同一ip网站购物网站建设网页推广
程序计数器
物理上被称为寄存器,存取速度很快。
作用
记住下一条jvm指令的执行地址。
特点
线程私有,和线程一块出生。
不存在内存溢出。
虚拟机栈
每个线程运行时所需要的内存,称为虚拟机栈。
每个栈由多个栈帧组成,对应着每次方法调用时所占用的内存。
每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法。(栈顶对应的就是活动栈帧)
思考
栈内存分配越大越好吗?
不是,栈内存分配的很大的话,线程数就会减少,因为物理分配的内存是固定的。
垃圾回收是否涉及栈内存?
不会涉及,因为出栈后会被自动弹出,轮不到垃圾回收机制来处理。垃圾回收机制只回收堆里面的无用对象。
方法内的局部变量是否线程安全?
如果方法内的局部变量没有逃离方法的作用访问,它的线程是安全的;
如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全。
栈内存溢出
栈帧过多导致栈内存溢出;
栈帧过大导致栈内存溢出。
线程运行诊断
CPU占用过多
在Linux下,用“top”命令定位哪个进程对CPU的占用过高
ps H -eo pid,tid,%cpu | grep 进程id (进一步定位是哪个线程引起的cpu占用过高)
jstack进程id
可以根据id找到有问题的线程,进一步定位到问题代码的源代码行号。
本地方法栈

因为操作系统使用c/c++写的,java并不能直接和操作系统打交道,就需要本地方法栈,比如Object类的一些方法。
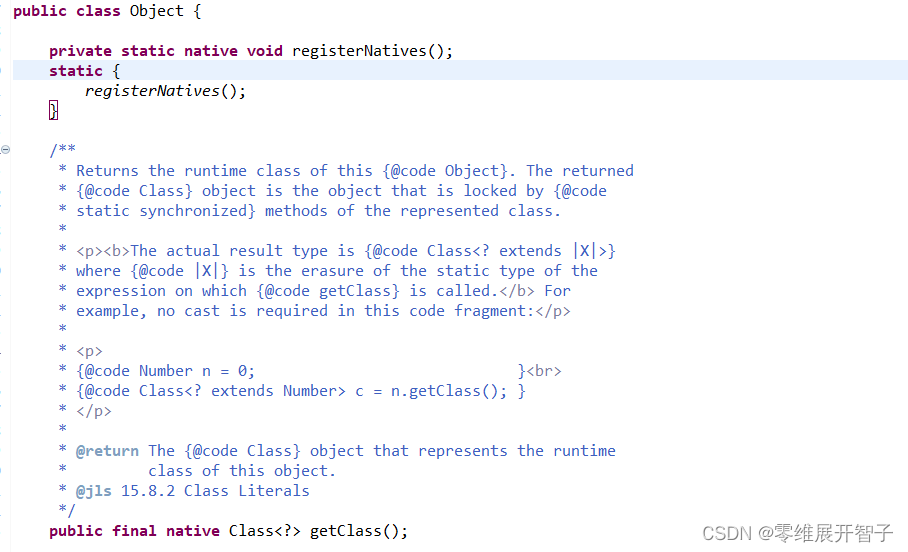
像这种以native返回值类型说明的就是。
堆
通过new关键字,创建对象都会使用堆内存
特点
线程共享的,堆中对象都需要考虑线程安全的问题。
有垃圾回收机制。
堆内存溢出
含有对象的循环没有终止条件等……
堆内存诊断
JPS工具
查看当前系统中有哪些Java进程
JMAP工具
查看堆内存占用情况
JCONSOLE工具
图形界面的,多功能的监测工具,可以连续监测。
例如,垃圾回收后内存占用依然很高的情况下就可以采用这些工具查看。
方法区
组成
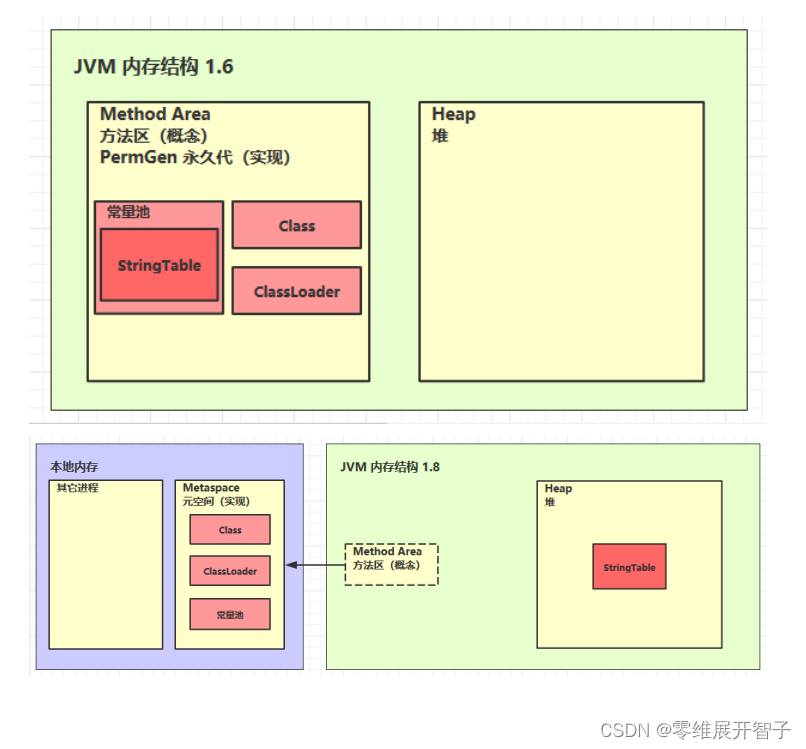
方法区内存溢出
JDK1.8以前会导致永久代内存溢出
java.lang.OutofMemoryError: PermGen space
JDK1.8之后会导致元空间内存溢出
java.lang.OutofMemoryError: Metaspace
场景 spring中动态代理生成对象时有可能,mybatis。
运行时常量池
常量池
就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、自面量等信息。
运行时常量池
常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址。