郑州做网站齿轮网站的建设技术有哪些内容
一、前期准备
我们的目的是让设备物尽其用,将旧电脑做成NAS存储系统后可以使用新电脑进行访问(Windows / Linux / IOS系统都可以访问)。在开始之前先来看看安装成功效果图吧!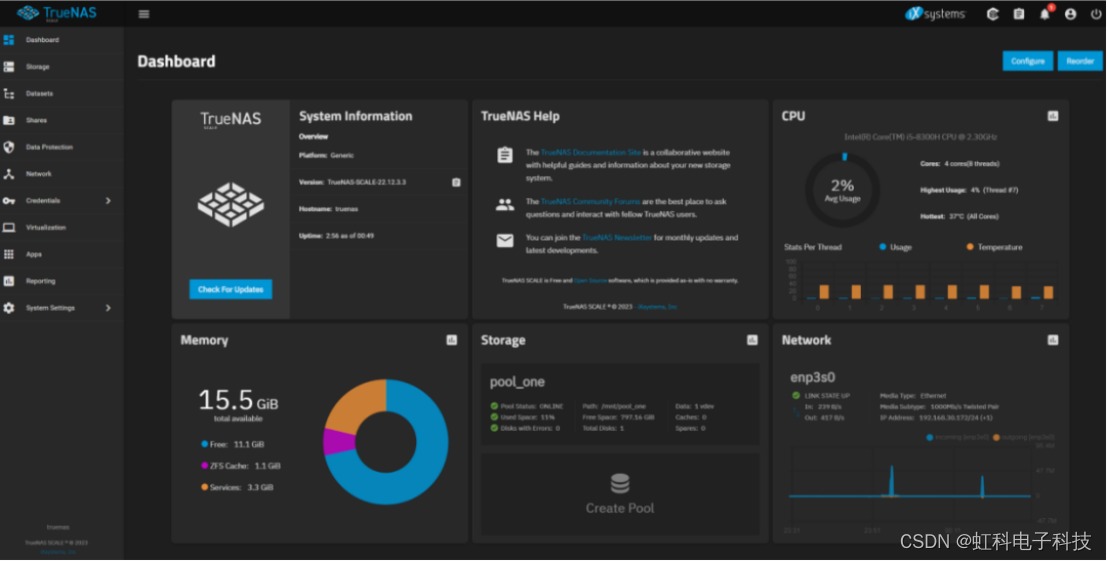

1.设备准备
(1)一台旧电脑:我们的工程师使用的是戴尔游匣G3 3579(win11系统 + 16G内存(8G是自己加的)+4核CPU+128G NVMe固态硬盘+1T机械硬盘)
(2)一根网线:连接到旧电脑上,为旧电脑提供网络。
ps.也可以使用wifi,但需要保证路由器开启dhcp自动分配IP地址的功能,不清楚的话还是建议使用网线。
(3)另一台电脑:需和旧电脑在一个局域网内或者可以访问到旧电脑。
(4)一个容量大于16G的U盘:用来制作启动盘。
注意!安装TrueNAS系统的前提是电脑必须配备2块硬盘,一块做系统盘,另一块做数据盘,一般不建议将系统安装在U盘或移动硬盘上。
2.安装版本
本次安装的TrueNAS系统的版本为 TrueNAS-SCALE-22.12.3.3。
工程师个人比较喜欢docker,所以选择SCALE版本,若想安装CORE版本,安装过程与本教程类似,只需更换镜像即可。
3.整体设计思路
(1)制作TrueNAS系统的U盘启动盘
(2)重装旧电脑的系统
(3)设置数据共享
二、具体安装流程
看似简单的设计思路其实暗藏陷阱,为了避免踩坑,建议大家要跟紧工程师的步骤进行安装哦~
1、在新电脑上制作TrueNAS系统的U盘启动盘
(1)下载TrueNAS Scale的镜像
-
下载地址: https://www.truenas.com/download-truenas-scale/
-
选择“No Thank you, I have already signed up.”跳过注册步骤
-
下载最新的稳定版,当然您也可以选择历史稳定版本
 (2)将U盘插入新电脑,我们使用的写盘工具是Rufus ,下载地址为https://rufus.ie/zh/,选择适合自己的版本下载,工程师选择的是第一个标准版。下载完成后打开这个应用程序。
(2)将U盘插入新电脑,我们使用的写盘工具是Rufus ,下载地址为https://rufus.ie/zh/,选择适合自己的版本下载,工程师选择的是第一个标准版。下载完成后打开这个应用程序。 -
设备部分选择您的U盘
-
引导类型选择刚刚下载的truenas镜像
-
其他配置不需要修改,它会自动按照我们镜像的属性进行设置
-
点击开始,选择以DD镜像模式写入
-
等待写入完成,绿色的进度条到头即可
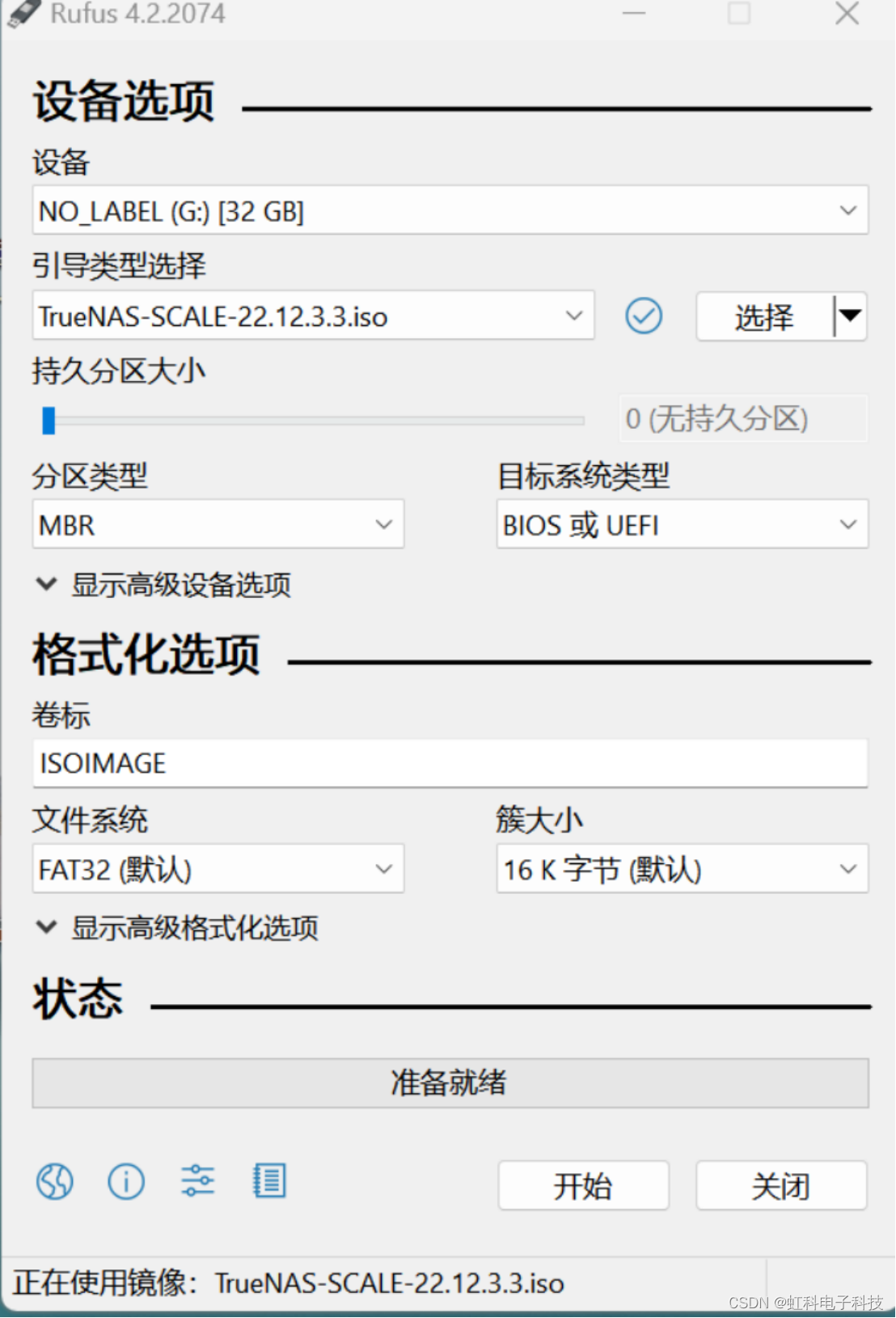
(3)弹出U盘,把它插到旧电脑上
2、重装旧电脑系统
(1)把U盘插入到旧电脑上以后,我们让电脑进行重启进入BIOS界面
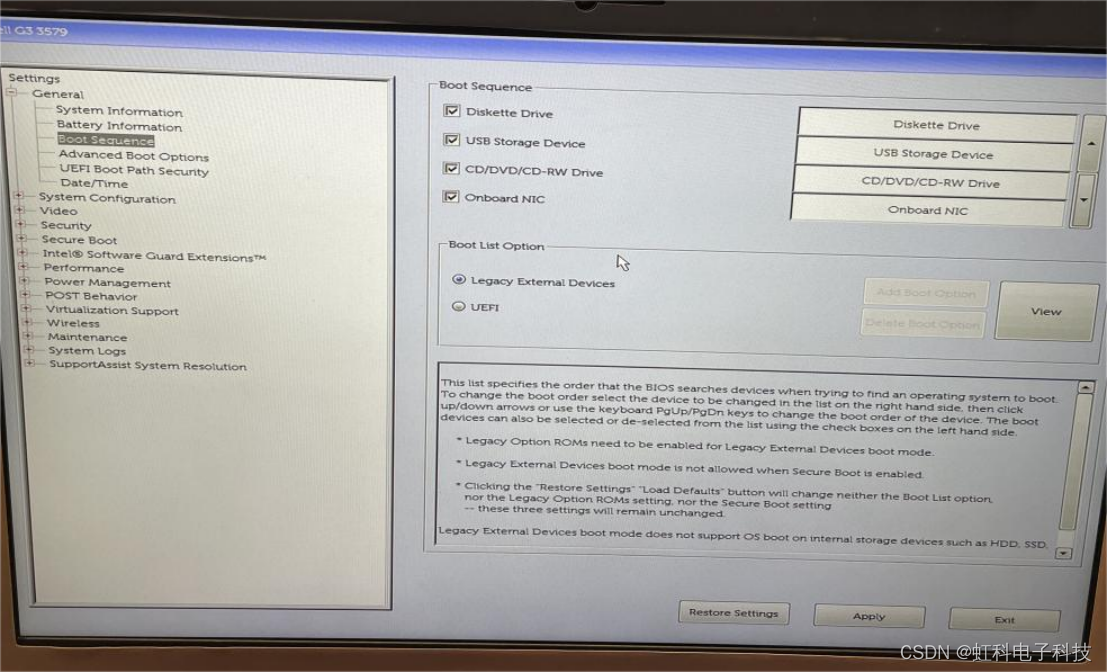
BIOS界面
(2)在 BIOS 中找到启动选项:在 BIOS 设置界面中,寻找一个名为"Boot"、“Boot Sequence”、"Boot Options"或类似的选项。使用键盘上的方向键导航到该选项并进入。
(3)设置启动顺序:在启动选项中,您会看到可用于启动的设备列表。将 U 盘(通常被识别为一个 USB 设备)移动到列表中的首选项。您可以根据提示使用键盘上的特定按键来移动设备的位置。
(4)保存设置:在设置完启动顺序后,确保将更改保存。通常,您可以按下一个键(如F10)来保存并退出 BIOS 设置。系统将会重新启动。
(5)系统从 U 盘启动:如果一切设置正确,系统会从您制作的启动 U 盘中启动。您将看到如下界面。
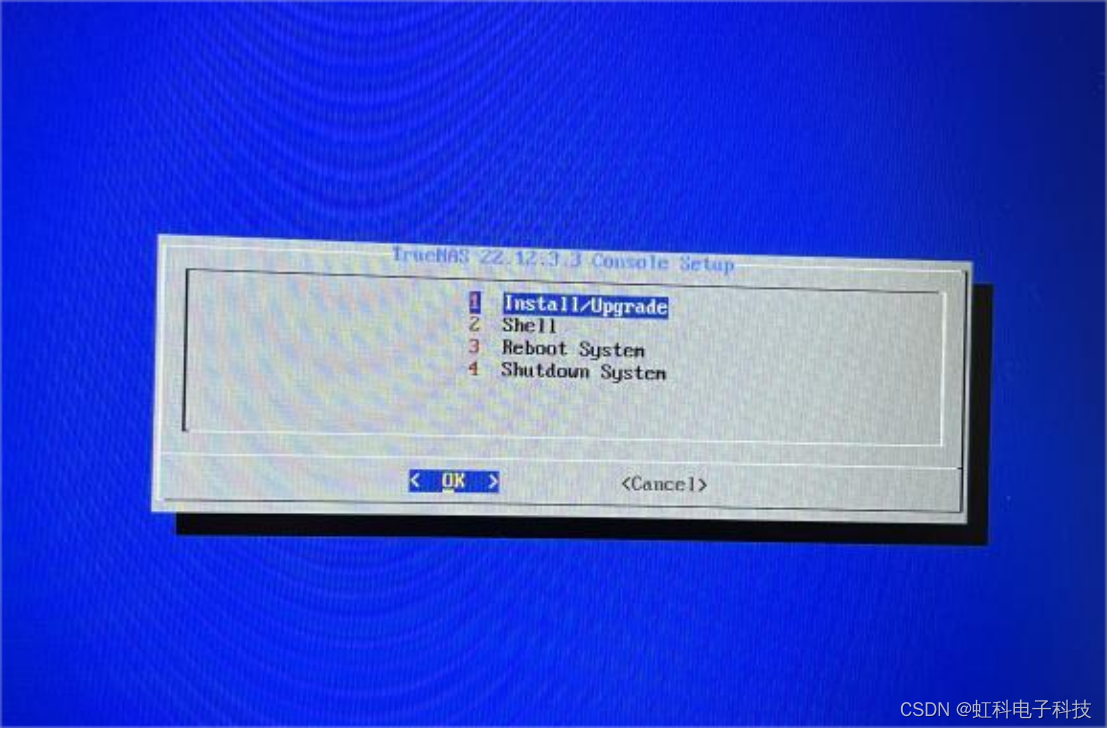
(6)选择第一个安装系统。出现如下界面。
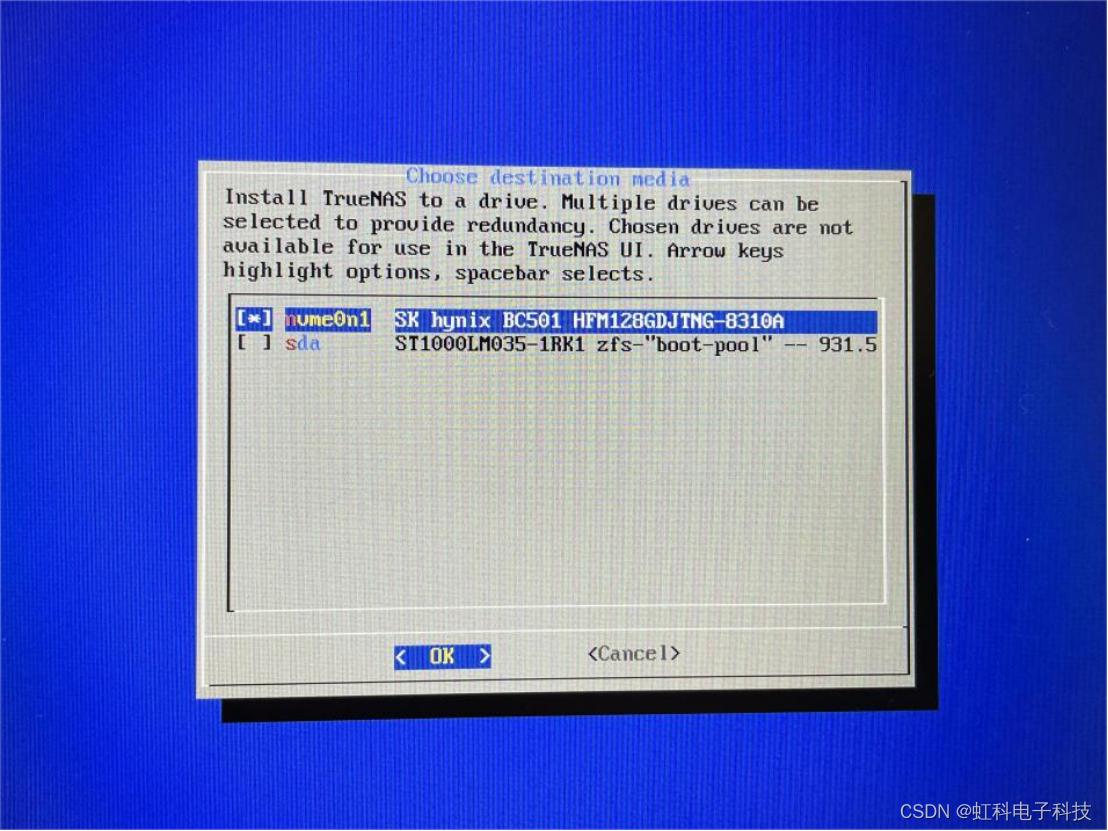
(7)选择把系统安装在固态硬盘上。
注意:此处工程师修改了一个选项之后才显示2块硬盘,第一次安装时它只显示1块硬盘,只显示了工程师的机械硬盘而没有固态硬盘,安装好后工程师发现没有另一块硬盘做不了存储池,所以最少需要2块硬盘,而且它必须要能识别到,该问题解决方案请在文末查看。
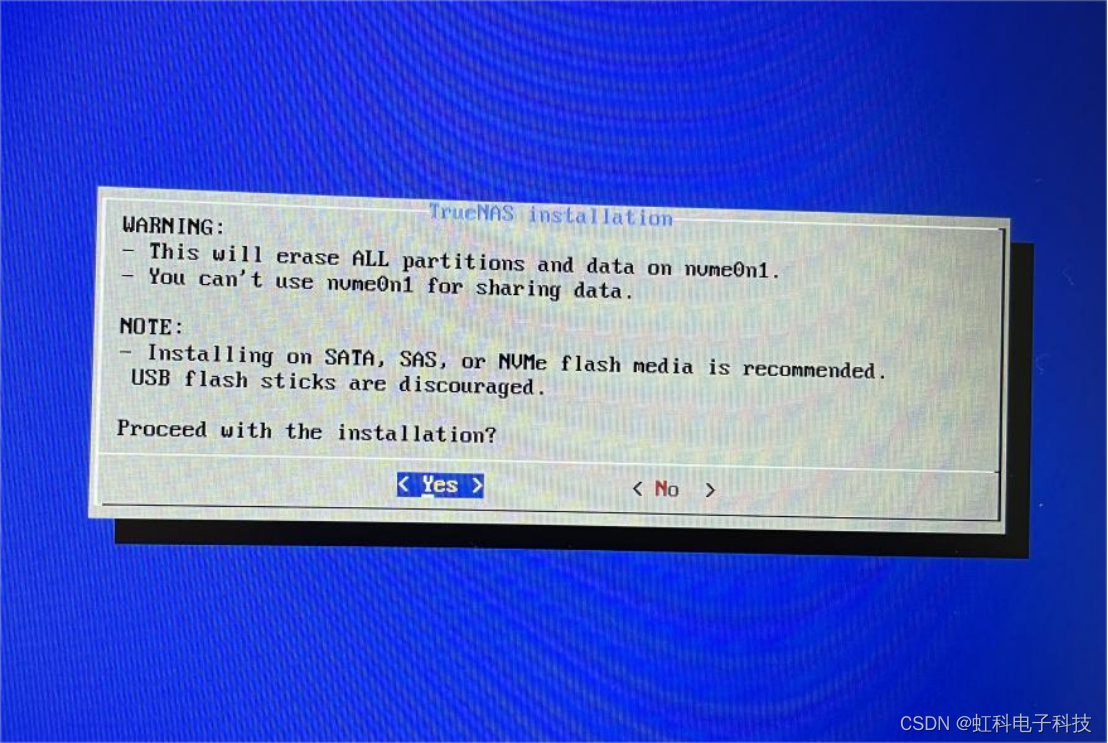
(8)选择yes。
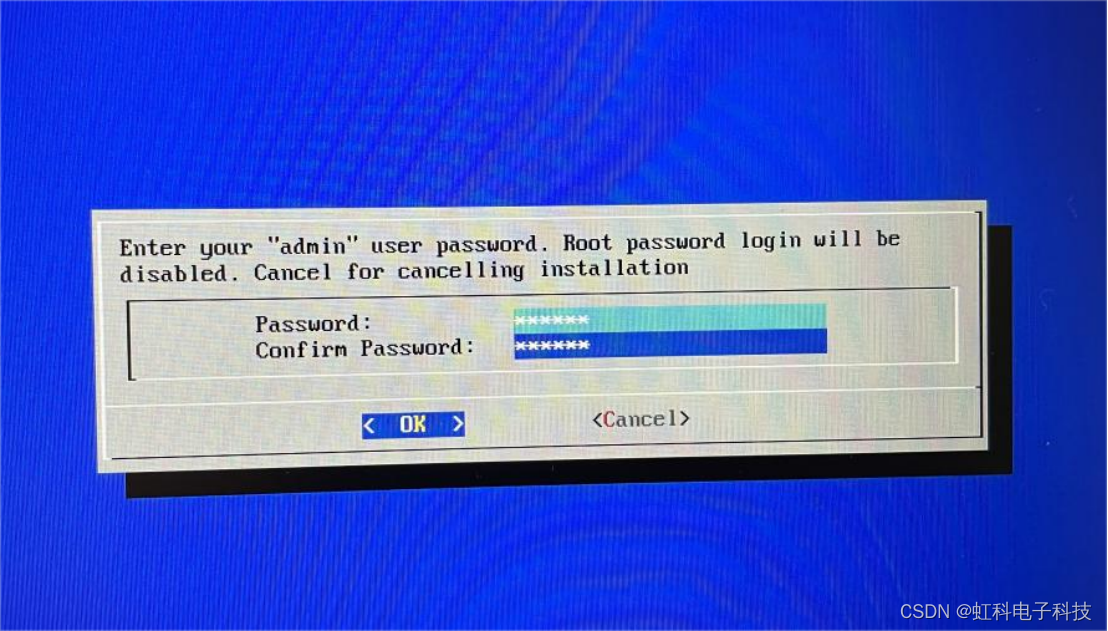
(9)输入amdin密码,这是我们登录管理页面的密码。
(10)选择启动方式:点击yes,使用EFI启动。

(11)随后开始安装系统,待安装完成后弹出的界面中点击“OK”。
(12)上一步完成后会回到主页,选择重启系统“Reboot System”,并拔出U盘,此时它会从你的硬盘进行启动。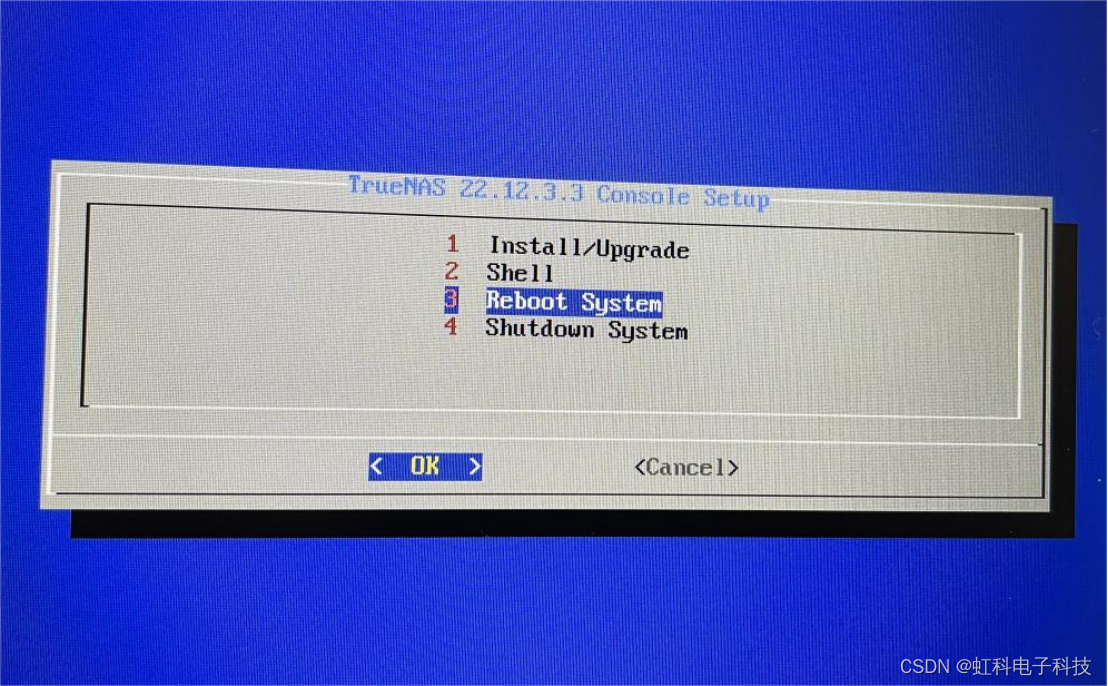
(13)随后会启动TrueNAS系统,第一次加载需要一些时间,出现如下界面表明系统已经安装完成。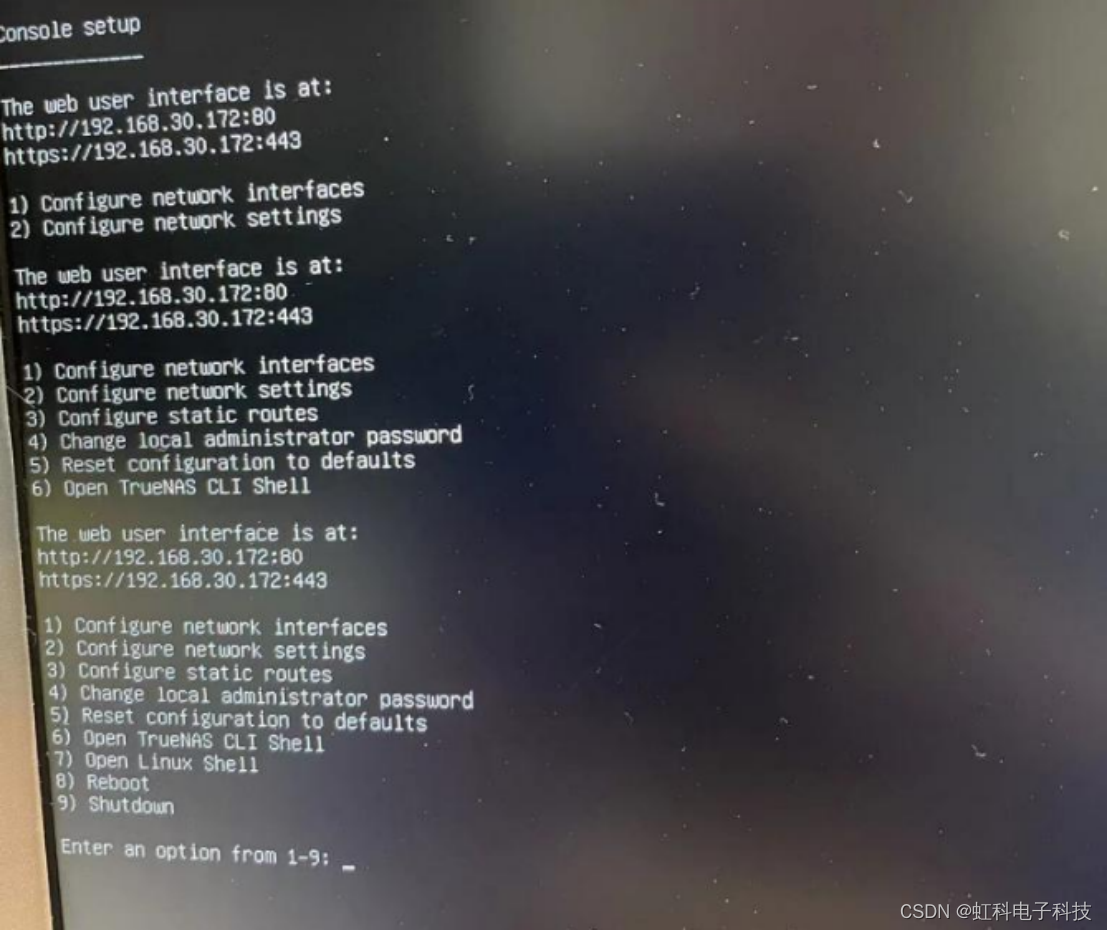
3、使用新电脑访问 TrueNAS 系统
(1)用您的另一台电脑访问旧电脑屏幕上的IP地址(“The web user interface is at:”下方的网址)即可进入管理页面
(2)输入admin和您设置的账号密码就可以进入系统管理界面了。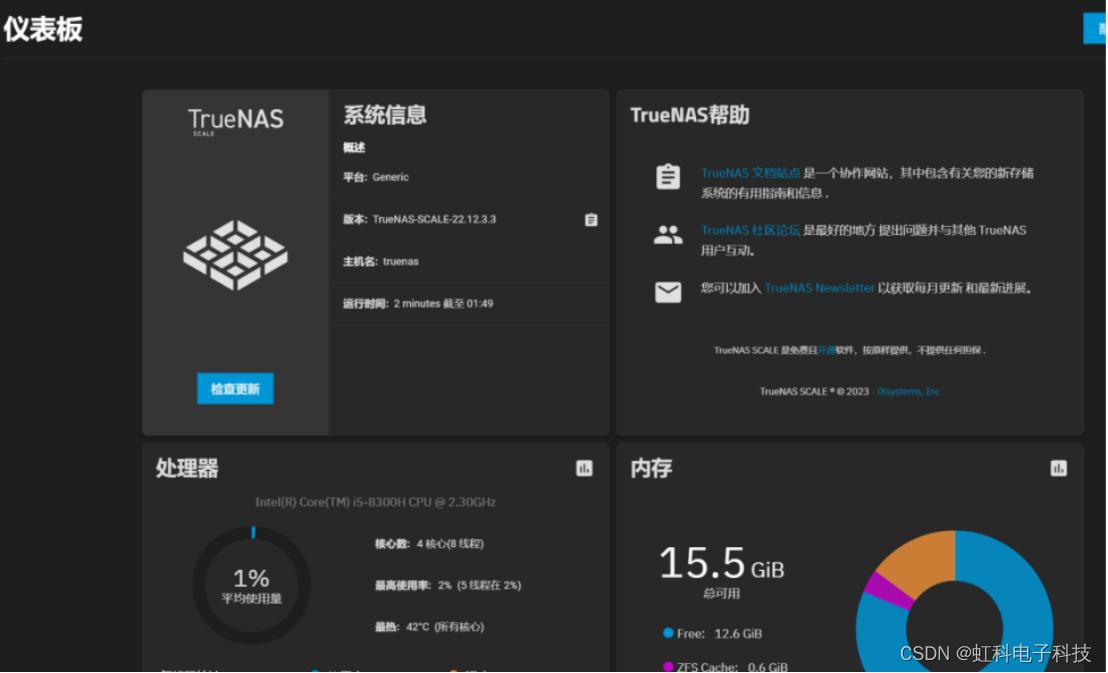
恭喜您!
操作到这一步
您就已经拥有一个自己的NAS存储系统了!
三、避坑指南
1.固态硬盘识别问题
参考文章:
https://ask.zol.com.cn/x/17810095.html
将SATA Operation选择为AHCI模式,它就能识别到固态硬盘了,默认是RAID ON模式。
2.安装过程错误
显示如下错误:
error: …/…/grub-core/kern/efi/sb.c:183:bad shim signature.
error:…/…/grub-core / loader / i386 / efi / linux.c : 168 : youneed to load the kernel first.
解决方案:进入BIOS,关闭安全启动
3.无法识别U盘问题
如果为U盘故障问题——将U盘格式化为正常U盘后重新制作启动盘
非U盘故障问题——考虑BIOS设置问题,在BIOS设置中开启Legacy Boot选项
安装完成之后
就可以开始愉快地进行数据共享啦!
关于初始化和设置数据共享
敬请期待下期文章!
关于虹科网络基础
虹科网络基础事业部是领先的网络基础设施解决方案供应商。我们与全球领先的企业网络和存储技术专家展开合作,提供一系列创新型、安全灵活、性能优越的产品和服务来满足市场快速发展的IT需求。虹科网络基础团队不断学习最新的技术和应用、接受专家培训。期待为您提供专业的网络和存储解决方案,构建IT服务基础架构,帮助您更好地存储、管理、分析和交付数据。
文章来源:虹科网络基础设施
阅读原文:https://mp.weixin.qq.com/s/MNvkCE5YuUoQOFedO91mYA