网站建设的售后服务百度站长推送
1.1. 基础概念
EFK不是一个软件,而是一套解决方案,开源软件之间的互相配合使用,高效的满足了很多场合的应用,是目前主流的一种日志系统。 EFK是三个开源软件的缩写,分别表示:Elasticsearch , Filebeat, Kibana , 其中Elasticsearch负责日志保存和搜索,Filebeat负责收集日志,Kibana 负责界面。
Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。
Filebeat是数据采集的得力工具。将 Filebeat和您的容器一起置于服务器上,然后便可在 Elastisearch 中集中处理数据。
Kibana 核心产品搭载了一批经典功能:柱状图、线状图、饼图、旭日图,等等。不仅如此,您还可以使用 Vega 语法来设计独属于您自己的可视化图形。所有这些都利用 Elasticsearch 的完整聚合功能。
1.2. 日志排查
1.2.1. 如何在界面查看日志
日志在Discover模块:
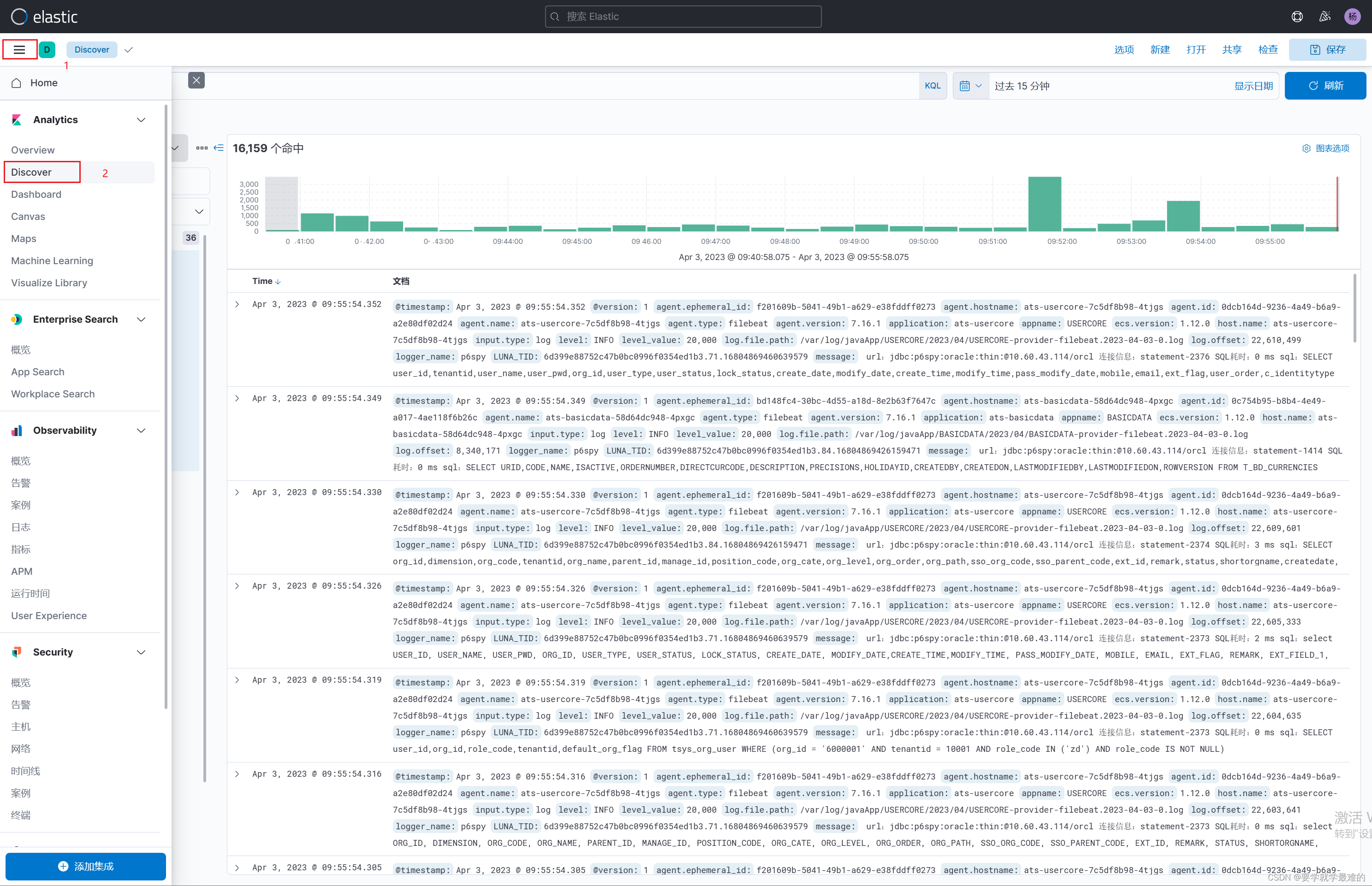
可以通过修改索引模式来查看不同机器(集群)下的日志:

添加日志需要展示的字段:


1.2.2. 查询某个服务的日志
1、选择集群环境
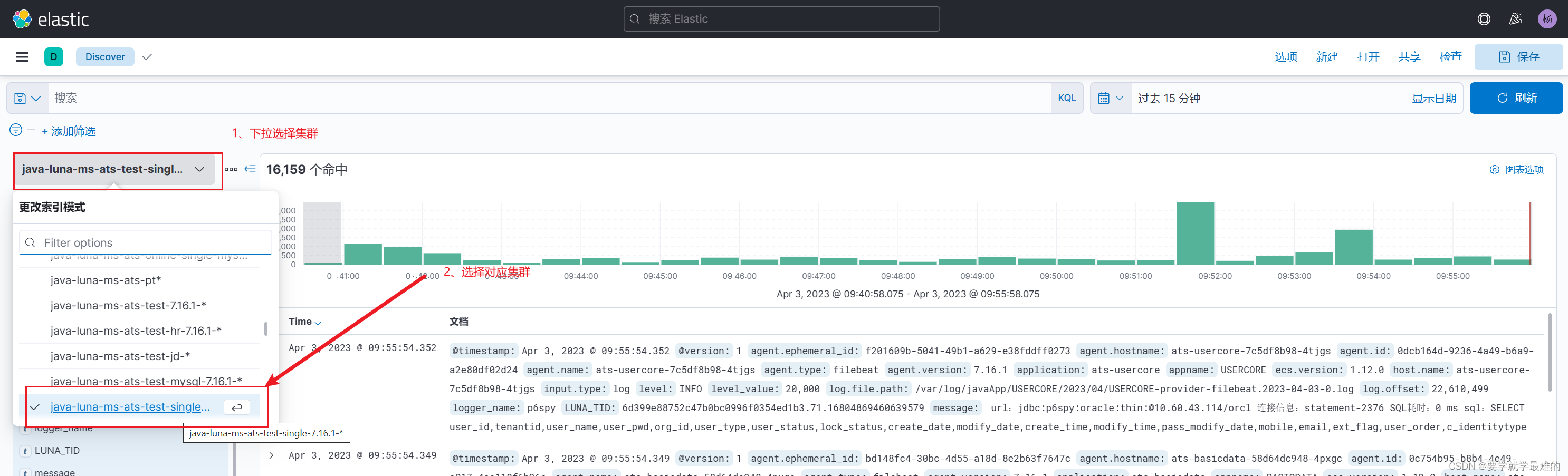
2、添加application 或者appname过滤条件,选择需要查看服务的日志
可以通过左侧字段筛选来选择想要查看的应用日志

也可以通过“添加筛选”来筛选应用日志

3、选择日志时间范围

1.2.3. 查询错误日志
1.2.3.1. 从前端搜索错误日志
1、浏览器报错时,点击F12。找到对应报错的请求,复制traceId

2、筛选traceId,查询日志

1.2.3.2. 搜索任务错误日志
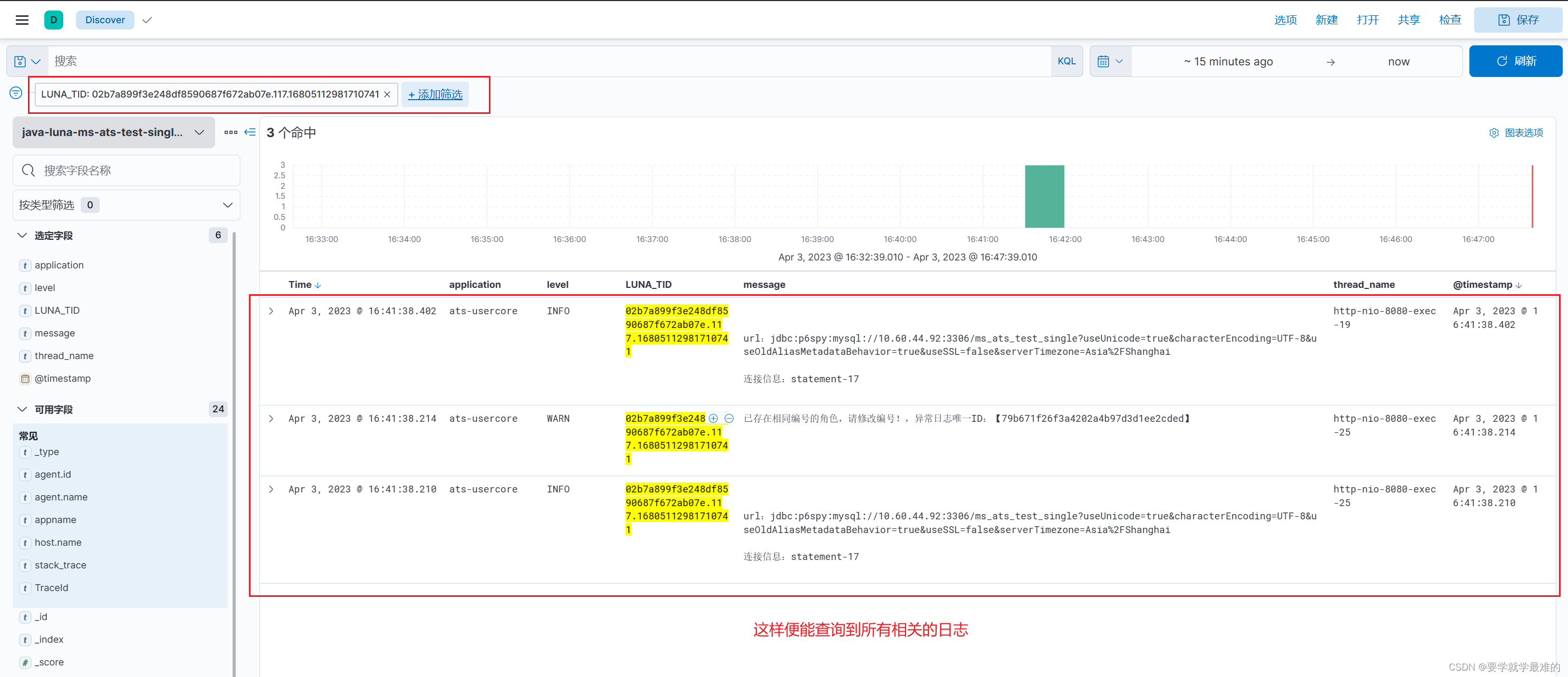
1、在“任务运行历史”页面找到失败的任务名称,复制溯源ID【】括号中的id内容

2、在kibana中输入message: "8b8c755d6de44f8ea1f3105b56090cb3",复制得到的LUNA_TID

3、搜索LUNA_TID

1.2.4. 搜索技巧
- 精确搜索
搜索框内输入message: "rowversion from t_bd_currencies"。针对message字段进行搜索,在搜索的时候不会区分大小写,也就是说,ROWVERSION FROM T_BD_CURRENCIES也是会被搜索出来的。上面的"rowversion from t_bd_currencies"使用了引号,这3个单词会被作为一个词进行查询,不会再进行分词,也就是说匹配的时候只会匹配rowversion from t_bd_currencies这样的顺序匹配,而不会匹配出rowversion,test from t_bd_currencies

- 多字段匹配搜索
针对message搜索,输入message: rowversion from t_bd_currencies,去除上面例子中的双引号。搜索结果为message中包含rowversion或from或t_bd_currencies的结果。

- 连接词搜索
搜索时,可以用and or not三种连接词进行搜索。
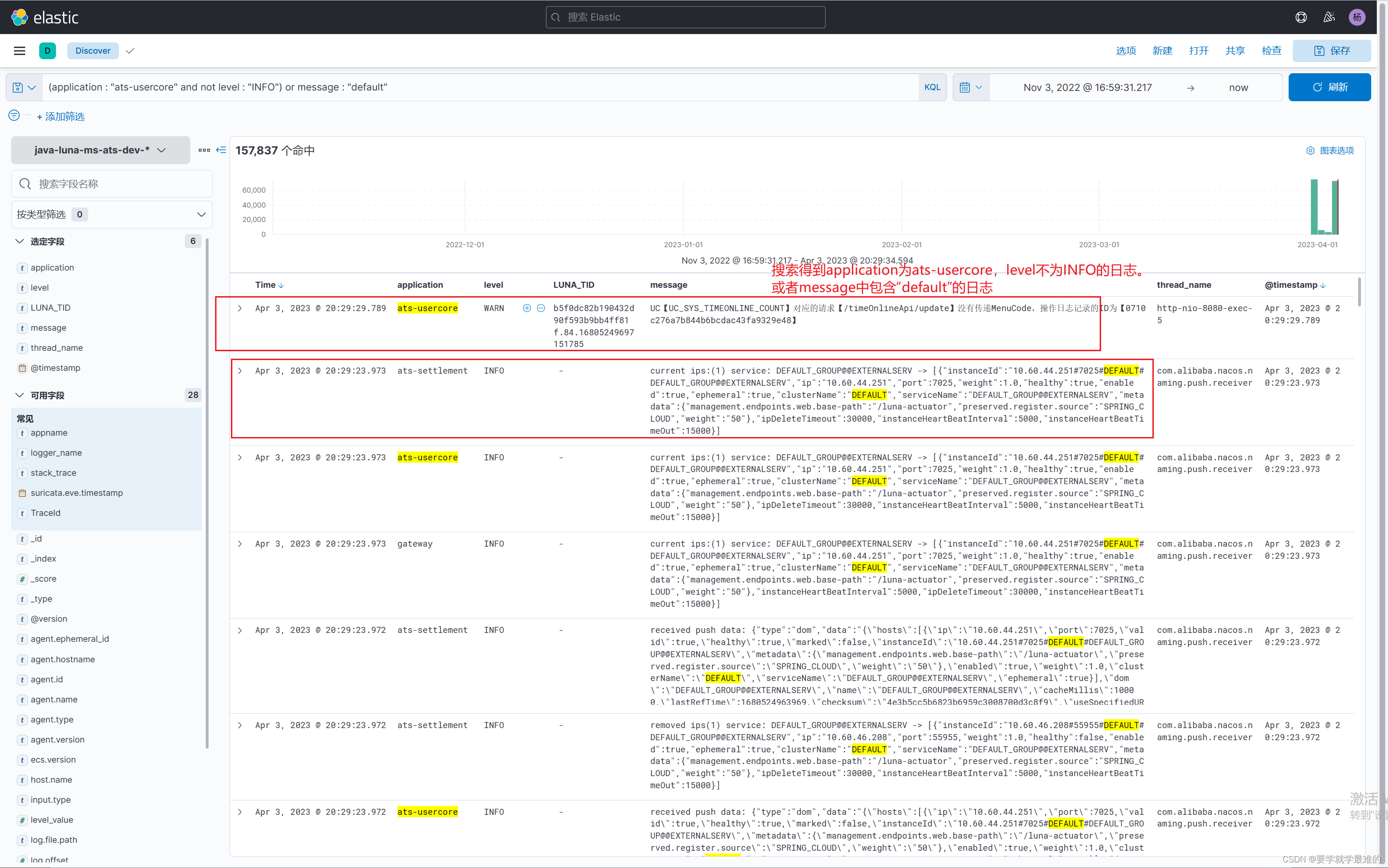
搜索(application : "ats-usercore" and not level : "INFO") or message : "default"。可以得到application为ats-usercore且日志级别不为INFO的日志,或者得到message字段中包含default的日志。