商丘网站建设推广公司石河子市建设局网站
消息服务--Kafka的简介和使用
- 前言
- 异步
- 解耦
- 削峰
- 缓存
- 1、消息队列
- 2、kafka工作原理
- 3、springBoot KafKa整合
- 3.1 添加插件
- 3.2 kafKa的自动配置类
- 3.21 配置kafka地址
- 3.22 如果需要发送对象配置kafka值的序列化器
- 3.3 测试发送消息
- 3.31 在发送测试消息的时候由于是开发环境中会遇到的问题
- 3.4 监听消息-kafkaListener
前言
异步

解耦
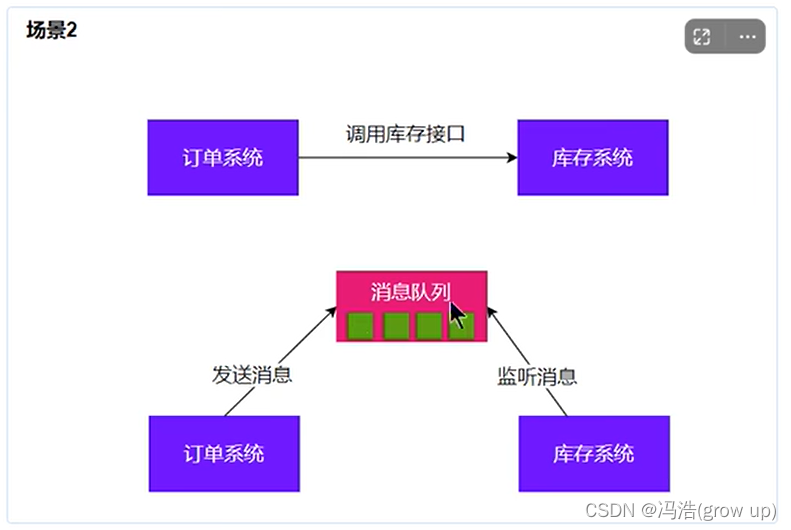
削峰
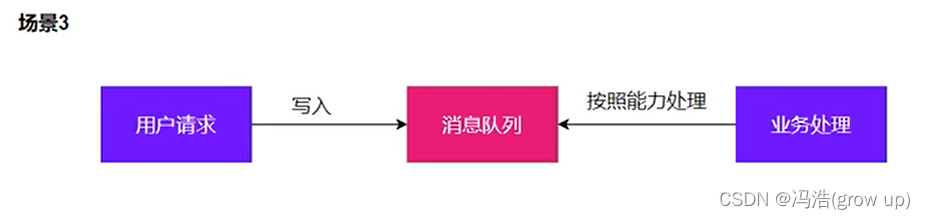
缓存
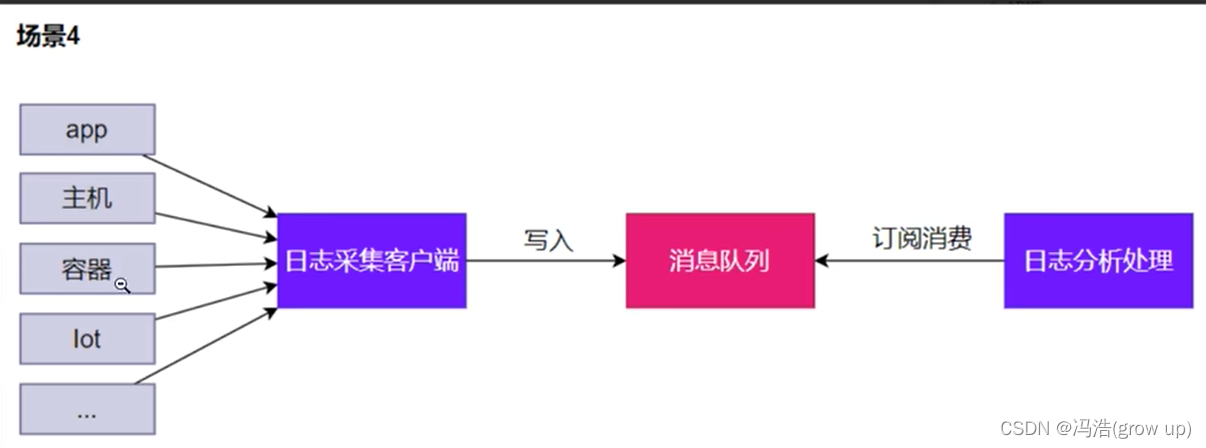
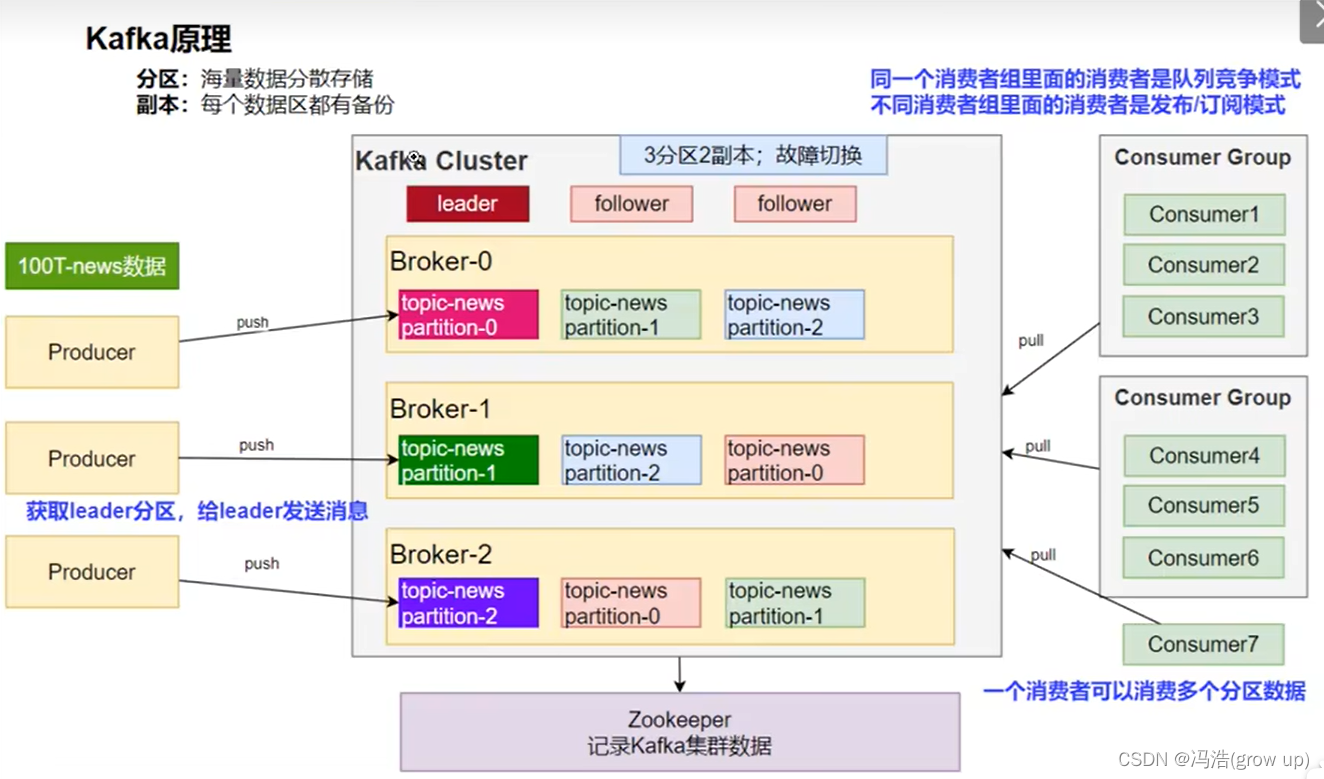
1、消息队列
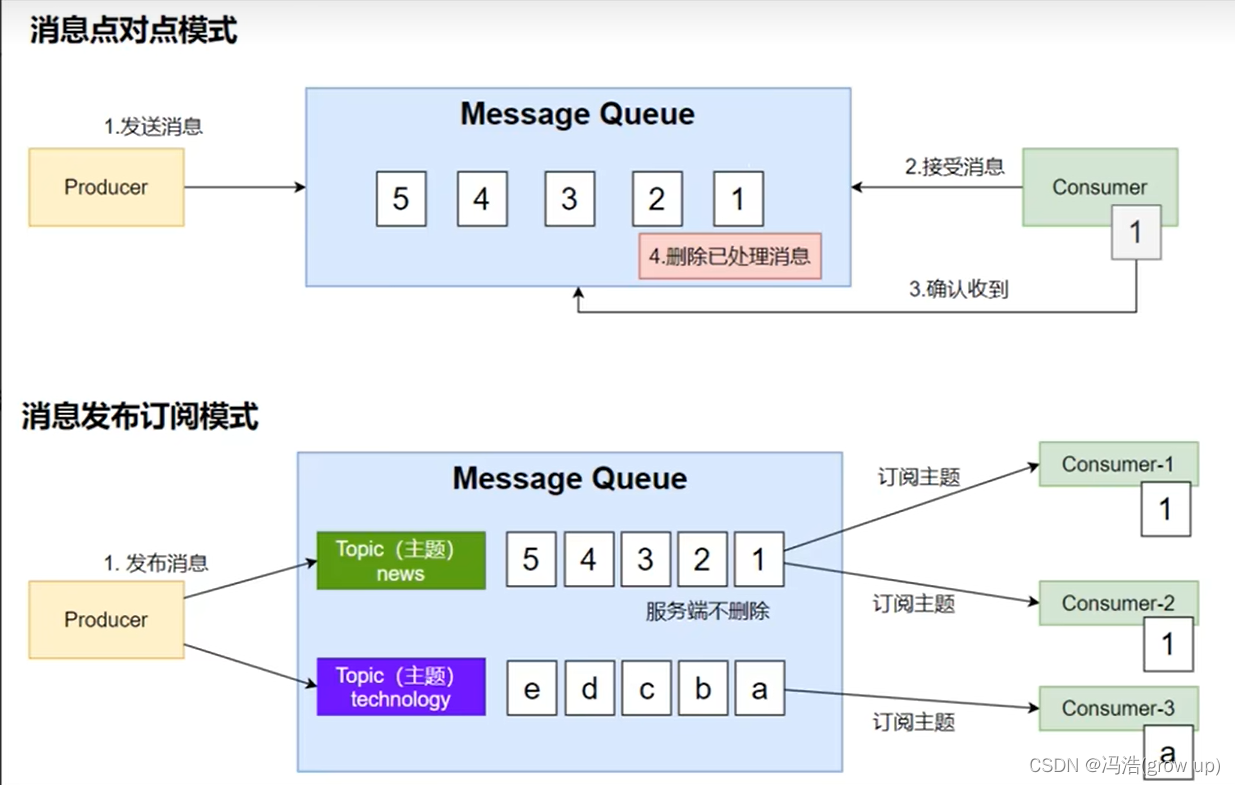
2、kafka工作原理
3、springBoot KafKa整合
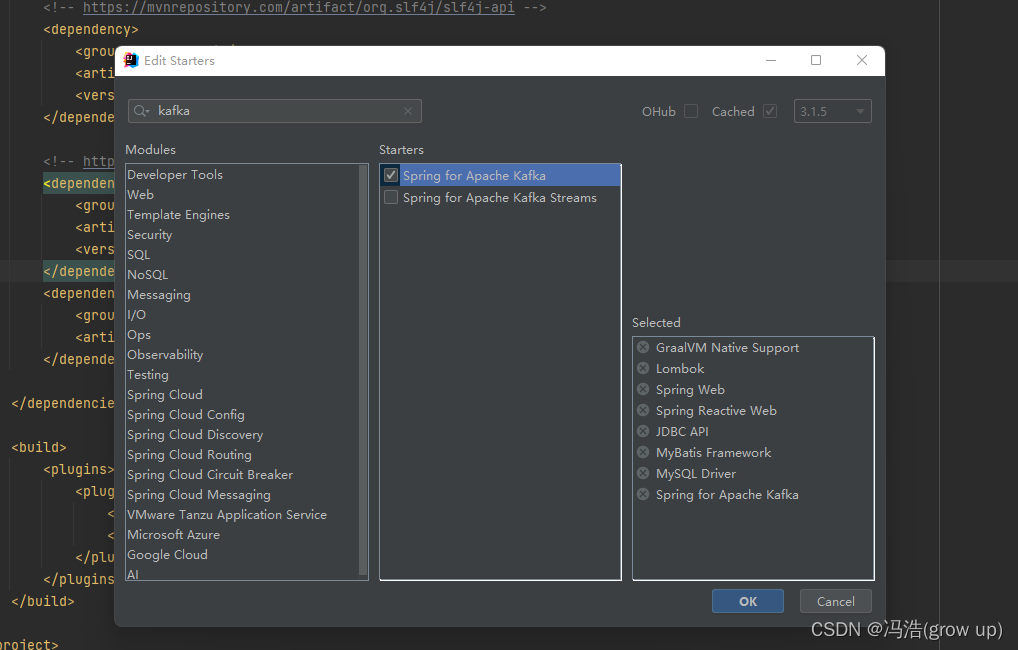
3.1 添加插件
安装完成后需要刷新maven
3.2 kafKa的自动配置类
kafkaautoConfiguration 自动配置提供了以功能
1、KafkaProperties: kafka的所有配置 以spring.kafka 开始- bootstrapServers: kafka集群的所有服务器地址- properties: 参数设置- consumer: 消费者- producer: 生产者
2、 @EnableKafka: 开启Kafka的注解驱动功能
3、 KafkaTemplate: 收发消息
4、 KafkaAdmin: 维护主题等......
3.21 配置kafka地址
//两种方式
spring.kafka.bootstrap-servers[0] = 8.130.32.72:9092
//也可以通过逗号分隔
spring.kafka