贵州省遵义市住房城乡建设局网站wordpress 分类目录 插件
从事架构师岗位快2年了,聊一聊我和ChatGPT对架构的一些感受和看法
职位不分高低,但求每天都能有新的进步,永远向着更高的目标前进。
文章目录
- 踏上新的征程
- 架构是什么?
- 架构师到底是干什么的?
- 你的终极目标又是什么?
- 如果你想成为架构师该如何提升自己?
- 附图
时间是过得真快,就这么一晃就快过了2年了。自2021年5年以来,跌跌爬爬,在架构师的岗位上也快“混”迹2年了,是时候好好静下心来梳理梳理,好好想一想接下来的路该怎么走,如何才能获得更大的提升,毕竟留给快35岁程序猿的时间已经不多了。
下面,我想结合自己的经历,谈一谈自己对架构师岗位的感受和想法,也是希望这样能够更好地提醒和鞭策自己,时刻不要忘了,你的本质工作是一个【架构师】。
踏上新的征程
时钟拨回到2年前,那是2021年5月的那个夏天,因个人原因我向前东家提出了离开,留下曾经一起奋斗过的小伙伴。
在前东家时,我是挂职【资深嵌入式软件工程师】,也曾带领过一个小团队,7-8人,做出过一些成绩,也曾为公司的业绩扛过一些靶子,但终究还是职业发展的考虑,我选择了退出。
正是有萌生提出之意时,在脉脉上有位HR找到我,说是有个【嵌入式架构师】的岗位要找资深研发,对嵌入式开发的要求比较高,有没有兴趣试试。
说实在,之前我也不知道有公司会专门招聘【嵌入式架构师】这样的岗位,但我是知道一般的研发团队中,总是会有人要负责【架构】的工作,而且肯定得是团队总最资深的那一帮人在搞架构的事情。
就这样抱着好奇心,我就参加了那场面试,没想到的是那场面试非常的愉快,跟我的面试官(也就是我现在的老大)聊得非常投机,再后来工作上也的确给予了最大力度的支持和认可,有一种求得知音的感觉。
就这样,一场很顺利的面试结束,复试了2轮,顺利拿到Offer,于2021年5月份入职。
而在2022年末的特殊事情,我也顺利得到老板的认可,成为了公司的小股东。
祥文可见:成为了公司股东,而我却失眠了!
也是从时候开始,我萌生了【架构师李肯】这个技术IP。

架构是什么?
架构,本文中特指【软件架构】。坦白说,架构是一个比较虚的东西,它不像实物那样看得见摸得着,而是一种抽象的概念在里面。
恰巧,最近ChatGPT不是非常火吗?要不,我们来问一下它,看看它对架构的理解是怎么样的?
提问:架构是什么?
回答:架构是一种分层模型,用于描述软件系统的结构和行为。它定义了软件系统的模块、接口、职责和关系,从而使软件系统可以更好地满足用户的需求。
下面谈一下我对架构的理解:
架构是一种抽象的软件设计,它要着力于用技术的手段解决业务上遇到的可伸缩、可扩展、性能优、易用性等难题。
一般来说,一个优秀的软件架构,必须要满足横向可扩展,纵向可伸缩,系统性能还要能够看得住一定的压力测试,同时,对架构的使用者而言,应该有非常清晰易用的API接口,在整个设计中需要充分考虑架构的易用性。
就拿我现在做的嵌入式系统架构来说,毫无疑问,这里需要的架构就是必须支持各种对接业务的功能模块可以可快速扩展和和裁减,同时对硬件底层的抽奖设计保足够抽象,以便于架构快速地移植在各个芯片平台上。而且,各个芯片平台的性能特性需要发挥到最佳状态,满足各种商用的需求。另外,对应用开发团队也需要提供非常明确的API接口和文档,以便于基于该软件架构快速输出软件,达到商业落地的目的。
架构师到底是干什么的?
这个问题我相信外行人都比较迷,于是我先用这个问题问了一下ChatGPT,得到的答案是:
提问:架构师到底是干什么的?
回答:架构师是一种计算机技术专家,负责设计和构建软件系统或网络架构,以满足业务需求。架构师需要深入理解业务和技术,以确定系统的需求,并设计合适的架构,以满足这些需求。架构师还负责评估和选择合适的技术,实施和监控系统,以及维护系统的性能和安全性。
嗯,好像有点道理。那么,我顺着这层思路再补充谈一下我的看法。
回到了上面【什么是架构】这个问题后,我再结合我的实际工作内容说说我的这个架构师到底是干嘛的。我分为几个点来阐述:
架构师首要解决的,就是复杂多变的业务需求中,分析并提取中核心需求,并加以抽象设计,以便于使用软件技术解决这样的需求难题;这就要求架构师一定是对核心业务非常熟悉的,否则可能你设计的架构就偏离了实际业务需求,这无异于纸上谈兵,哪怕架构设计得再优秀,都无法落地。
对提取的核心需求进行拆解:提取出对应的可扩展性、可伸缩性、易用性、性能要求等各个方面的需求,形成需求矩阵,针对各个需求,分别设计核心架构,满足业务需求。
架构师可以说是业务需求跟应用开发的一个衔接者,对上是对业务需求团队负责,对下是对应用开发团队负责,这里面的汇总、分析、设计、协调都是必备的技能;他所要解决的是两个团队面临的迫切问题。
对内,还需要负责核心技术难题的攻关:遇到团队中的疑难技术问题,需要攻关介入的时候,毫无疑问,架构师团队要冲在最前面,为后面的业务团队和应用开发团队铺平前进的道路。
对外,还需要负责业内核心前沿技术的调研和学习:这里面是一个进阶学习的过程,每个架构师团队必须要保持一定的学习能力,观测业内的技术架构方向,不一定非得追最新最热的技术方向,但至少你要能懂,这项新技术能帮我们解决什么样的问题。也许,将来我们就能用上它。
你的终极目标又是什么?
去年年末的时候,我写过一篇文章,叫 【架构师李肯】带你走进架构师的一天
里面有这么一章节:
正好俗语所说:“不想当将军的士兵,不是一个好的士兵!”
换到我身上,我认为是:“不想当CTO的架构师,不是一个好的架构师!”
我的更远大目标就是,有朝一日,挂帅CTO,至于迎娶白富美的后话,就还是别了,早已心有所属。
回想自己一路升级打怪,从技术小白,踏入助理工程师的岗位,慢慢提升自己,开始走向中级工程师,逐渐可以独立接项目了,锻炼了一些日子,开始担任高级工程师,开始考虑更全面了,需要承担技术攻坚的重任;再后来,跨越到资深工程师,也开始带团队了,不再单兵作战,需要为团队负责到底;而现在,架构师一职,承担的不仅仅是本部门的技术工作,还需要宏观考虑技术的延展性和前瞻性,某些情况下甚至关乎着整条业务线的生存,不可谓影响不大。
而如果走向CTO的岗位,那直接就关系整个公司的技术脉络,这可直接影响公司的存亡,压力和挑战并存。
我有时候也问我自己,准备好了吗?我希望我自己能给出肯定的答案:“ Yes,I’m ready !"

回到现实吧,朝着你的目标前进就好了,希望就在眼前。
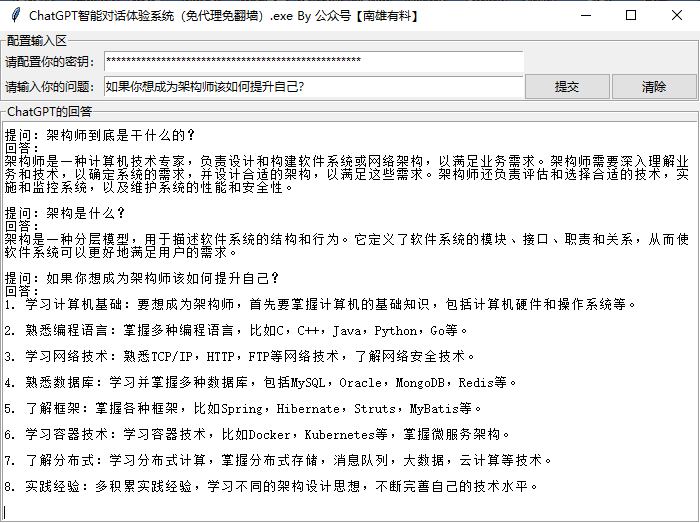
如果你想成为架构师该如何提升自己?
这个问题可能也是大家比较关心的,同样的,我们也问一下ChatGPT吧。
提问:如果你想成为架构师该如何提升自己?
回答:
- 学习计算机基础:要想成为架构师,首先要掌握计算机的基础知识,包括计算机硬件和操作系统等。
- 熟悉编程语言:掌握多种编程语言,比如C,C++,Java,Python,Go等。
- 学习网络技术:熟悉TCP/IP,HTTP,FTP等网络技术,了解网络安全技术。
- 熟悉数据库:学习并掌握多种数据库,包括MySQL,Oracle,MongoDB,Redis等。
- 了解框架:掌握各种框架,比如Spring,Hibernate,Struts,MyBatis等。
- 学习容器技术:学习容器技术,比如Docker,Kubernetes等,掌握微服务架构。
- 了解分布式:学习分布式计算,掌握分布式存储,消息队列,大数据,云计算等技术。
- 实践经验:多积累实践经验,学习不同的架构设计思想,不断完善自己的技术水平。
好吧,答案跟我想的完全不太一样。毕竟我目前专注的嵌入式系统架构设计这一块。
但是我认为架构的核心理念是一致的,你需要扎实的基础技术知识来铺垫,最重要的是培养自己敏锐的【架构】思维。
比如用到一个很好用的框架,一个很帮的开源项目,多去想想别人是如何从【架构】去考虑问题的,同时又是如何设计这个【架构】已满足这些需求问题的,多动脑子去思考和整理,慢慢积累起来就会有比较敏锐的【架构】观。
又比如我们学习和使用的Linux系统,它里面可是浓缩了世界各地最优秀的那帮码农的精华,包含了大量的【架构】设计理念,而我们作为它的使用者和开发者,更是应该深入学习它,可以是某一模块的设计,或者某一类模型的设计,等你能把这些架构摸透了,差不多你也就成了架构师。
常言道:【书中自有黄金屋】,我个人觉得看对应领域的专家级书籍,也是一种非常棒的学习方式。站在巨人的肩膀上,可以帮助你爬得更快,升得更高。
经常在后台收到小伙伴的私信,问我有没有在架构方面比较优秀的书籍推荐。
这不,最近刚出了一本书籍,叫《持续架构实践:敏捷和DevOps时代下的软件架构》,它的一推出,立马轰动业界。
作为架构领域的从业者,我第一时间拿到了书本,匆匆看了几章,有种酣畅淋漓的感觉,甚至有种相见恨晚的意味。
软件架构领域正在爆发一场新的革命。Gartner权威发布2023年十大科技趋势之一**“可持续IT架构”**,可持续架构得到越来越多从业人员认同。创建和维护可持续的软件架构对于架构师和工程师而言也是一项巨大的挑战。
感兴趣的朋友,可以多关注一下这本书《持续架构实践:敏捷和DevOps时代下的软件架构》,尤其是希望从事架构师岗位的小伙伴,也许它能帮你解开很多心中的疑团。

更多关于《持续架构实践:敏捷和DevOps时代下的软件架构》书籍的介绍,请参考社区帖子介绍,详见 https://bbs.csdn.net/topics/613441520。
附图
这里有朋友好奇ChatGPT的玩法,又没有合适的工具来体验,所以来问到我,我用我那8毛钱的Python技术写了一个小工具,只需要输入API-KEY就可以了,不需要代理,也不需要fanqiang,可以试用试用。
这个小工具,有需要的可以私我,友情共享。