2个小时学会网站建设公司要怎么注册
CSS中相对定位与绝对定位的区别及作用
- 场景复现
- 核心干货
- 相对定位
- 绝对定位
- 子绝父相🔥🔥
- 定位总结
- 绝对定位与相对定位的区别
场景复现
在学习前端开发的过程中,熟练掌握页面布局和定位是非常重要的,因此近期计划出一个专栏,详细讲述如何优雅高效地实现前端页面布局和渲染。包括css中的相对定位和绝对定位,好用的flex布局和grid布局,以及自适应宽高等等实用干货,文章从基础知识到项目实战,层层递进帮助学习前端技术。本期文章主要介绍的是CSS中的相对定位与绝对定位,包括相关用法和区别。
核心干货
定位的作用:实现某个元素可以自由地在一个盒子内移动位置,并且压住其他盒子。
相对定位
相对定位可以理解为“相对于”它的起点进行移动
语法:
选择器{ position:relative;}
代码示例:👇👇👇👇
html部分:
<div class="box1"></div>
<div class="box2"></div>
css部分:
.box1 {width: 200px;height: 200px;background-color: aquamarine;}.box2 {width: 200px;height: 200px;background-color: rgb(0, 203, 254);}
效果图:
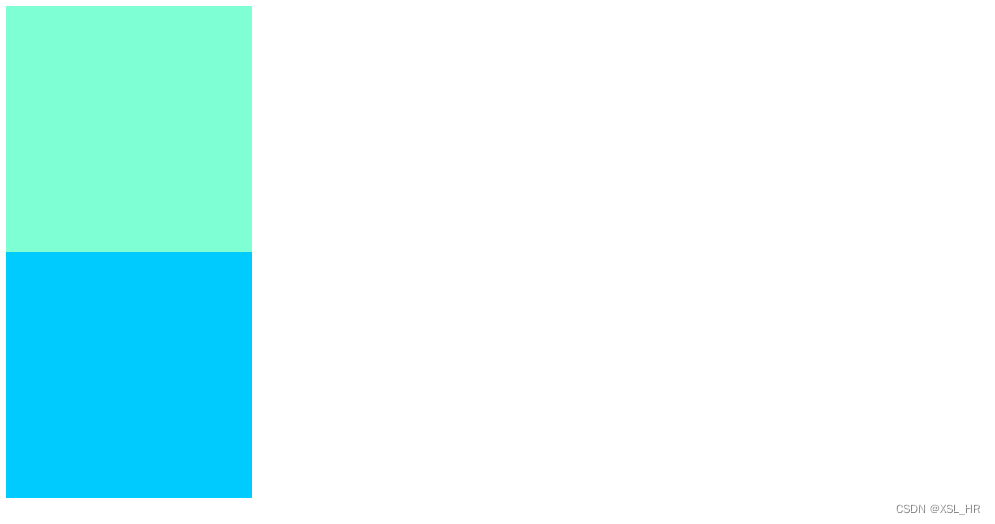
此时我们为其中一个盒子添加相对定位👇👇
css部分:
.box1 {/* 相对定位*/position: relative; top: 50px;left: 50px;width: 200px;height: 200px;background-color: aquamarine;}
效果图:
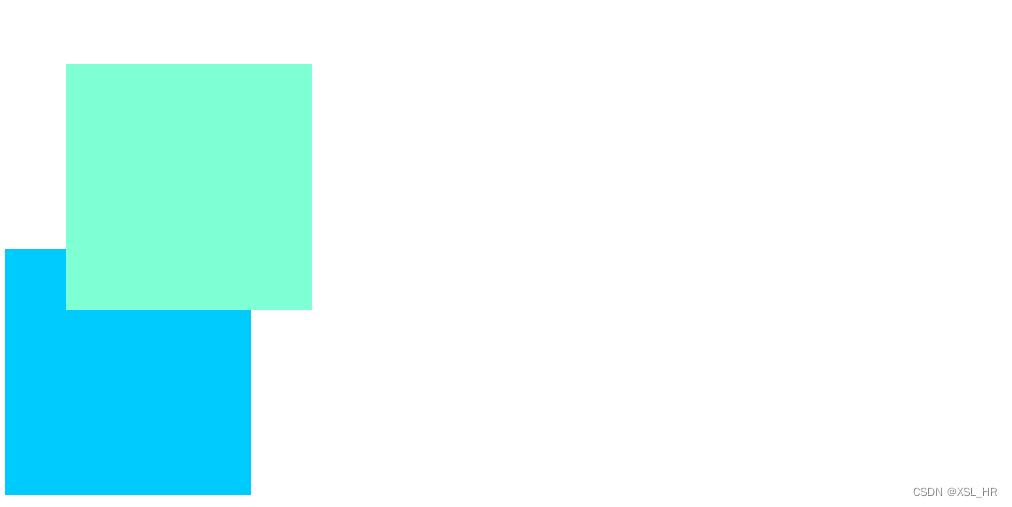
总结:
- 相对定位实际是元素相对自己原来的位置移动,参照物是自己
- 另外一个元素不脱标,继续保留原来的位置
绝对定位
绝对定位可以理解为一浏览器为父节点来定位自己
语法:
选择器{ position:absolute;}
代码示例:👇👇👇👇
html部分:
<div class="box4"></div>
css部分:
.box4 {width: 200px;height: 200px;background-color: rgb(255, 161, 60);}
下面我们为这个盒子添加绝对定位👇👇
css部分:
.box4 {/* 绝对定位*/position: absolute;left: 0;bottom: 0;width: 200px;height: 200px;background-color: rgb(255, 161, 60);}
效果图:
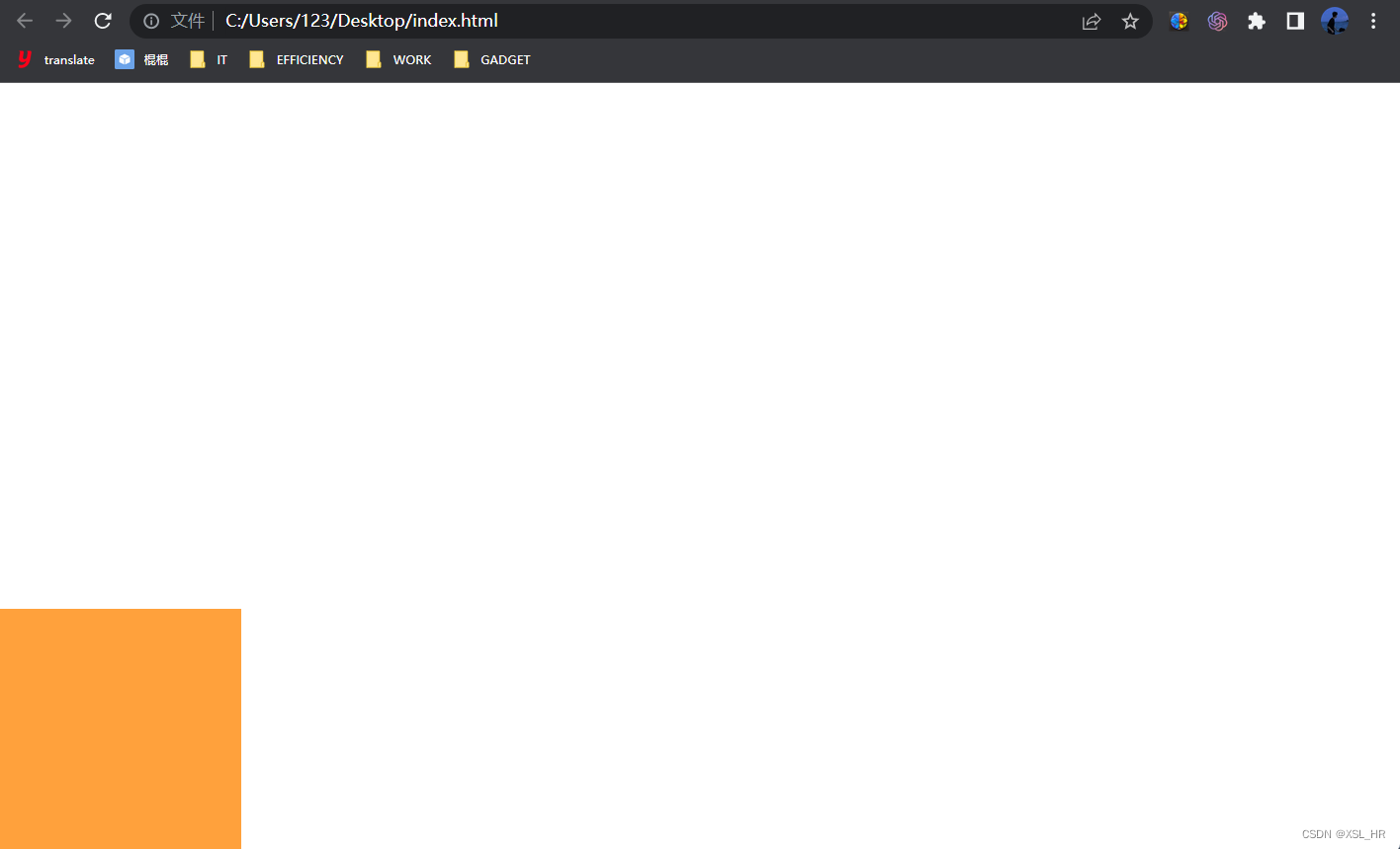
不难发现,橙色的盒子相对于浏览器页面绝对定位,距离底部和左侧都是0px的距离。
绝对定位的特点:
- 1、若没有父级元素或父级元素没有定位,则以浏览器为准定位;
- 2、如果父级元素有定位,则以最近一级的有定位父级元素为参考点移动位置;
- 3、绝对定位不占有原先位置。
子绝父相🔥🔥
- ①子级绝对定位,不会占有位置,可以放到父级盒子的任何一个地方,不会影响其他盒子;
- ②父级盒子需要加定位限制子盒子在父级盒子内显示;
- ③父级盒子布局时,需要占有位置,因此父级只能是相对定位。
代码示例:👇👇👇👇
html部分:
<div>----------------绝对定位------------</div>
<div class="box3"><div class="box4"></div></div>
css部分:
.box3 {position: relative; width: 300px;height: 300px;background-color: rgb(178, 96, 255);}.box4 {/* 绝对定位*/position: absolute;left: 0;bottom: 0;width: 200px;height: 200px;background-color: rgb(255, 161, 60);}
效果图:

如果我们将父元素里面的相对定位去掉,就会呈现下面的效果:

如果将子元素的绝对定位去掉,保留父元素的相对定位,就会呈现如下效果:👇👇

定位总结

绝对定位与相对定位的区别
绝对定位使元素的位置与文档流无关,因此不占据空间。可以理解为绝对定位将元素从原来位置拿走,后面的元素就会占据绝对定位元素的位置。如同排队一样,前面的人走了,后面的人就会前进占去离开的人的位置。
代码示例:
<style>body {background-color: aquamarine;}.box {width: 100px;height: 100px;background-color: pink;float: left;margin: 15px;}.two {position:absolute;left: 20px;top: 20px;}</style>
</head>
<body>
<div class="box one">1</div>
<div class="box two">2</div>
<div class="box three">3</div>
<div class="box four">4</div>
</body>
效果图:

相对定位与绝对定位相反,它移动后原本所占的空间仍保留。可理解为它进行定位后,之前的位置后面的元素不可占据。如同私人车库停车一样,车子离开后,别的车不可以停在那个车库。
代码示例:
<style>body {background-color: aquamarine;}.box {width: 100px;height: 100px;background-color: pink;float: left;margin: 15px;}.two {position:relative;left: 20px;top: 20px;}</style>
</head>
<body>
<div class="box one">1</div>
<div class="box two">2</div>
<div class="box three">3</div>
<div class="box four">4</div>
</body>
效果图:

以上就是关于CSS相对定位和绝对定位相关知识的分享,相信看完这篇文章的小伙伴们一定有了一定的收获。当然,可能有不足的地方,欢迎大家在评论区留言指正!
