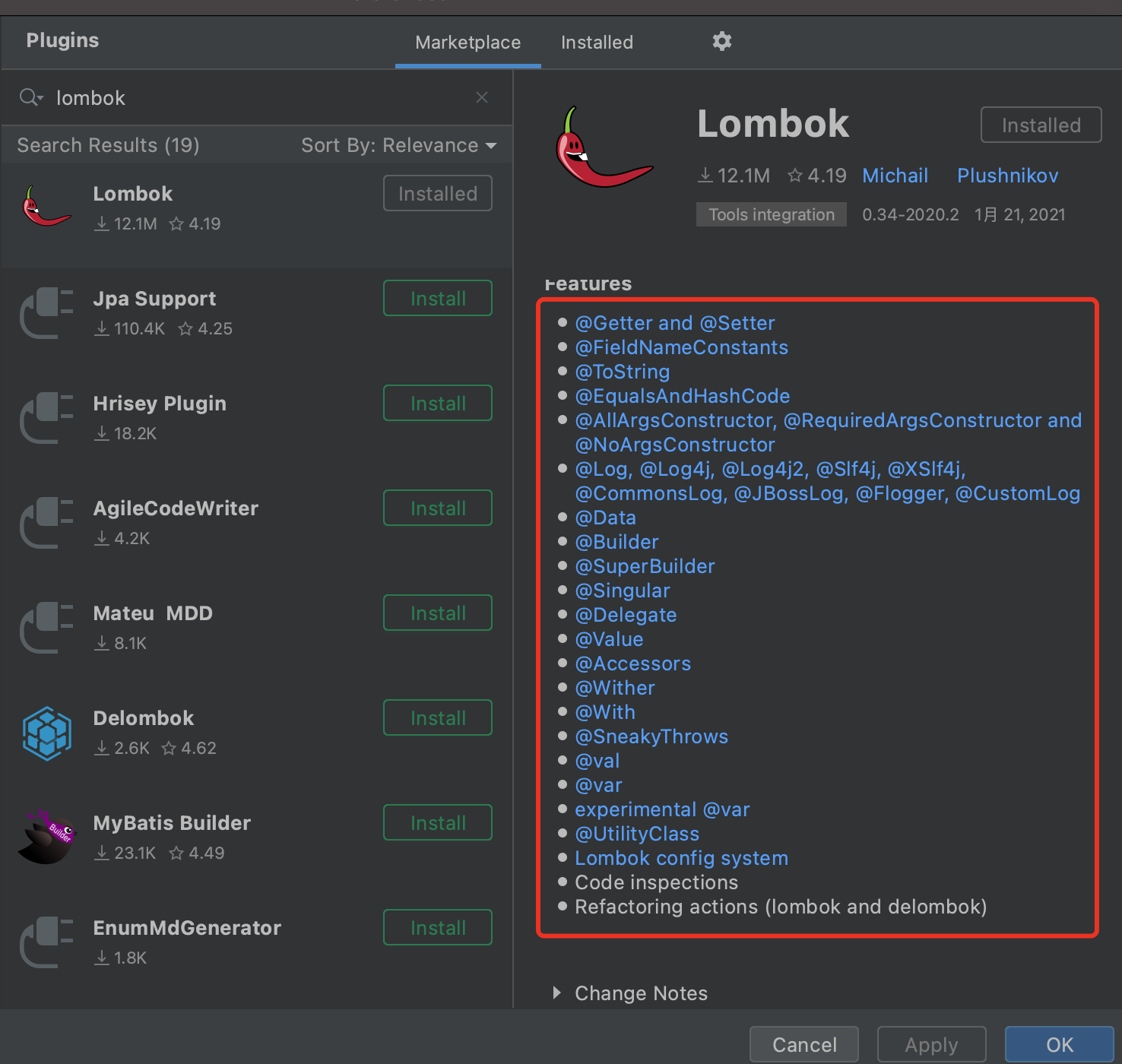
实体类中的get/set/构造/toString/hashCode等方法,都不需要我们再手动写了
5. Alibaba Java Coding Guidelines 阿里巴巴代码规范检查插件
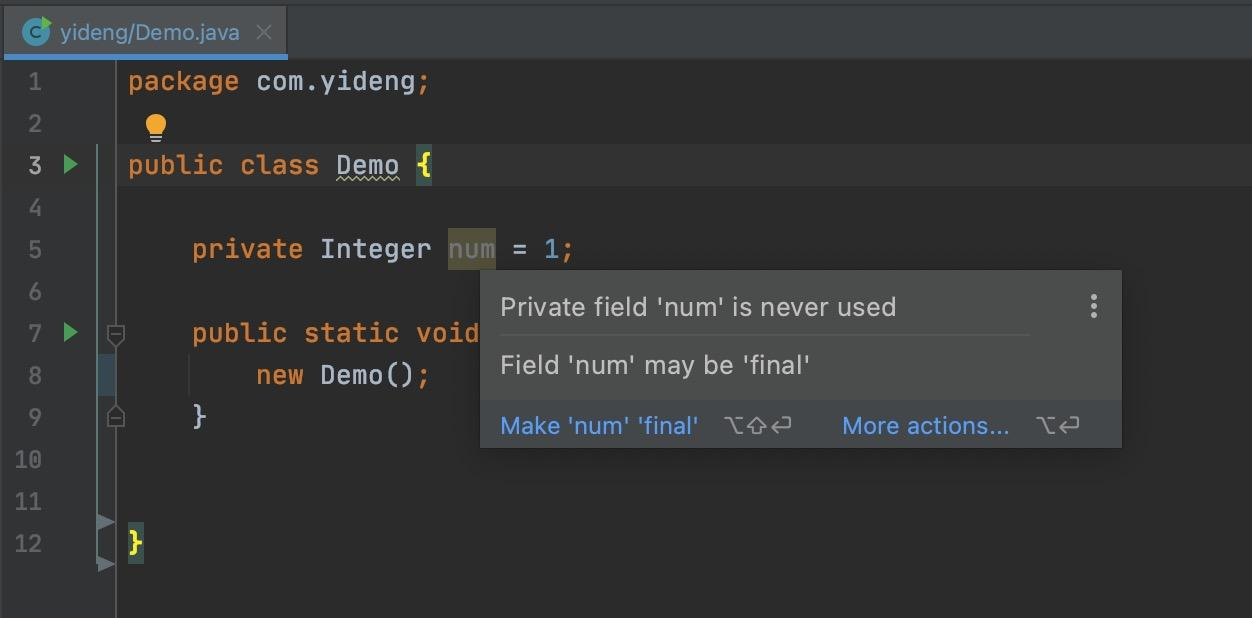
会按照阿里Java开发手册上规范帮我们检查代码,然后对代码做不同颜色展示,鼠标放上去,会看到提示内容,帮助我们写出更规范的代码。
6. CamelCase 驼峰命名和下划线命名转换
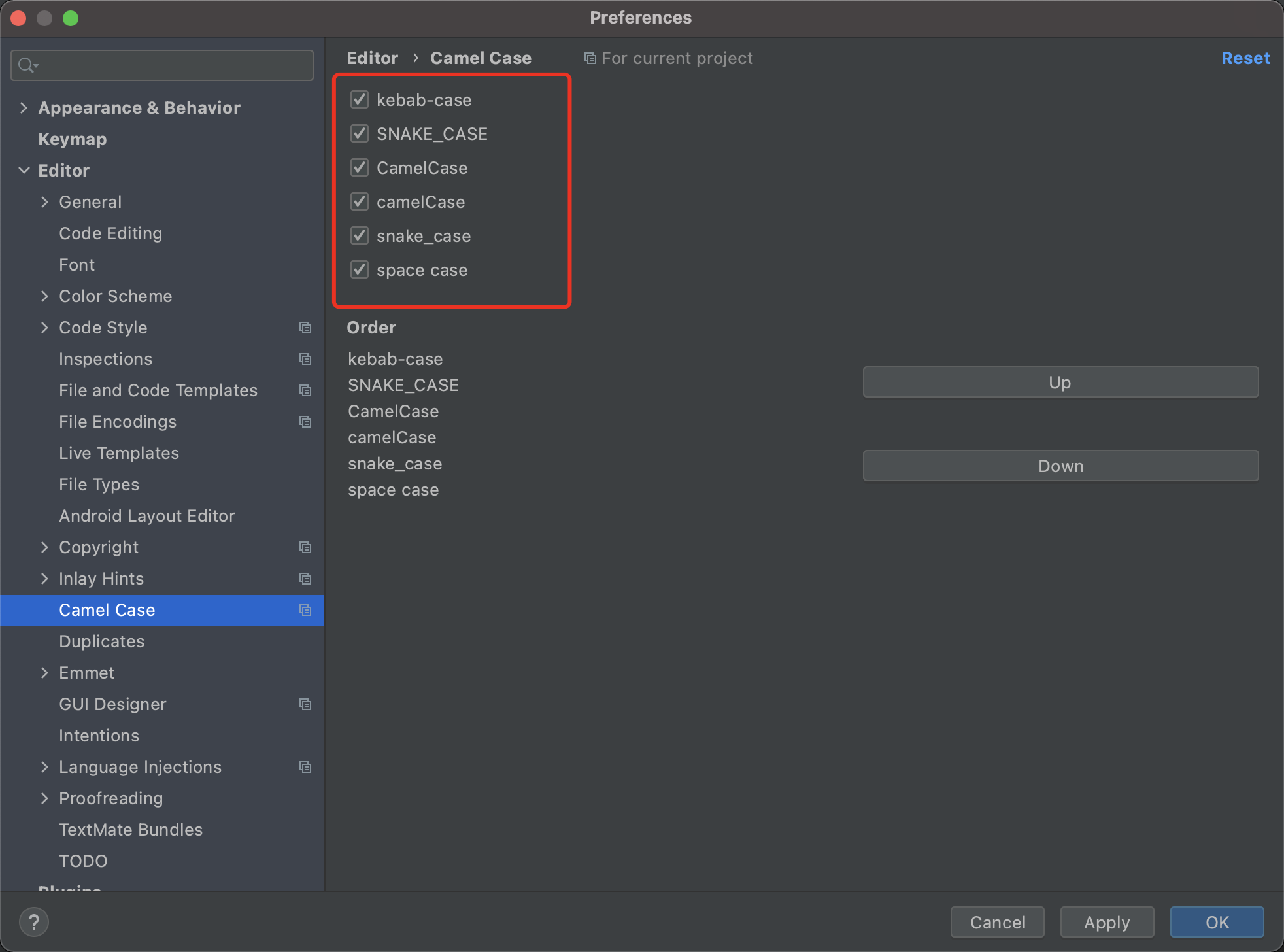
这几种风格的命名方式,用快捷键 ⇧ + ⌥ + U / Shift + Alt + U可以进行快速转换,当我们需要修改大量变量名称的时候很方便。
7. MybatisX 高效操作Mybatis插件

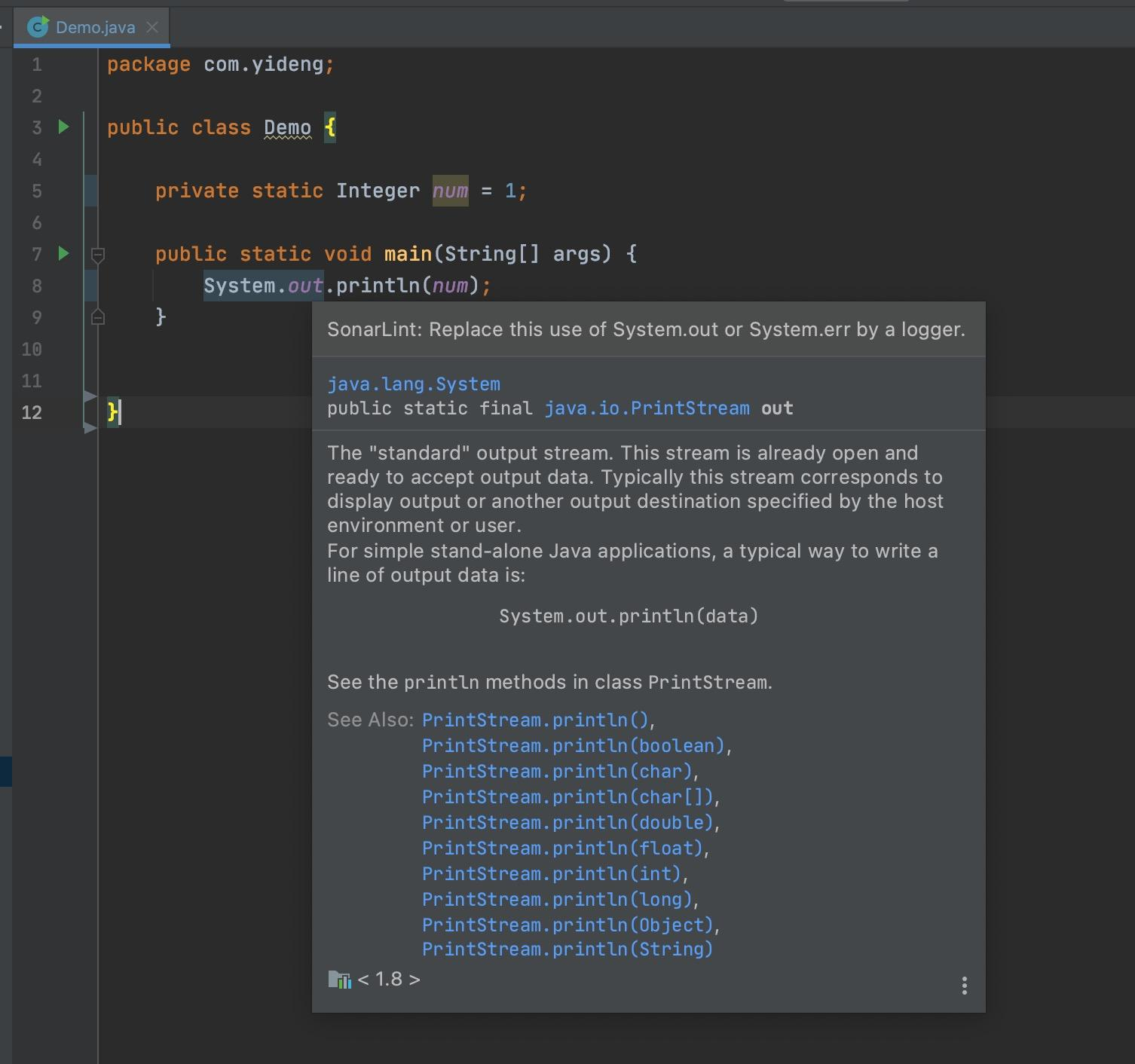
8. SonarLint 代码质量检查插件
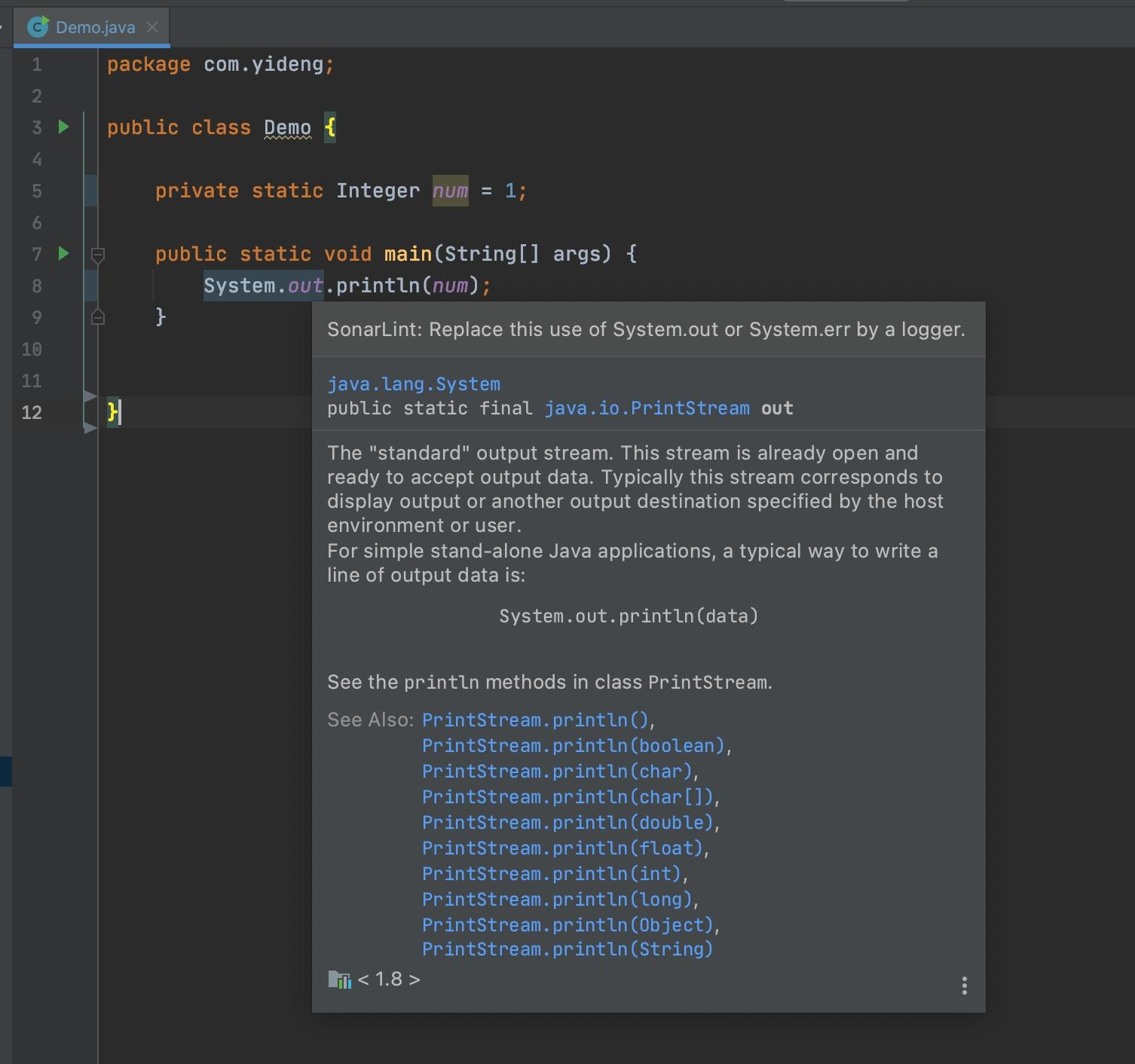
提示我不要用System.out输出,要用logger输出,诸如此类,帮助我们提升代码质量。
9. Save Actions 格式化代码插件
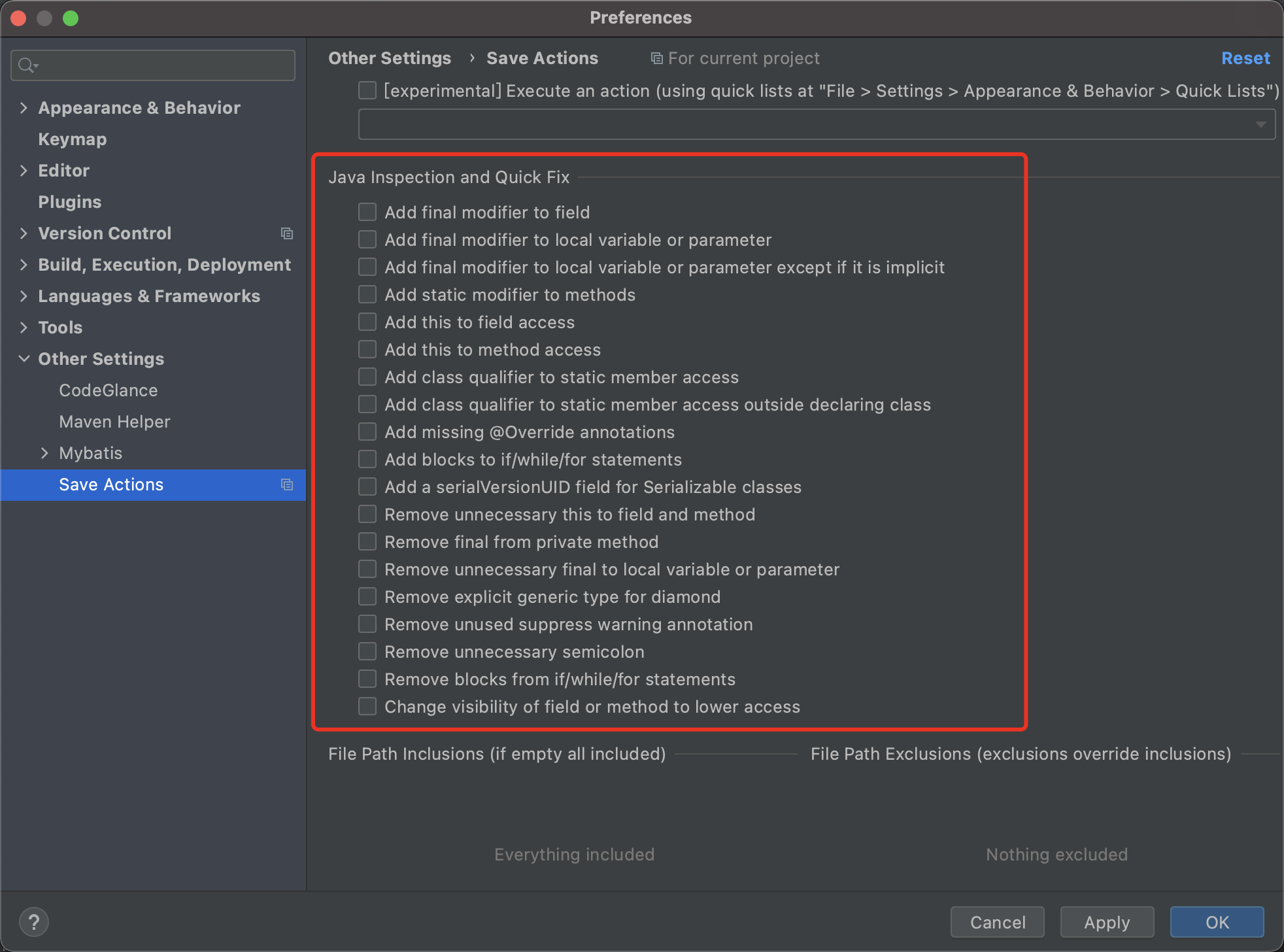
可以帮忙我们优化包导入,自动给没有修改的变量添加final修饰符,调用方法的时候自动添加this关键字等,使我们的代码更规范统一。
10. CheckStyle 代码风格检查插件
功能跟Alibaba Java Coding Guidelines类似
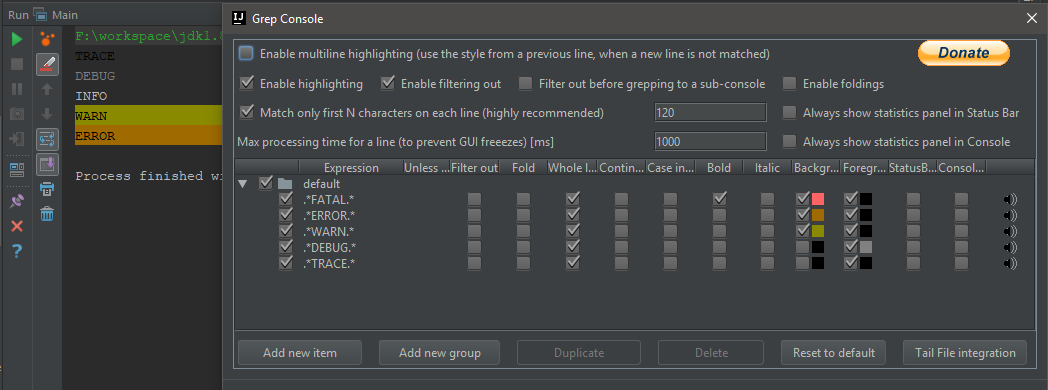
11. Grep Console 自定义控制台输出格式插件
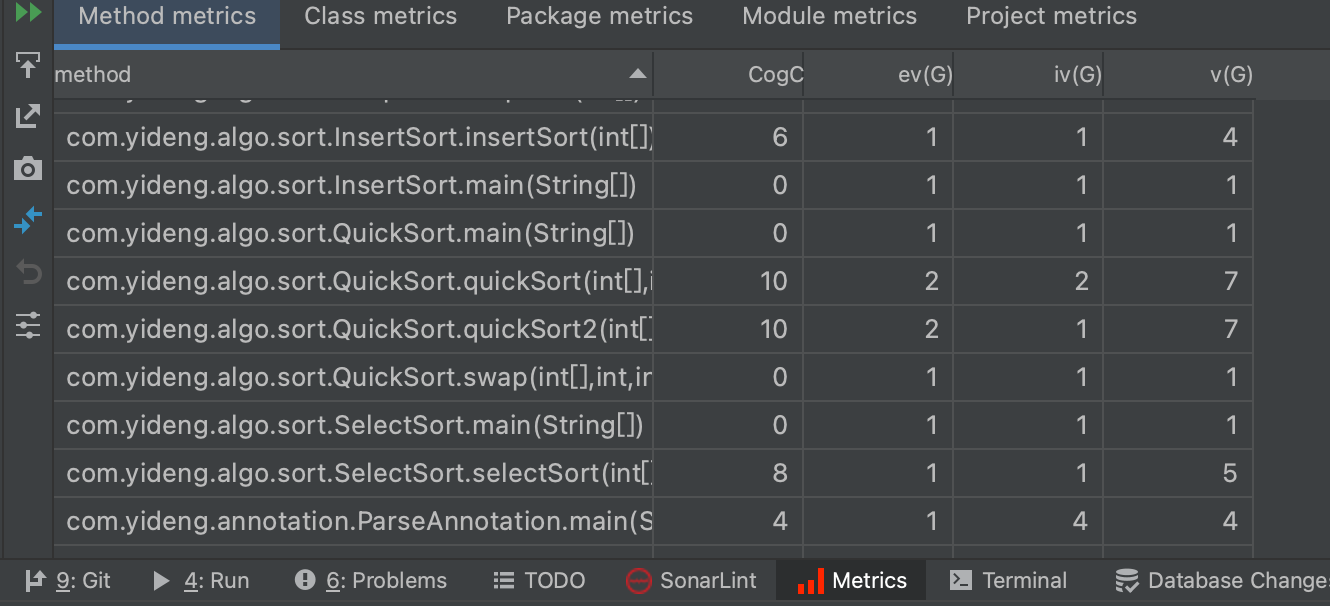
12. MetricsReloaded 代码复杂度检查插件
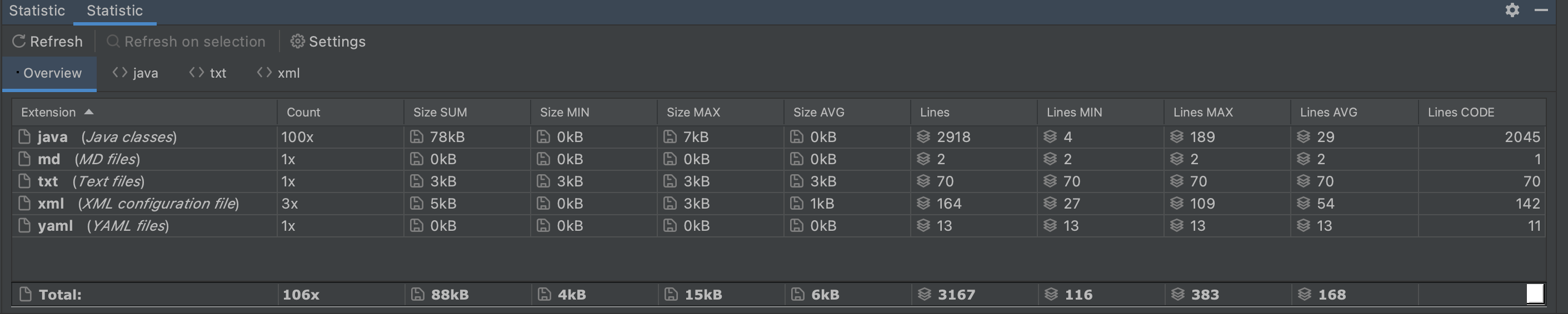
- Statistic 代码统计插件
- Translation 翻译插件
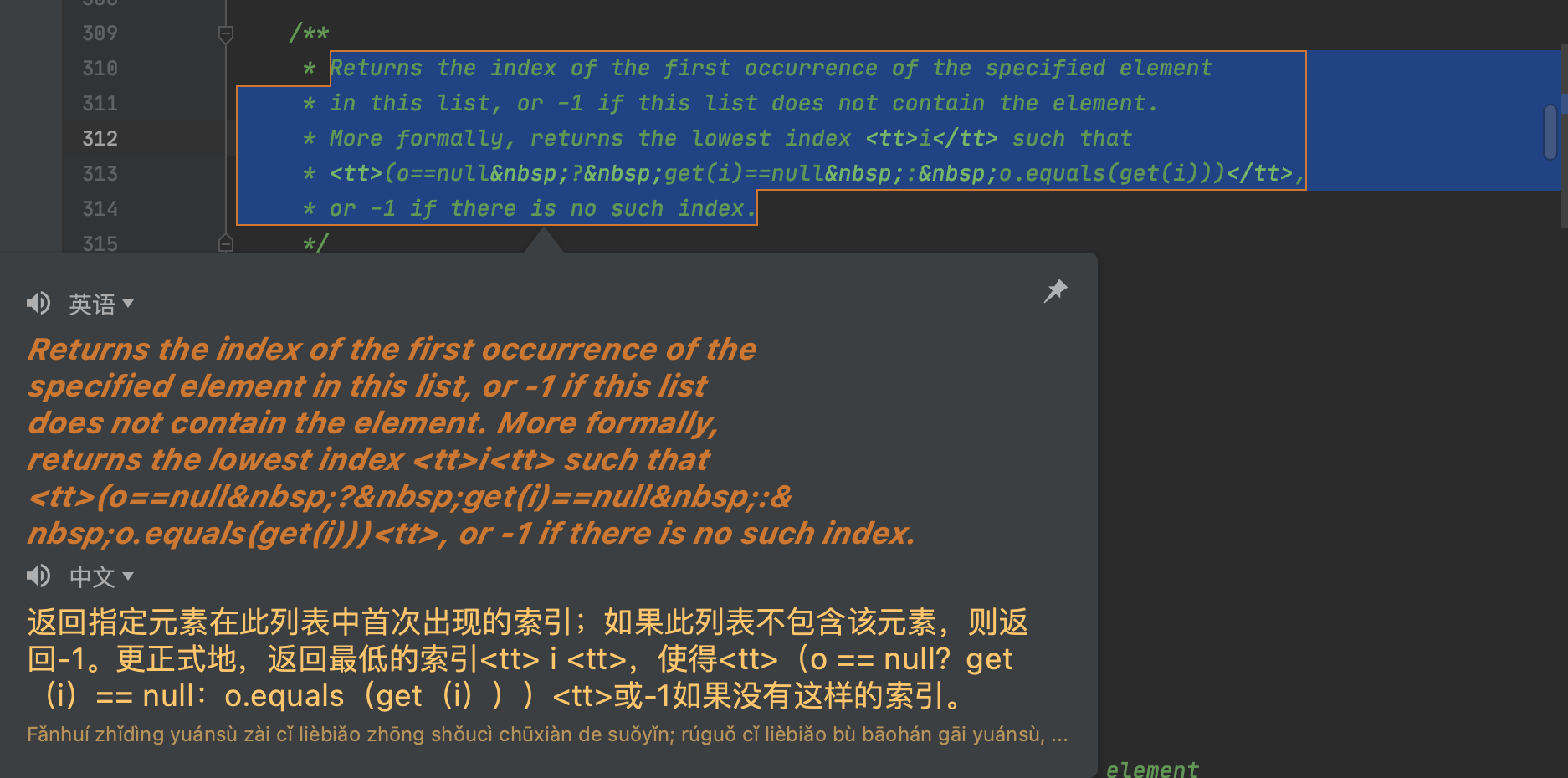
15. Rainbow Brackets 彩虹括号插件
成对儿的括号显示相同的颜色,有了这个插件,我的近视都好了。
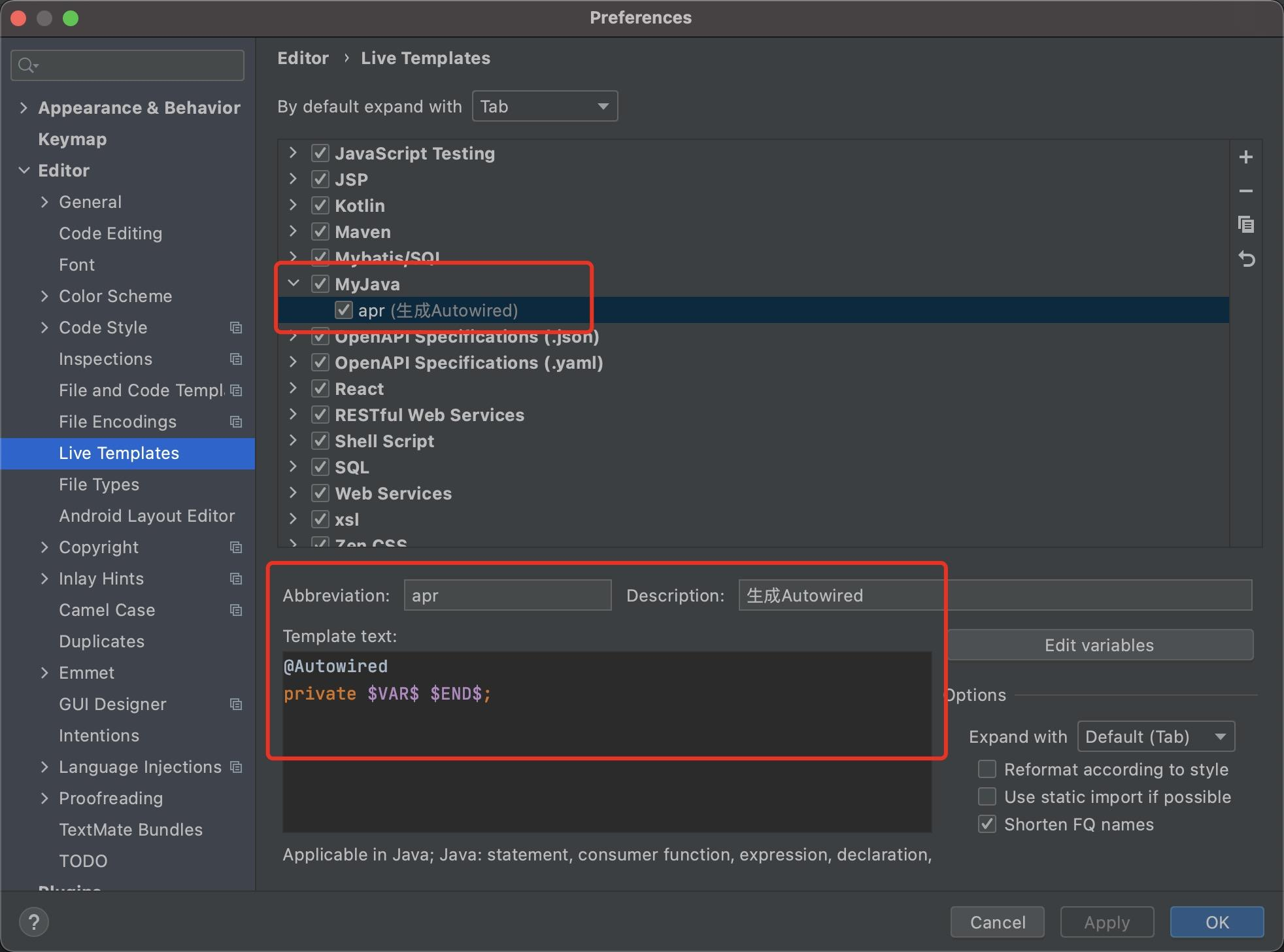
二. 自定义创建live template,快速写代码
只要输入apr,就能自动提示,并且生成Autowired语句了。可以根据自己的代码习惯,自定义一些代码模板,帮助我们快速写代码。
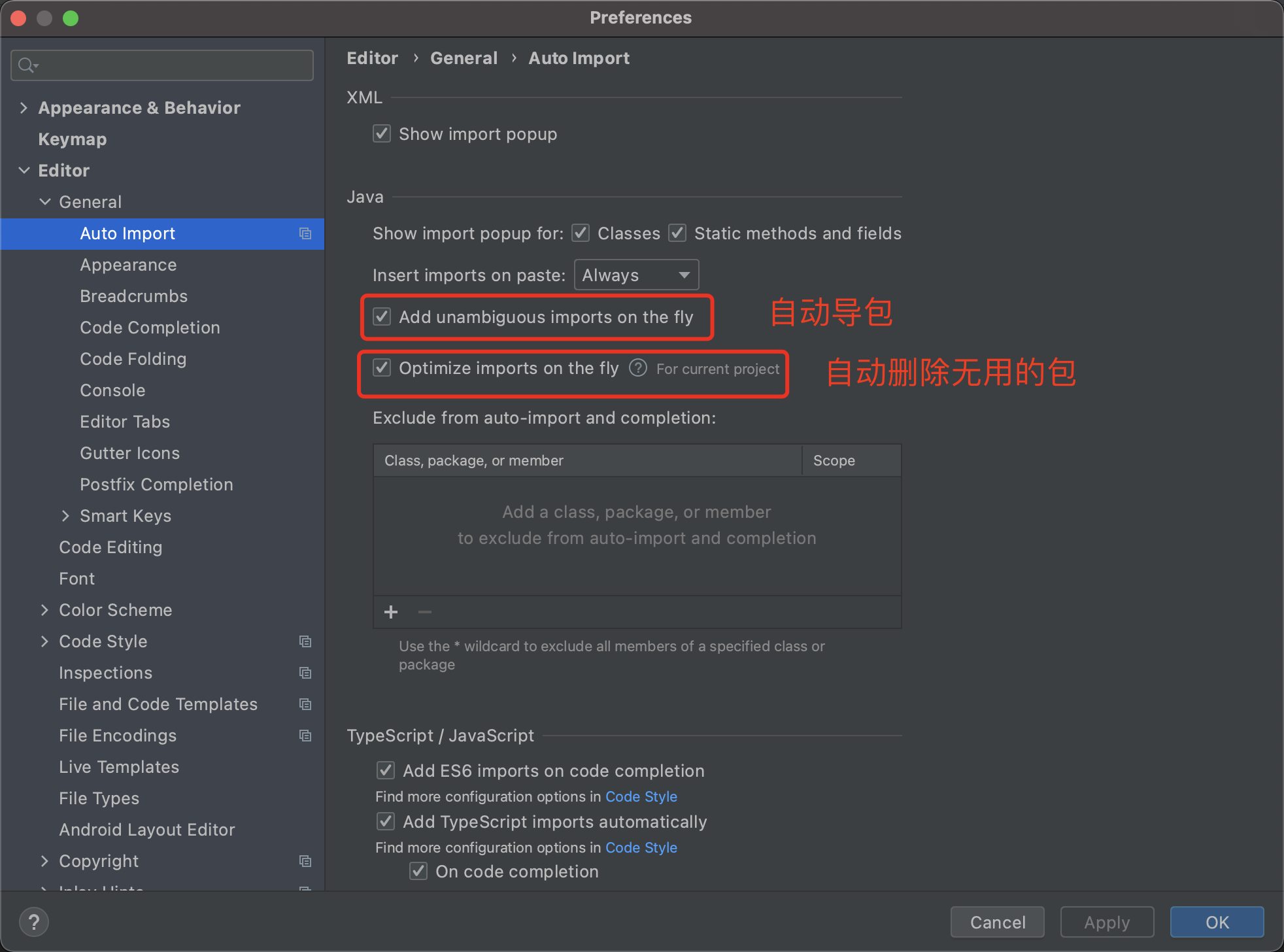
三. 修改全局配置,提升工作效率
1. 优化导包配置
2. 取消tab页单行显示
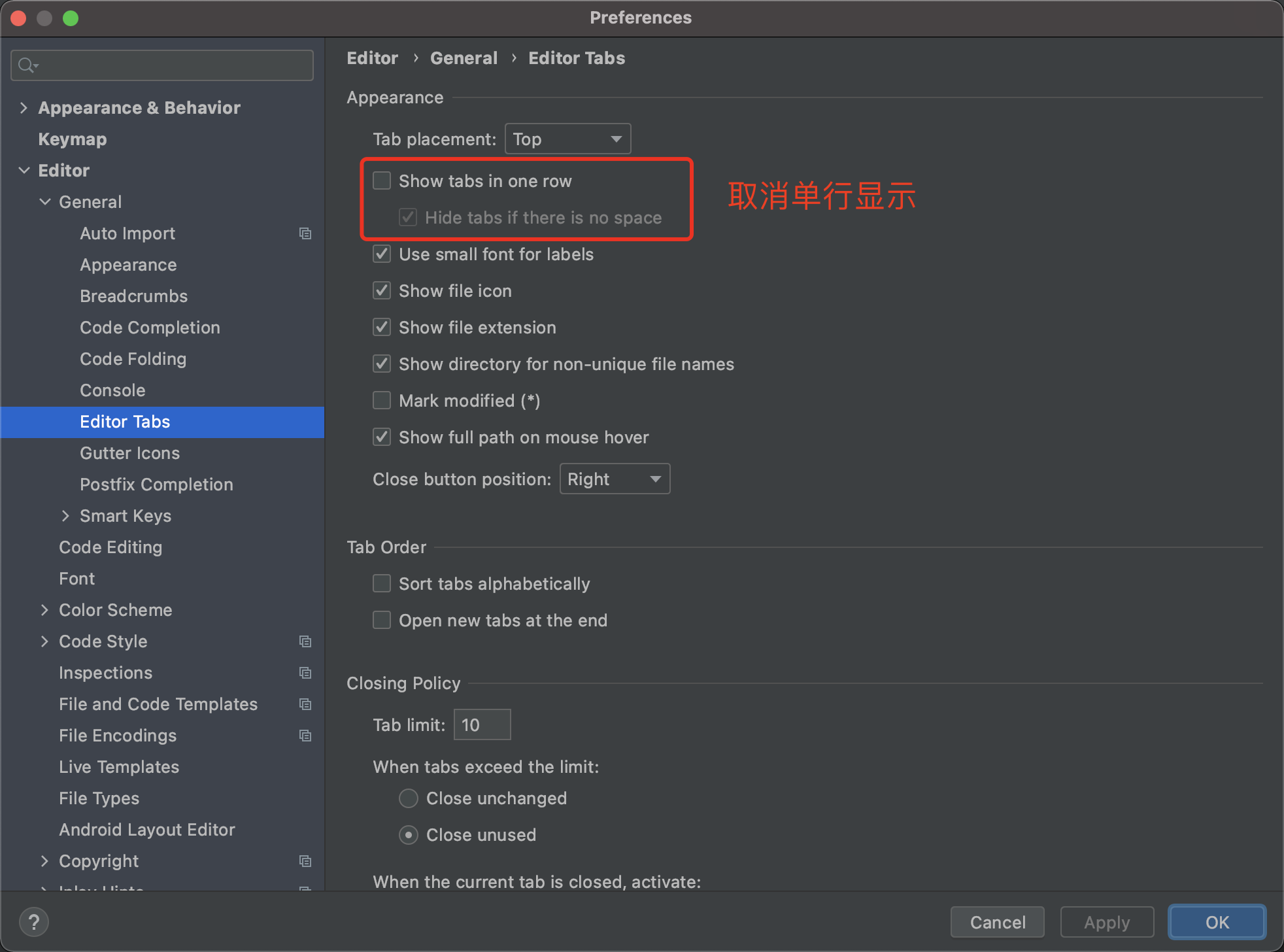
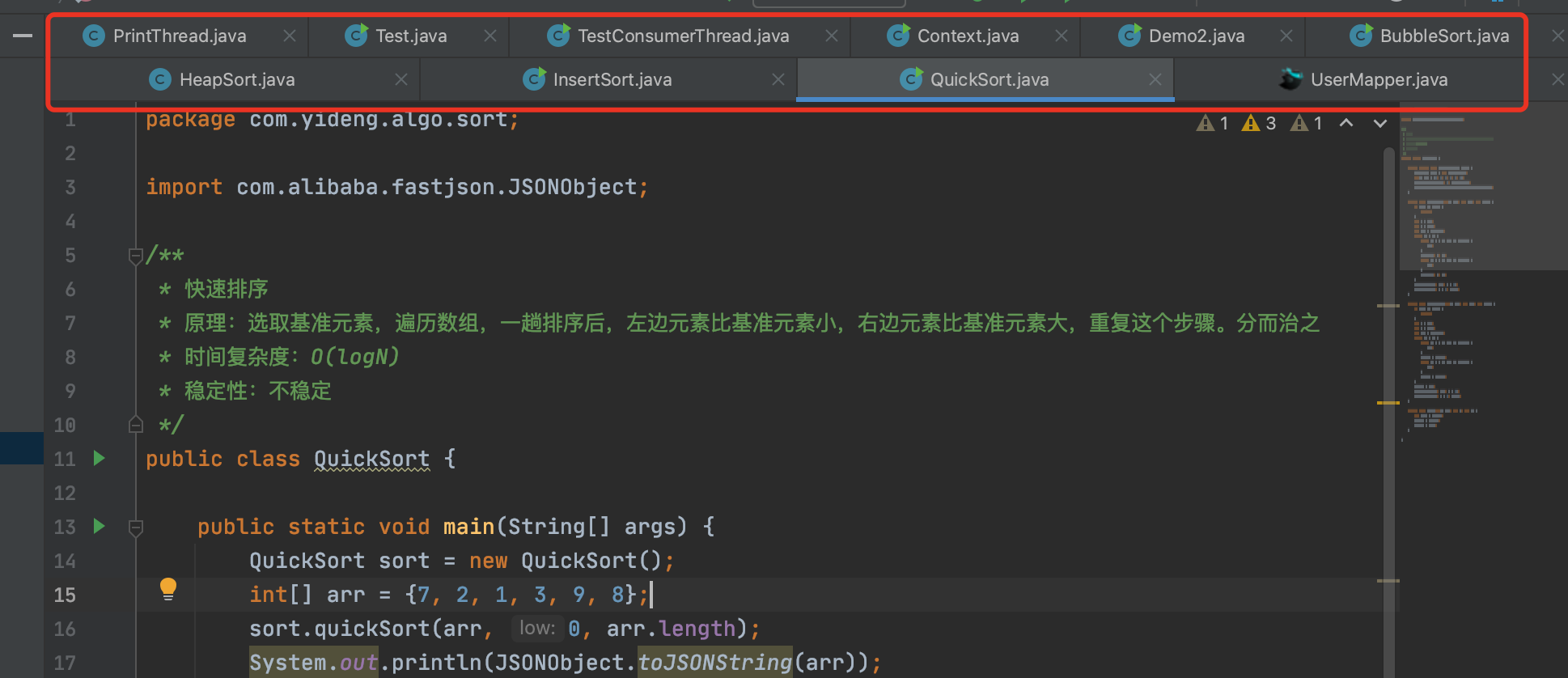
多行显示更多的文件,方便查看。
3. 双斜杠注释改成紧跟代码头
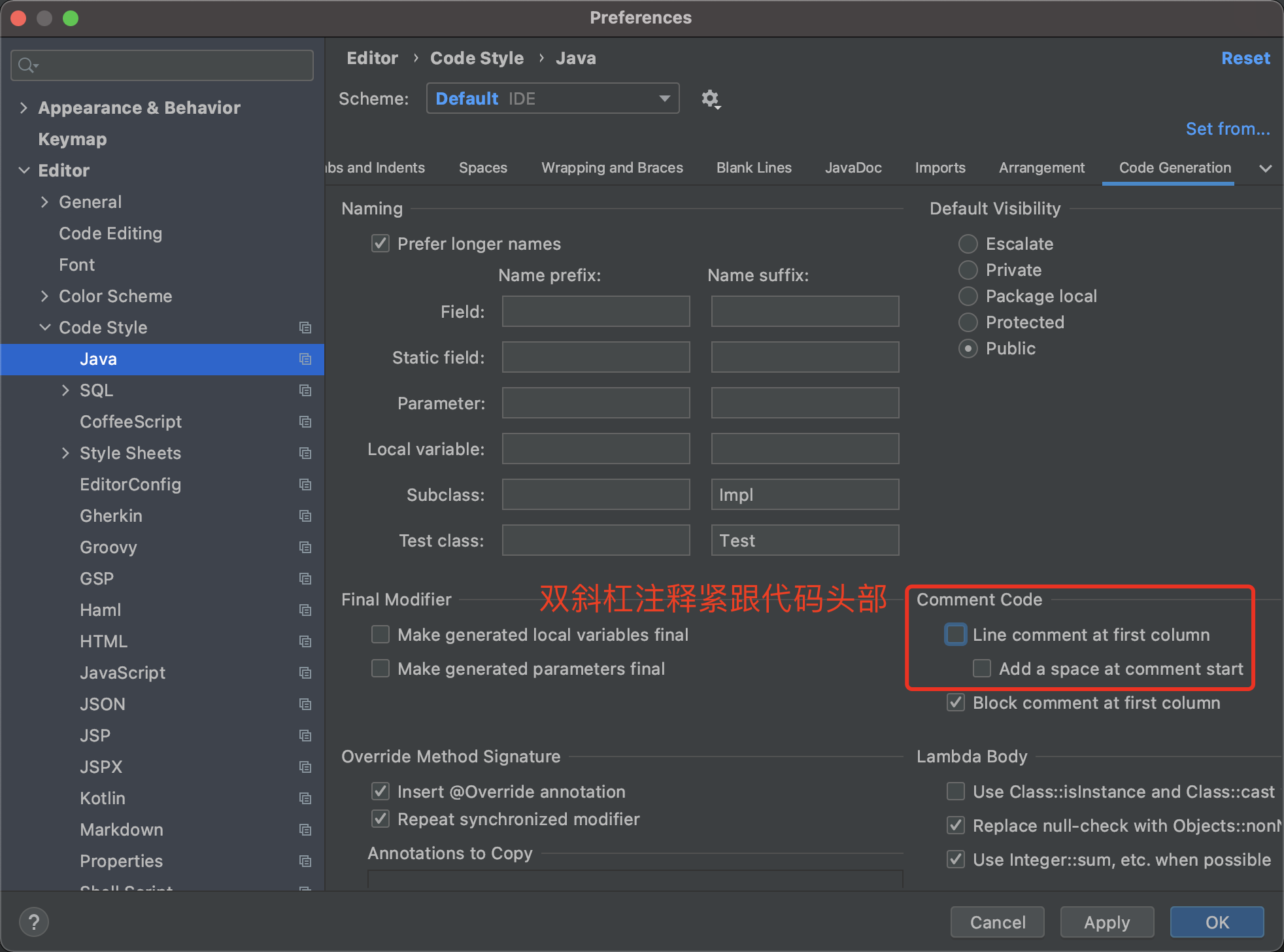
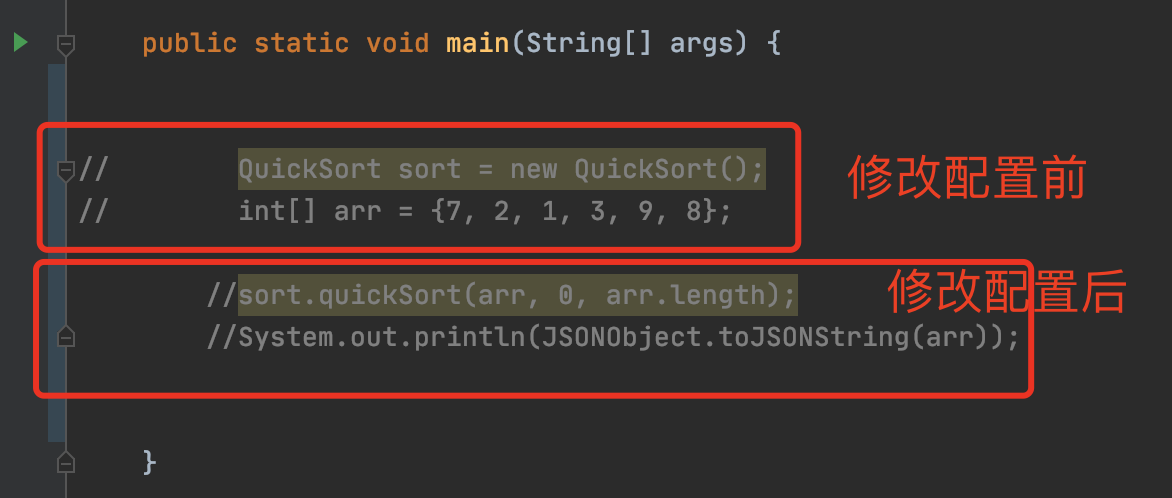
4. 选中复制整行
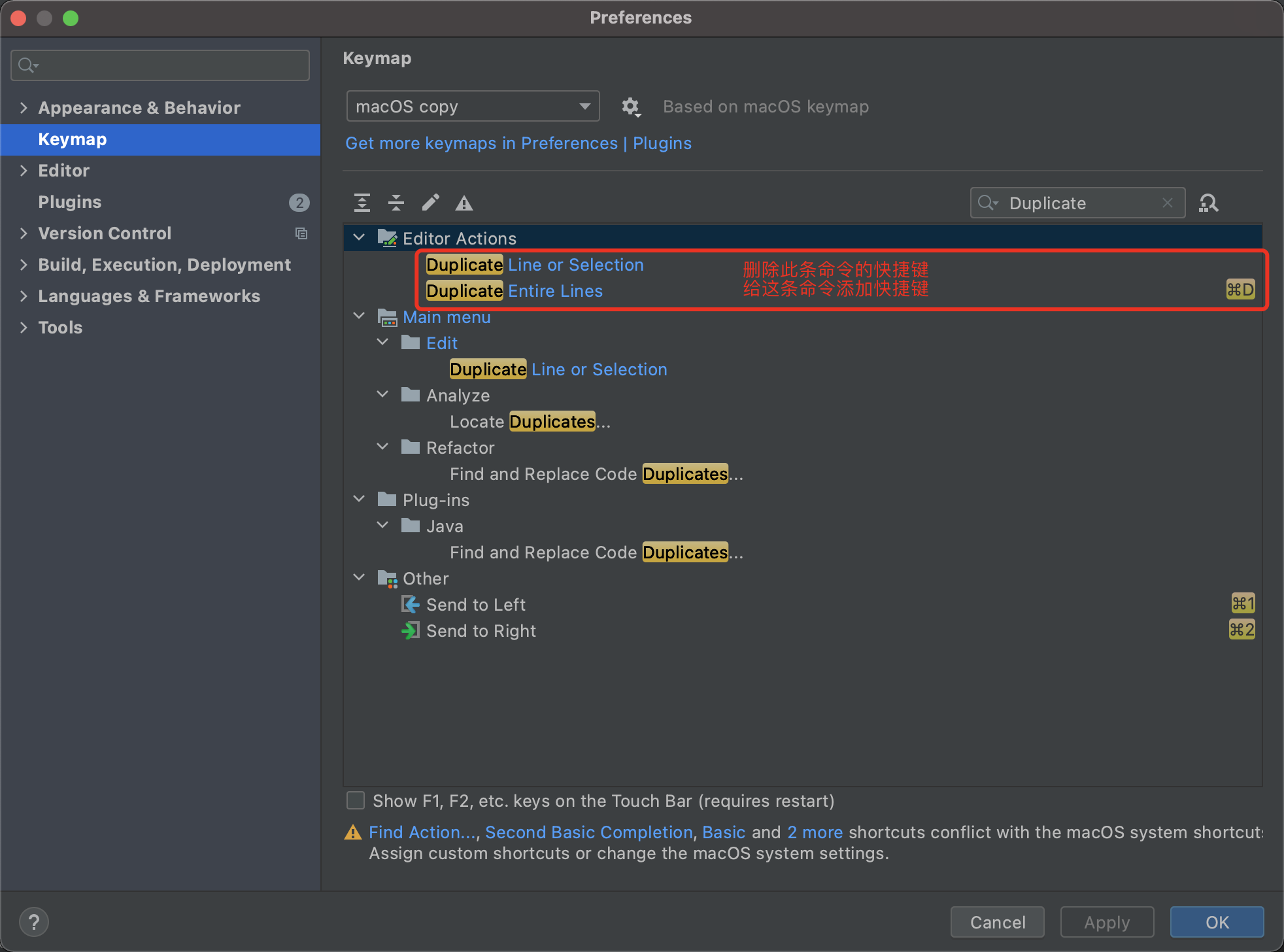
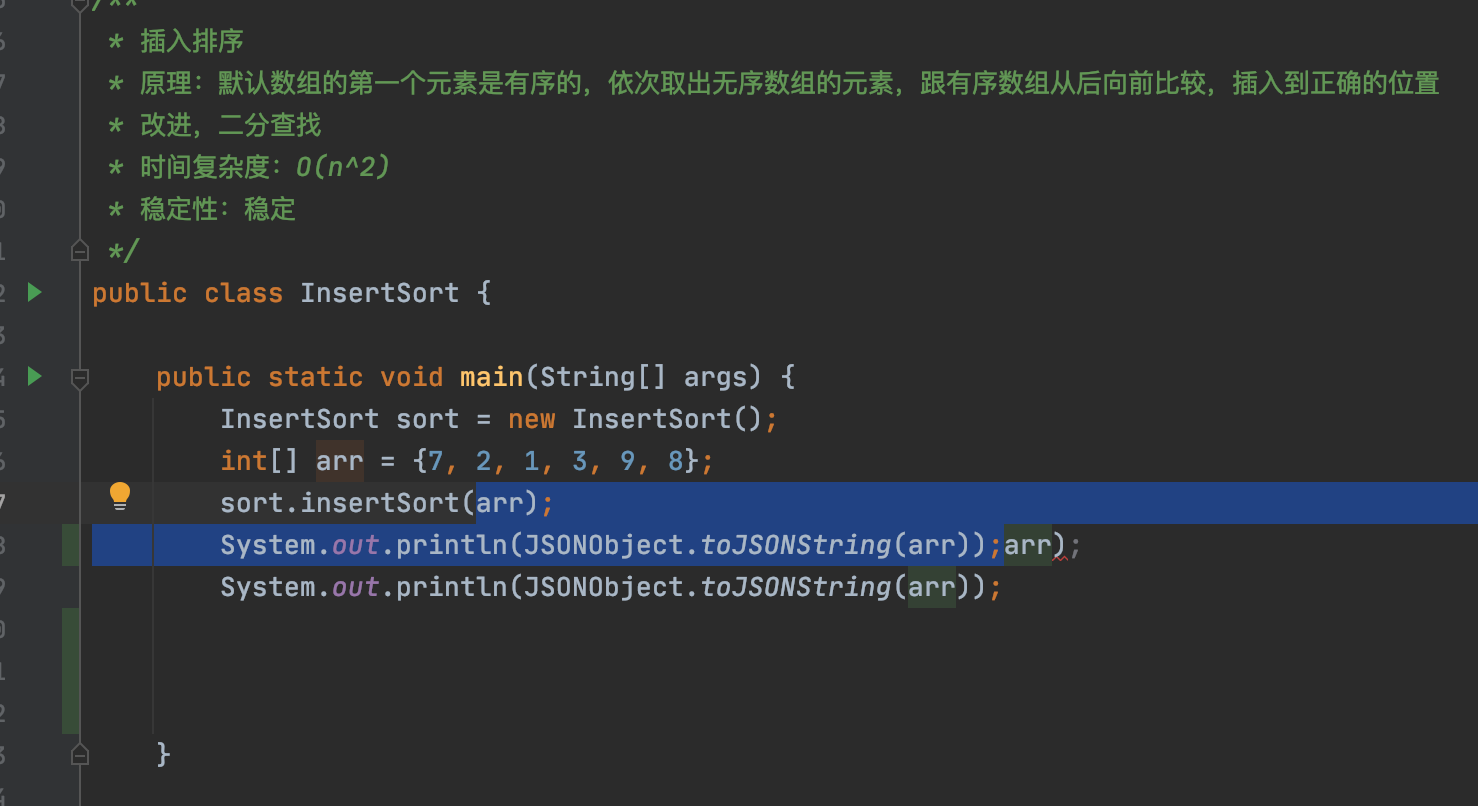
原本只会复制你选中的代码,改完配置后,就能复制整行,无论你是否完全选中。
5. 取消匹配大小写
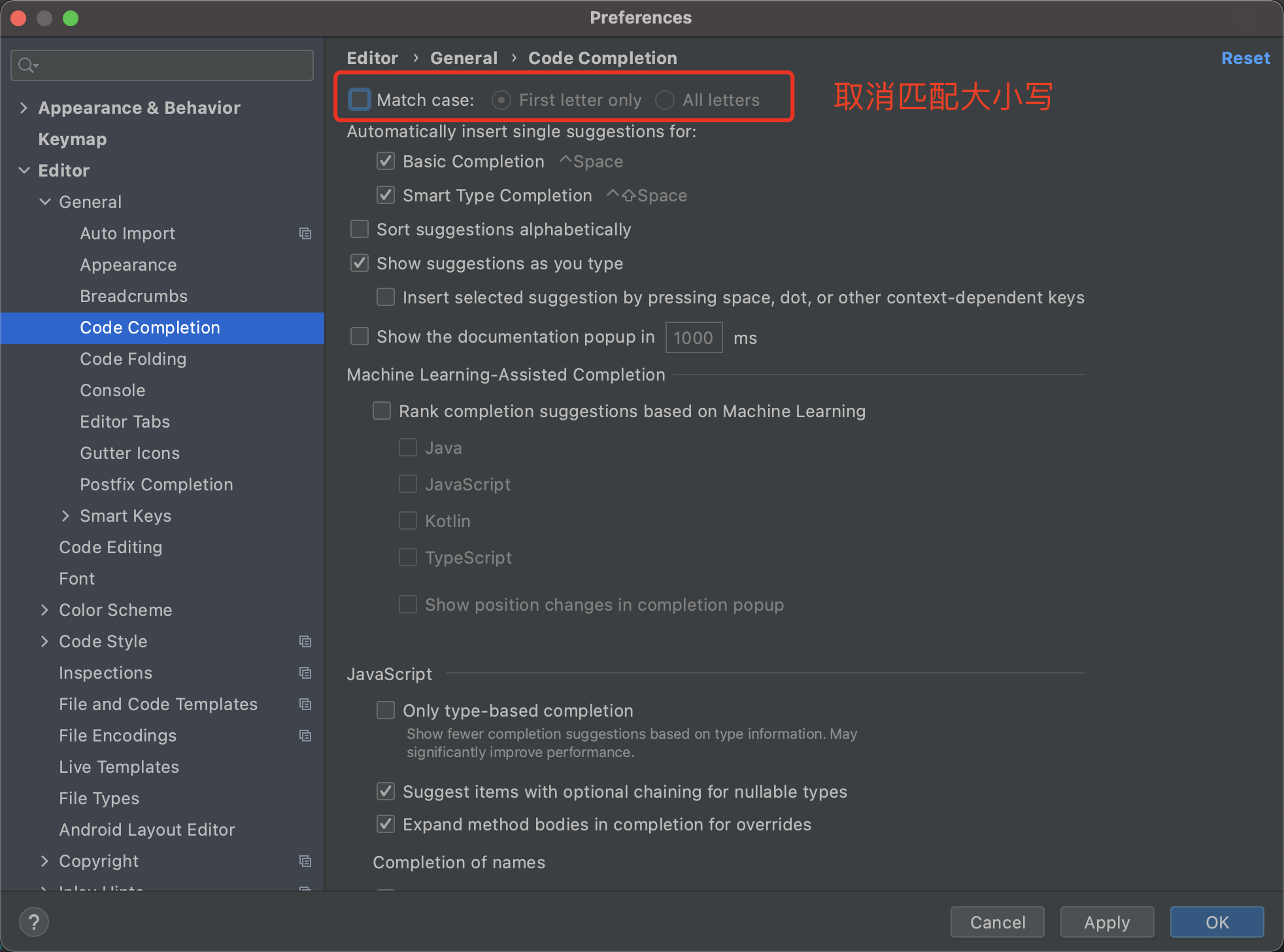
取消勾选后,输入小写 s,也能提示出 String
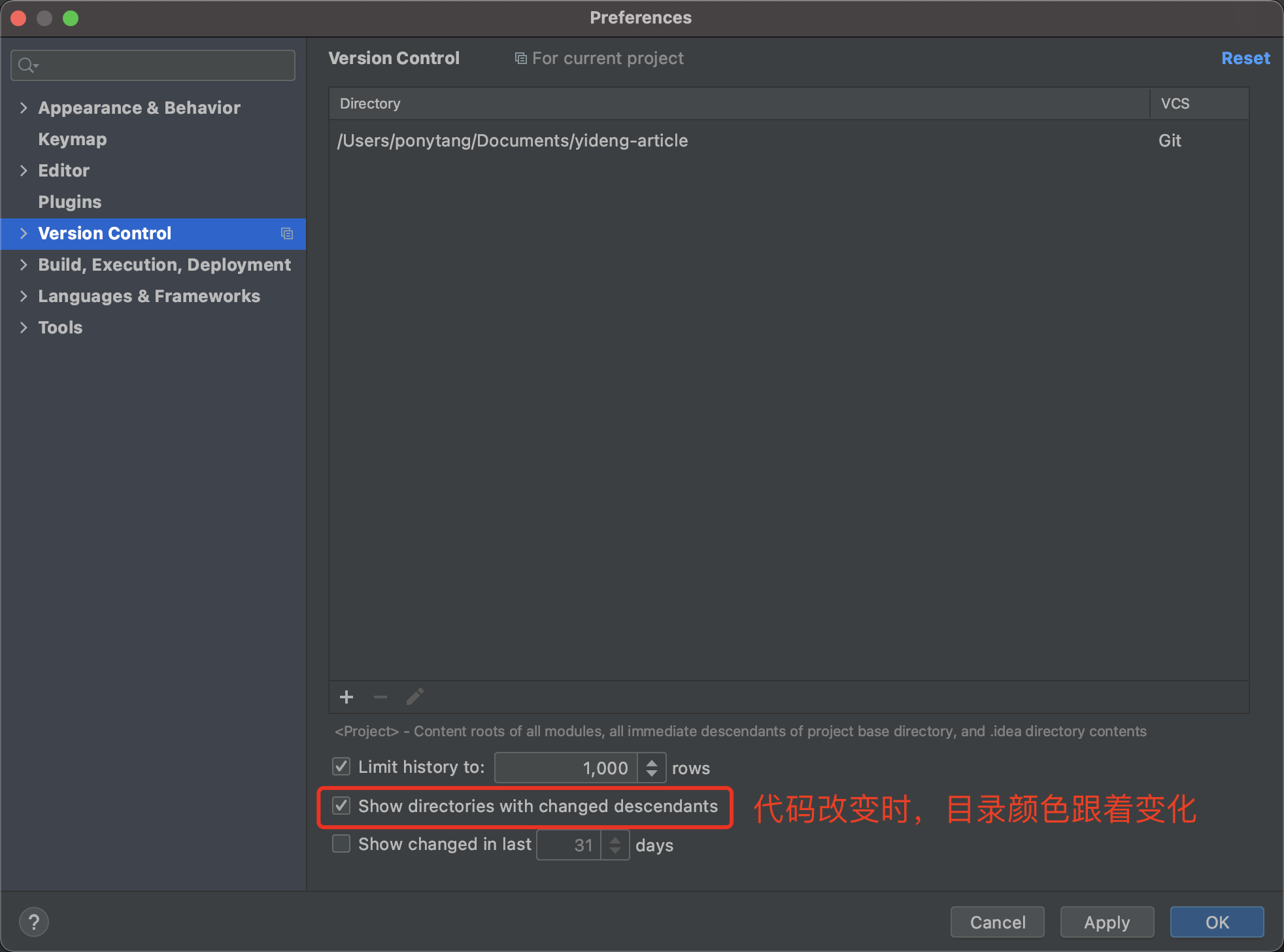
6. 优化版本控制的目录颜色展示
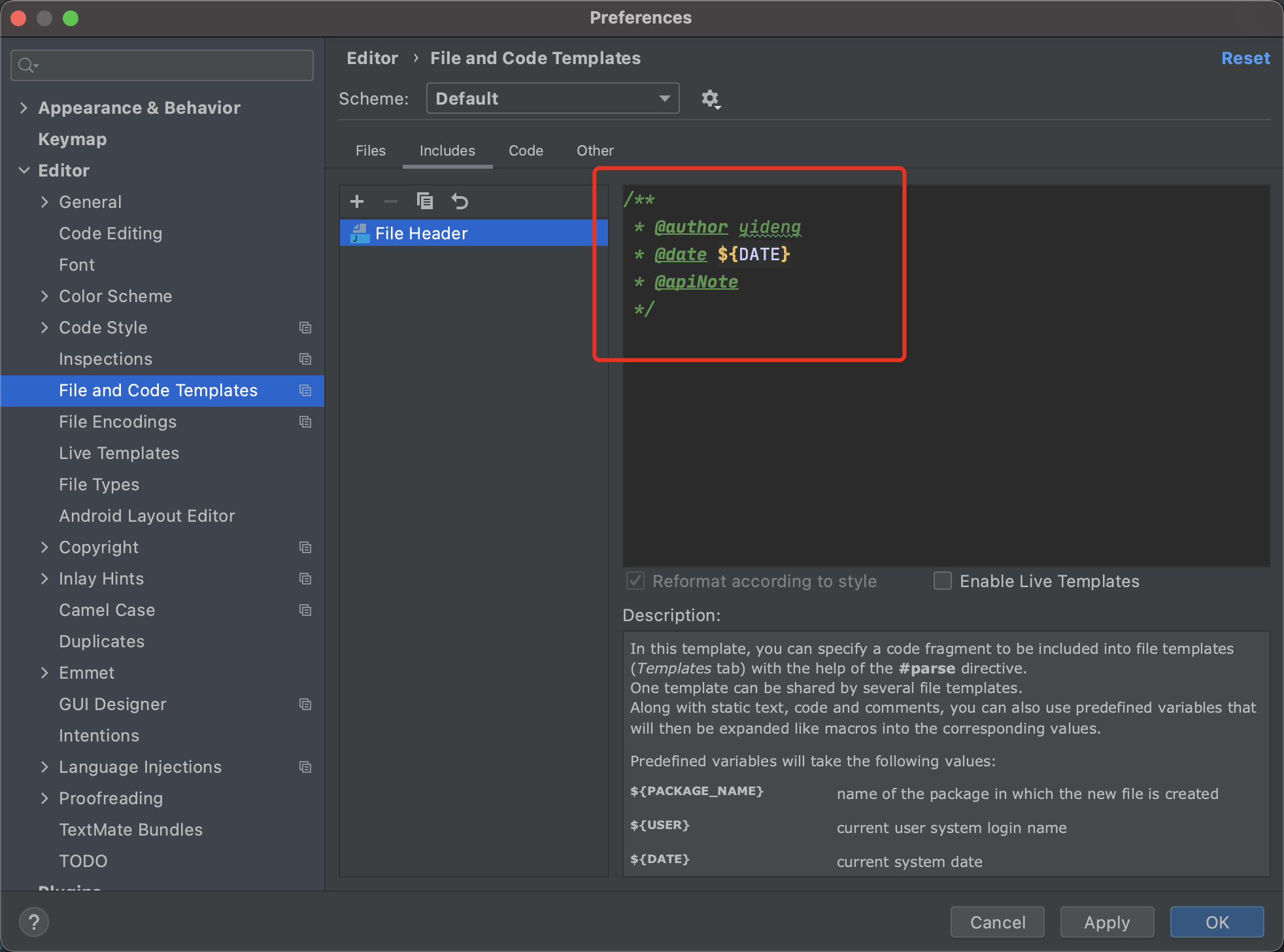
7. 创建文件时,自动生成作者和时间信息
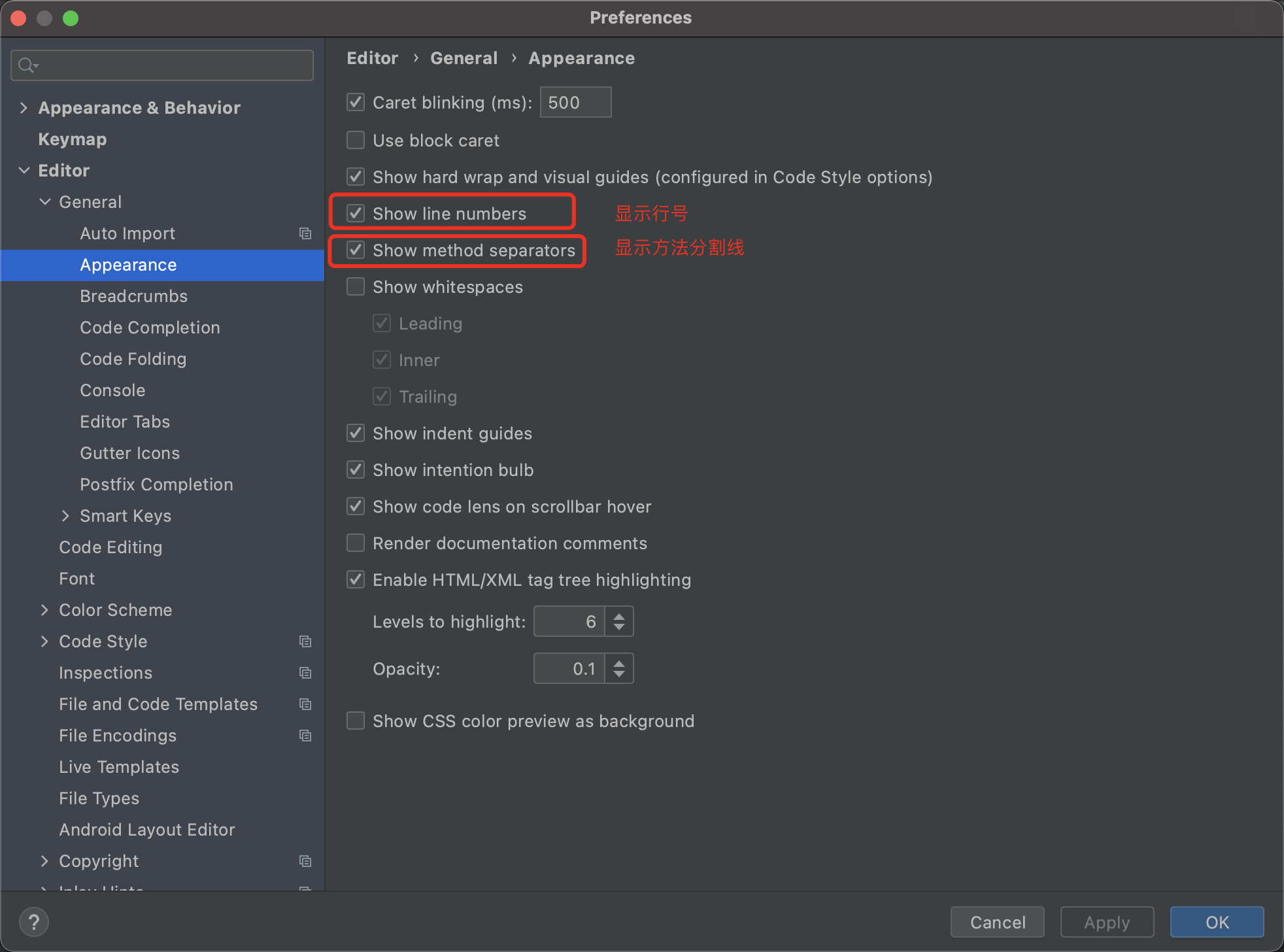
8. 显示行号和方法分割线
你还知道哪些关于Intelij idea高效操作或插件,一起在评论区分享吧!