福州网站建设外贸网站不备案行吗
【雪球导读】
「OpenAI推出ChatGPT桌面端」
OpenAI重磅推出ChatGPT桌面端,全面支持Windows和macOS系统!这款新工具为用户在日常生活和工作中提供了前所未有的无缝交互体验。对于那些依赖桌面端进行开发工作的专业人士来说,这一更新带来了令人兴奋的应用协作功能.
SnowEngine
1.OpenAI正式发布了ChatGPT桌面端

厌倦了在ChatGPT网页端复制粘贴消息和代码?那种因为没有桌面端而不得不频繁切换窗口的日子终于要结束了!
OpenAI正式发布了适用于Windows和macOS的ChatGPT桌面端。这款桌面端软件针对用户在不同场景下的需求进行了深度集成,让操作变得更加直观和便捷。
打个比方,你现在可以直接截取屏幕上的任何内容,然后与ChatGPT进行即时交互,无需繁琐的复制粘贴。
或者,你只需轻轻一按快捷键,就能在任何界面中召唤出ChatGPT,实现无缝对接。
此外,还有跨应用联动等功能,这些都是针对用户实际需求痛点的解决方案。
让我们来探索这款桌面端软件,看看它究竟有多惊艳!
2.ChatGPT桌面端操作亮点
想要快速启动ChatGPT?只需按下快捷键,无论是macOS的Option+Space还是Windows的Alt+Space,桌面端的任意窗口都能瞬间召唤出ChatGPT。
想要让ChatGPT帮你分析当前页面?直接截屏发送,它会立刻为你解读页面内容。
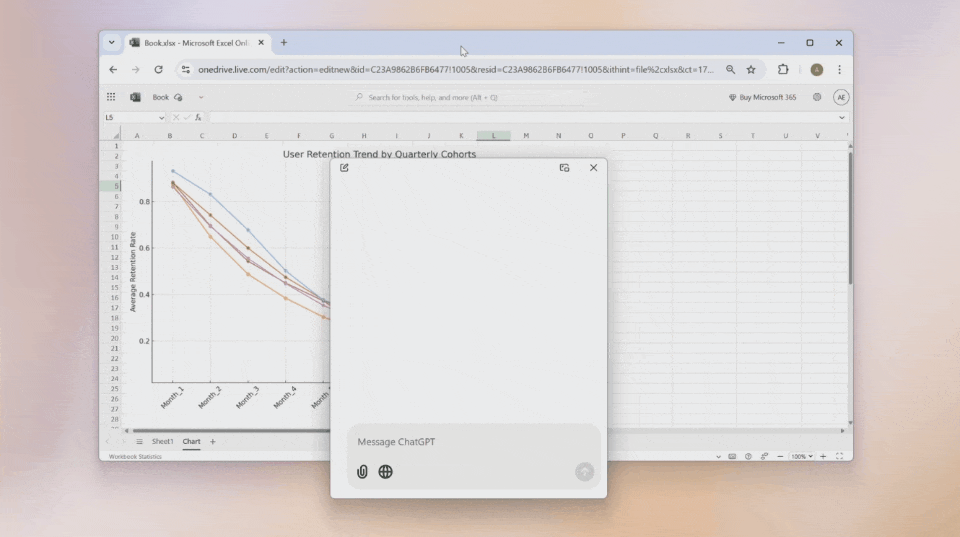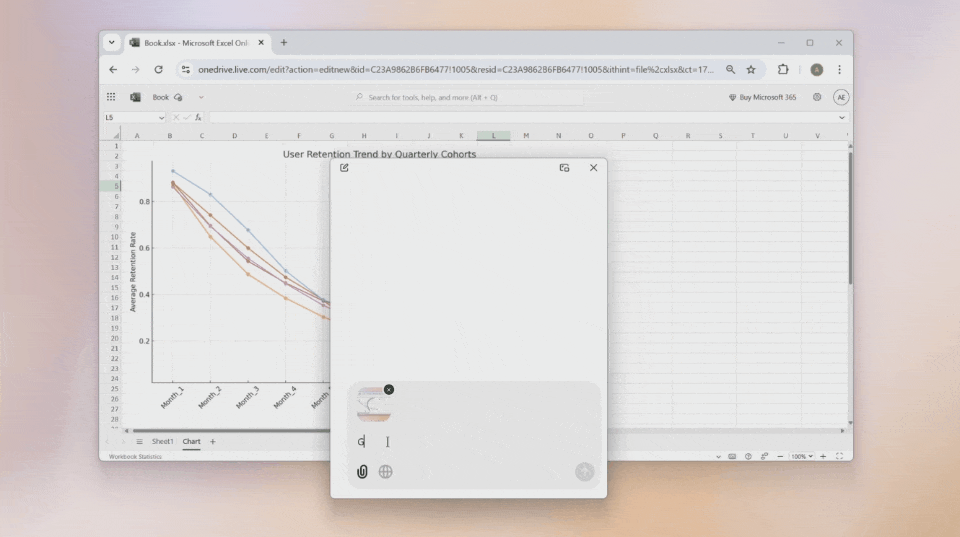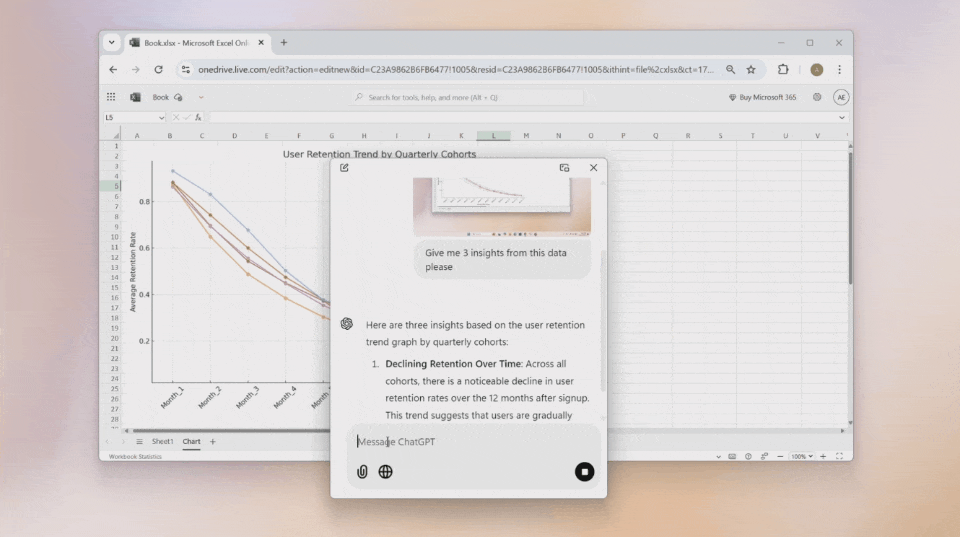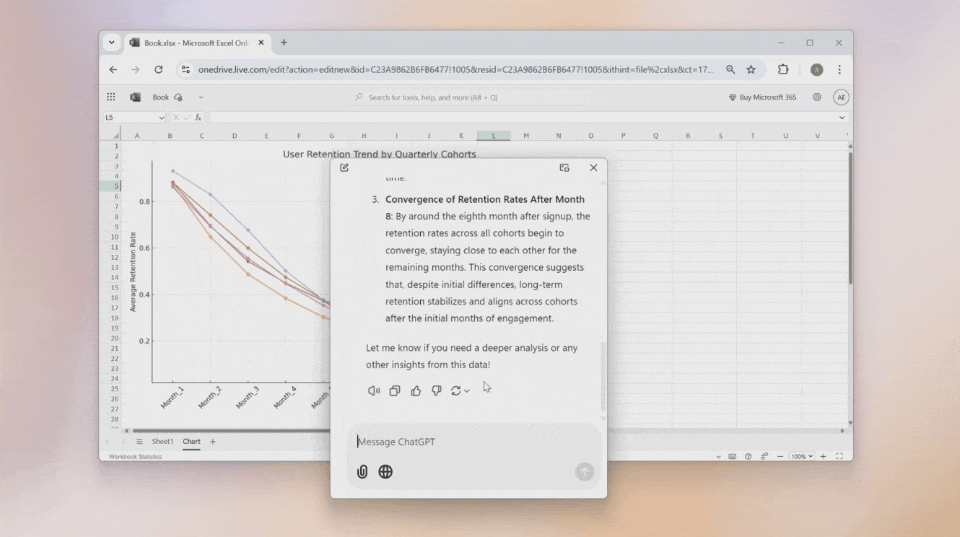
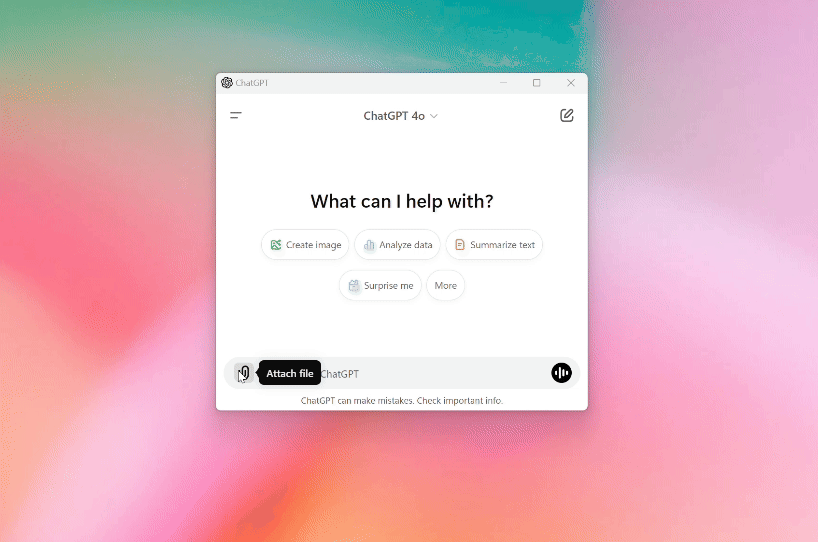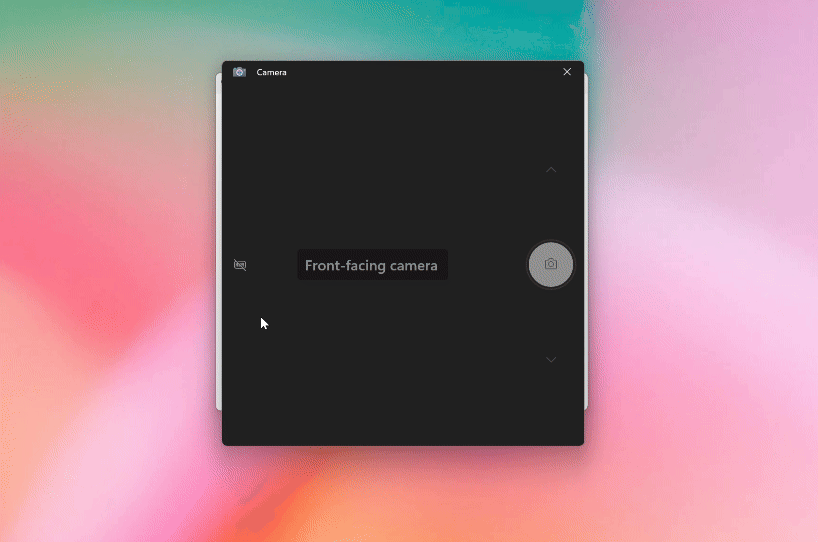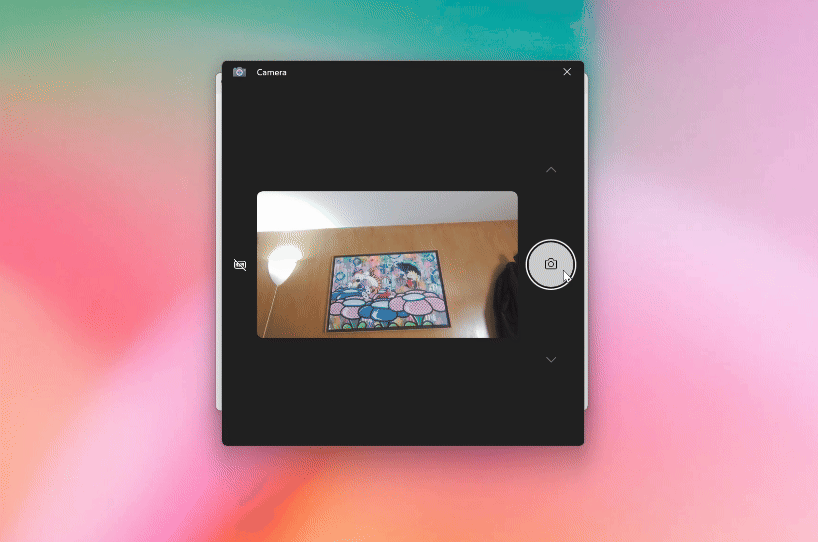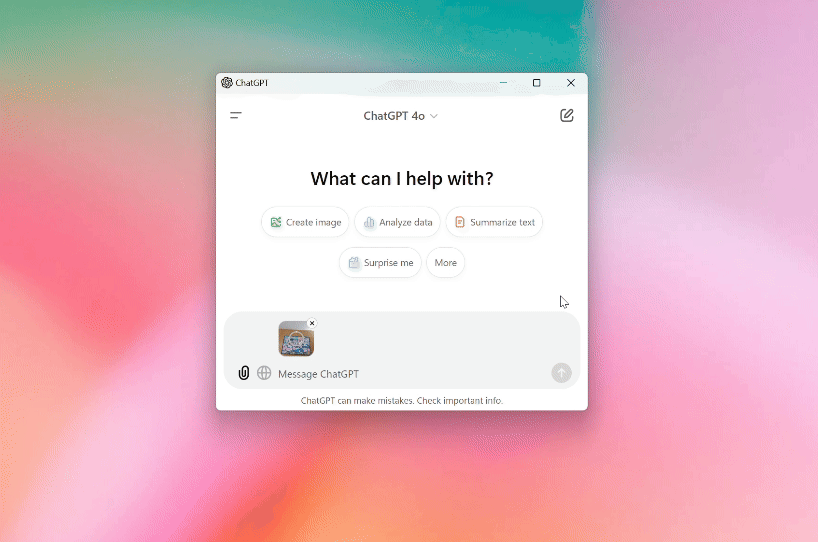
桌面端还能直接调用摄像头拍照,然后发送给ChatGPT提问,让你的问题得到即时解答。
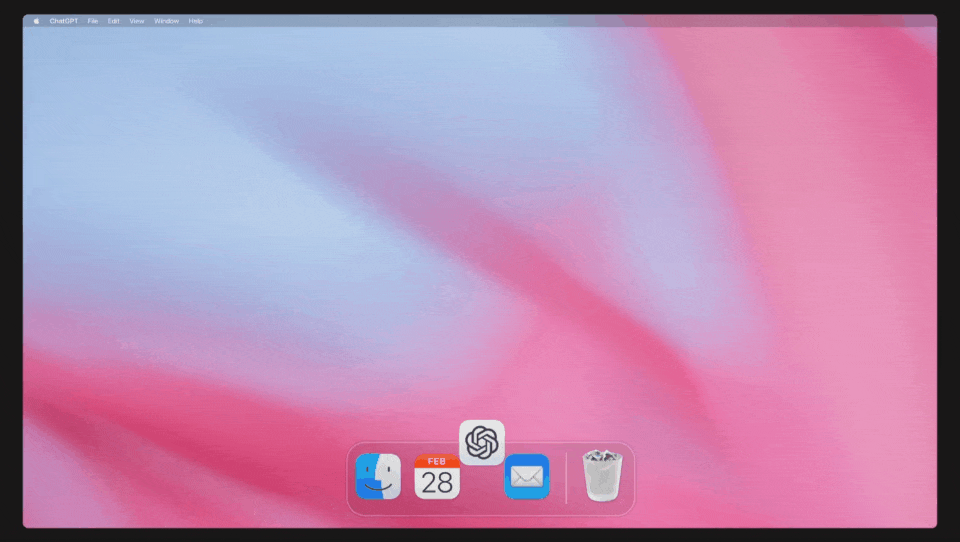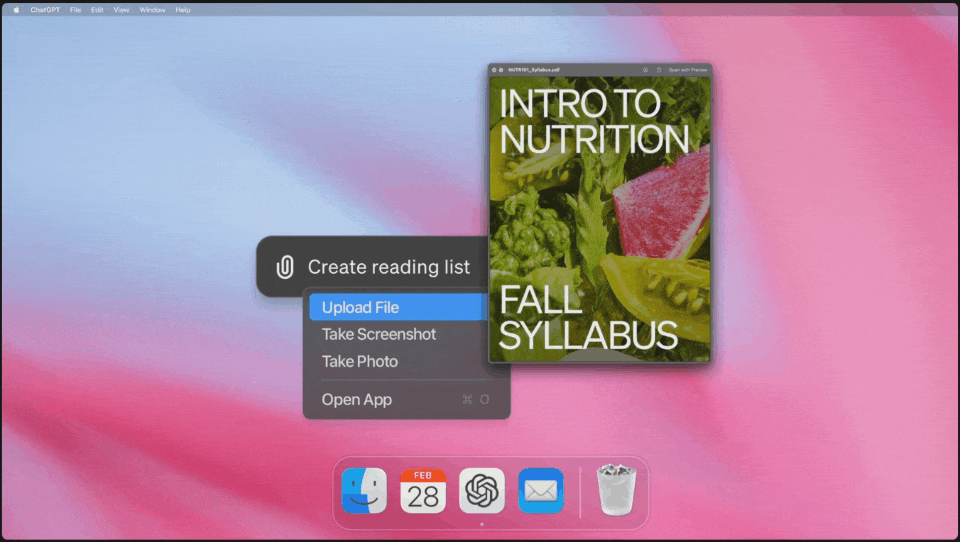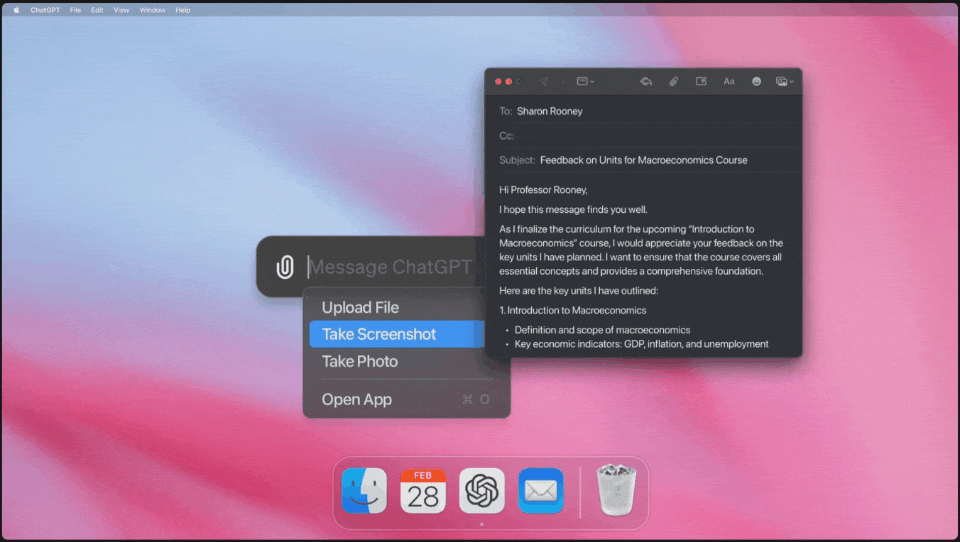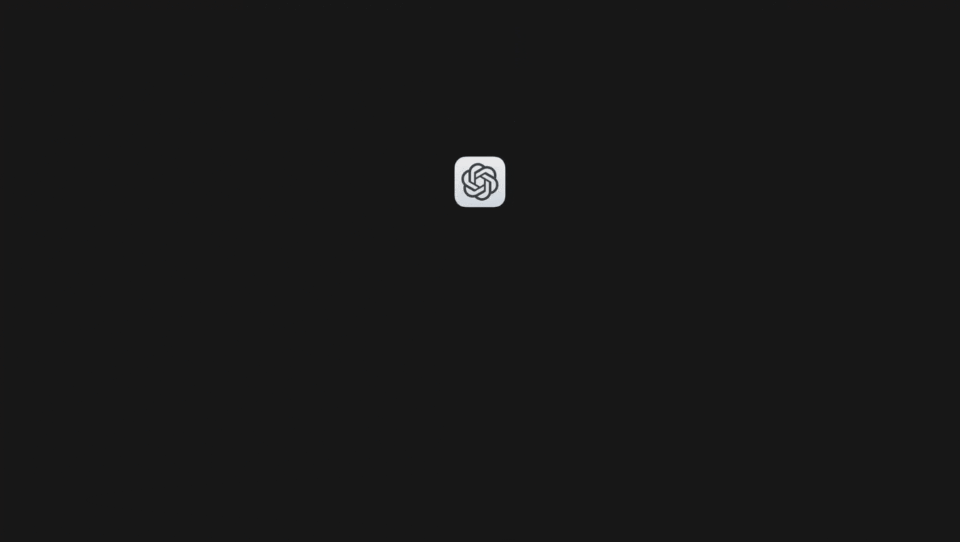
上传文件,让ChatGPT帮你总结内容,比如快速梳理出所有课程任务的截止日期,这比手动整理高效多了。

网络搜索功能?那是基本操作,ChatGPT桌面端轻松应对。
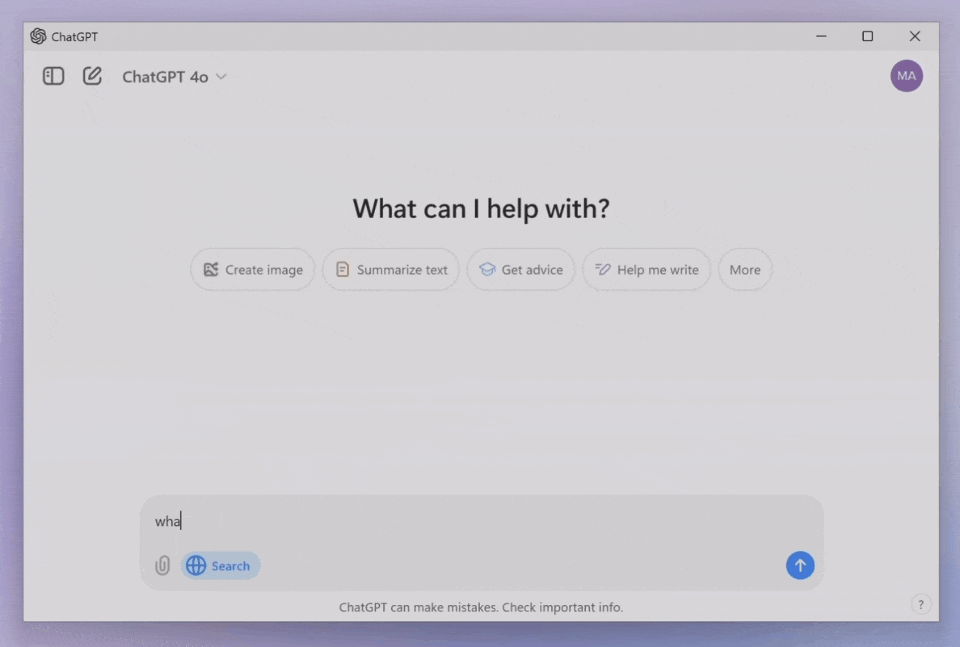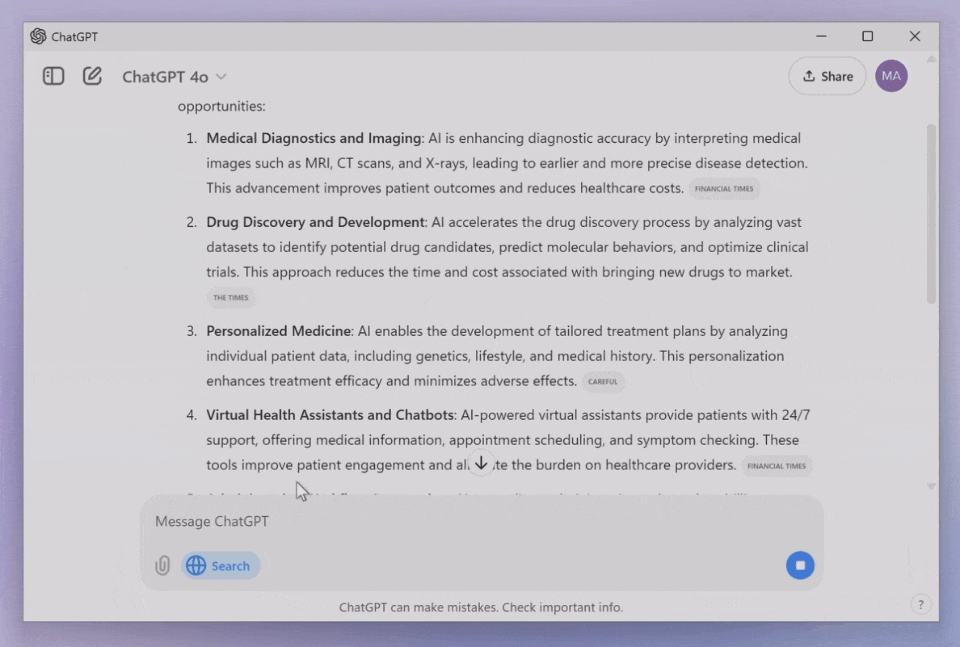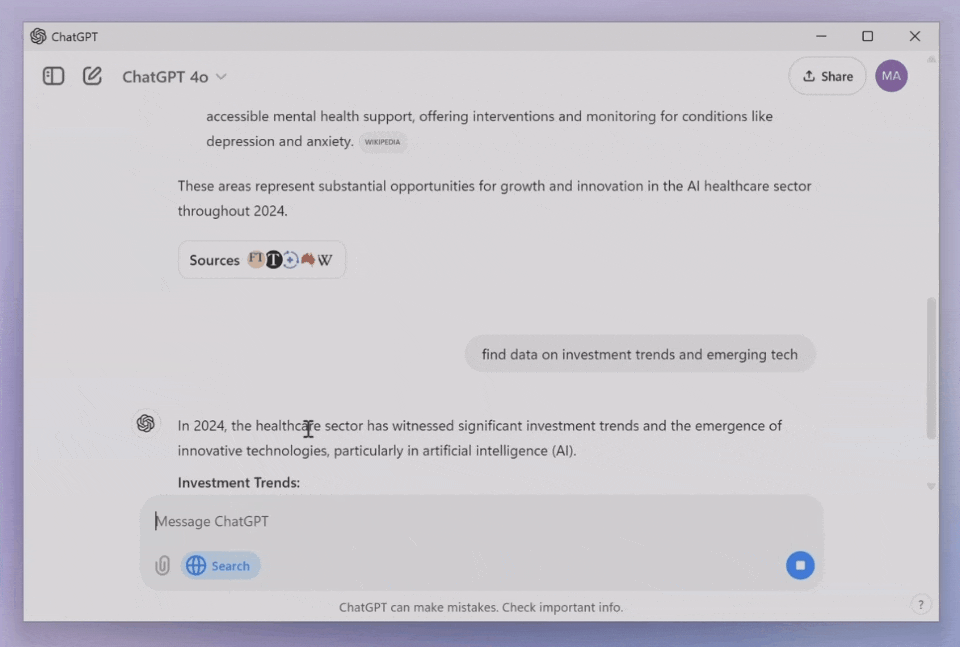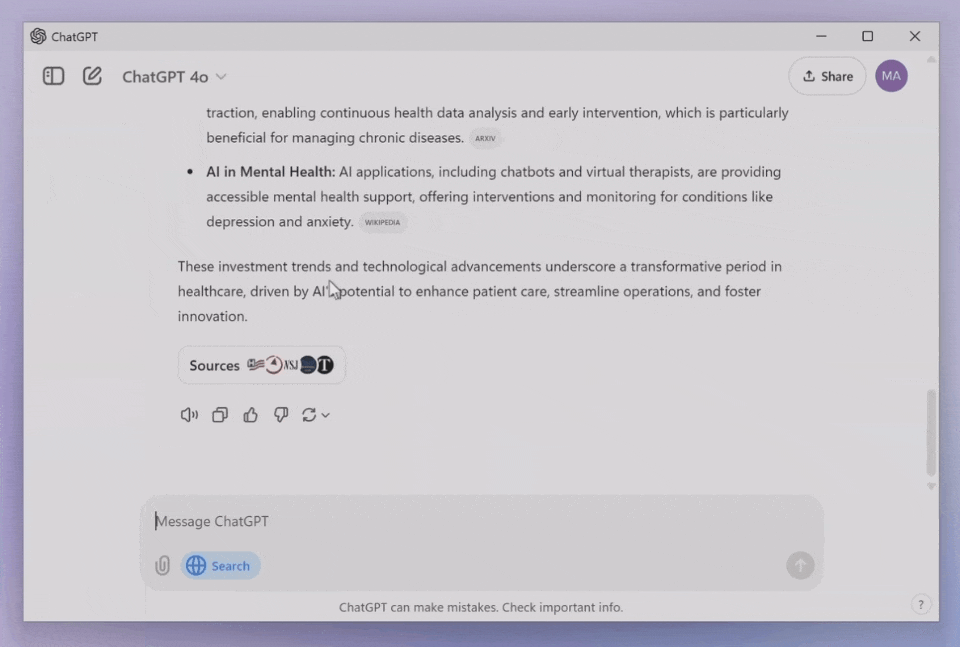
对于那些需要大量阅读和研究的用户,现在可以直接选中文本段落,然后用快捷键触发ChatGPT,它会立即提供内容介绍和具体解释。
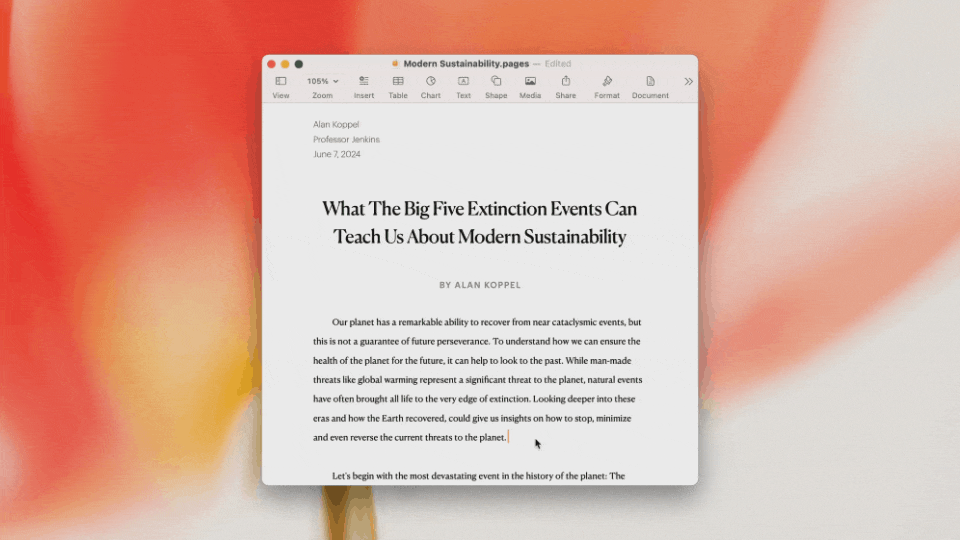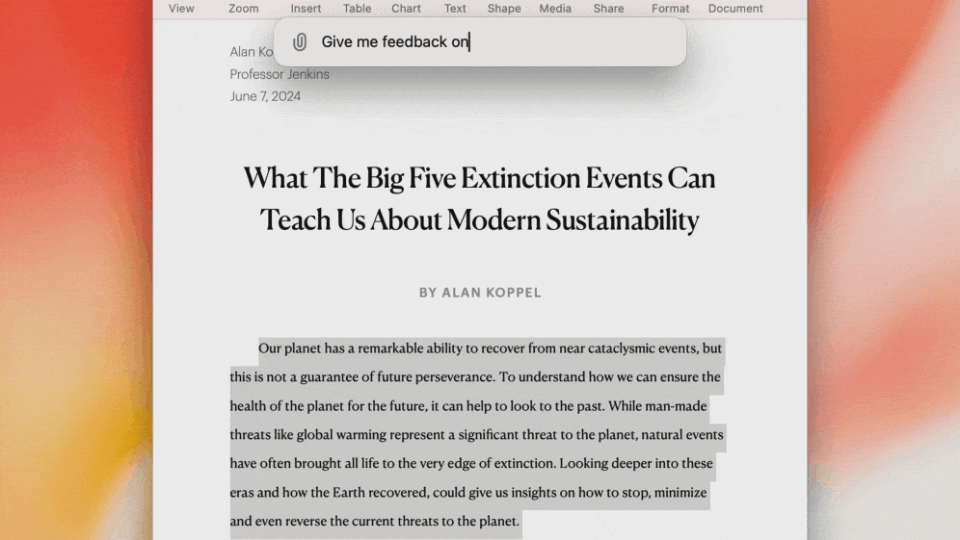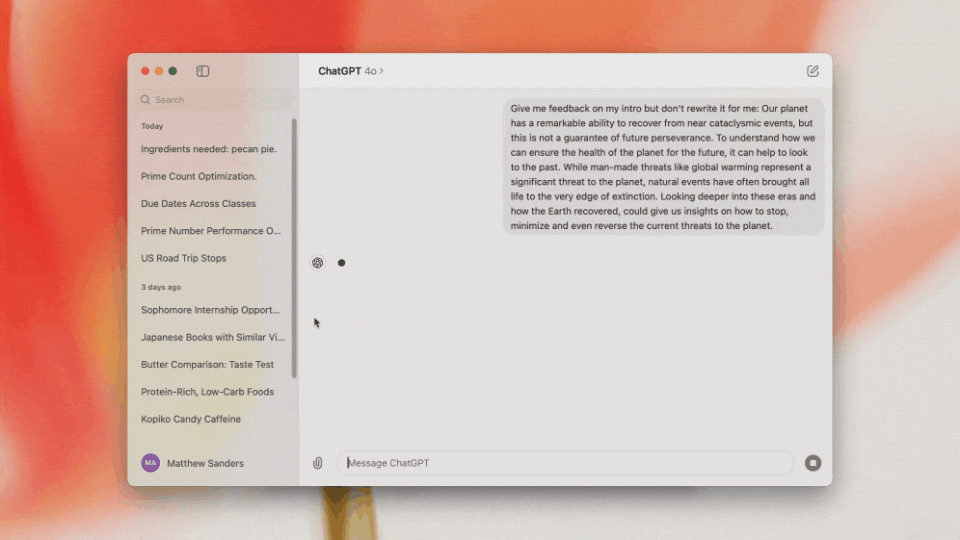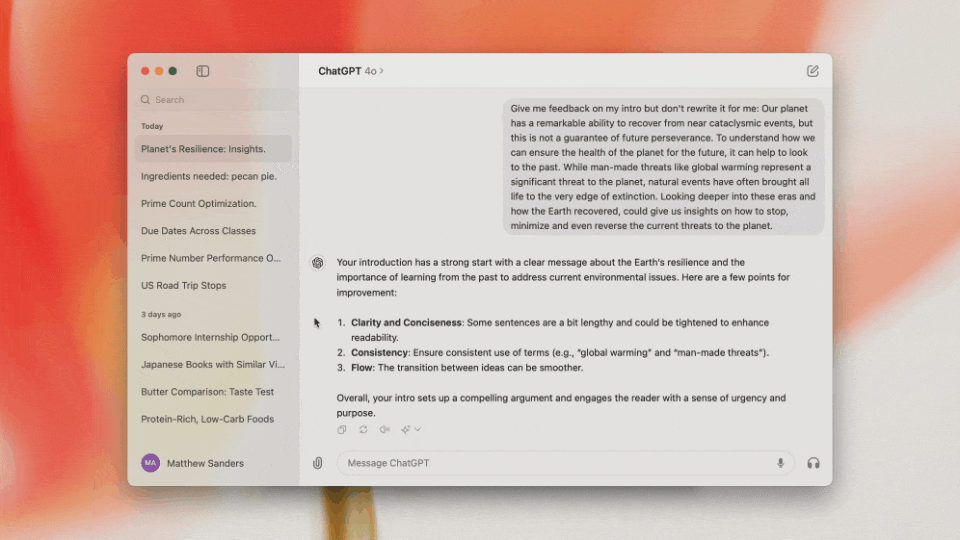
代码解释和跨应用联动?ChatGPT桌面端测试版本的表现让人印象深刻。目前ChatGPT Plus和Team用户可以使用,而ChatGPT Enterprise和Edu用户很快也将获得权限。
它支持Xcode、VSCode、TextEdit等IDE和各种编辑器,也能与终端等应用程序联动。
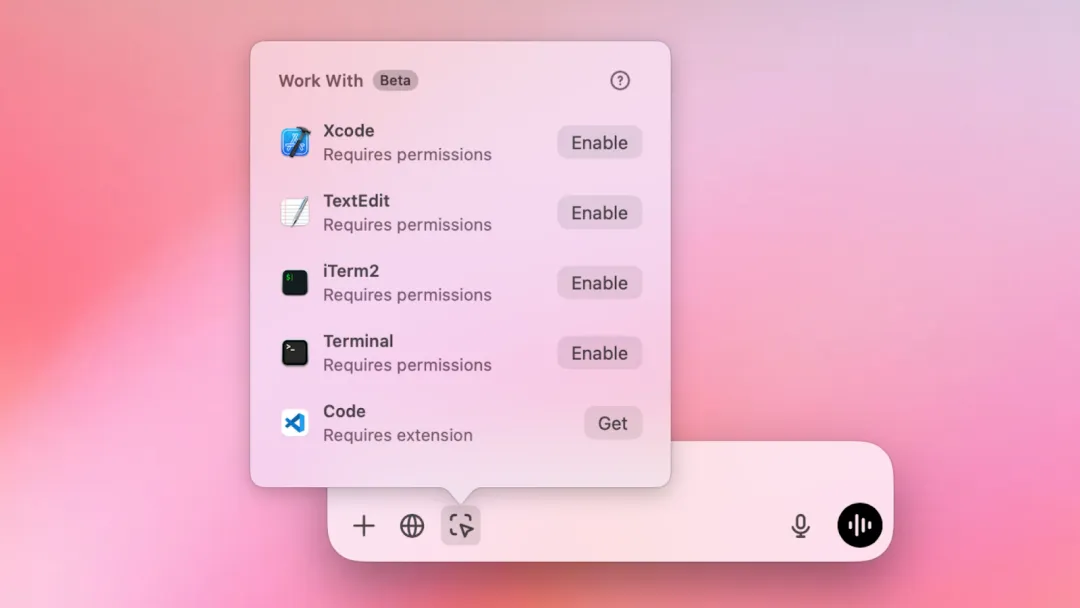
在Xcode中,你可以直接调用ChatGPT来获取代码解释、解决报错的步骤,大幅提升开发效率。
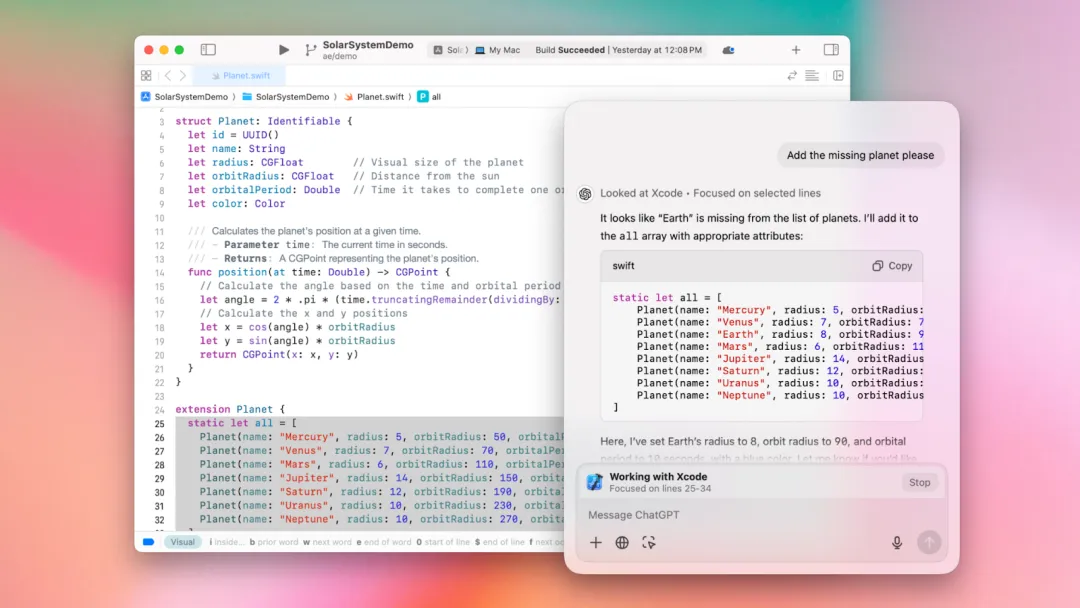
桌面端还支持高级语音模式,让你可以实时与ChatGPT聊天,更有效地提出问题和获取答案,提高工作效率。
与网页版相比,桌面端的一大优势是能够直接搜索聊天记录,并快速切换到对应的上下文中,回顾或继续对话,这比在网页上翻找要方便得多。
3.让编程更轻松:AI集成工具的崛起
在ChatGPT桌面版问世前,用户得费劲地从网站复制内容到工作应用。现在,OpenAI等公司正通过将工作流程与界面紧密结合来吸引用户。GitHub、Anthropic、亚马逊等也在推出新集成功能。
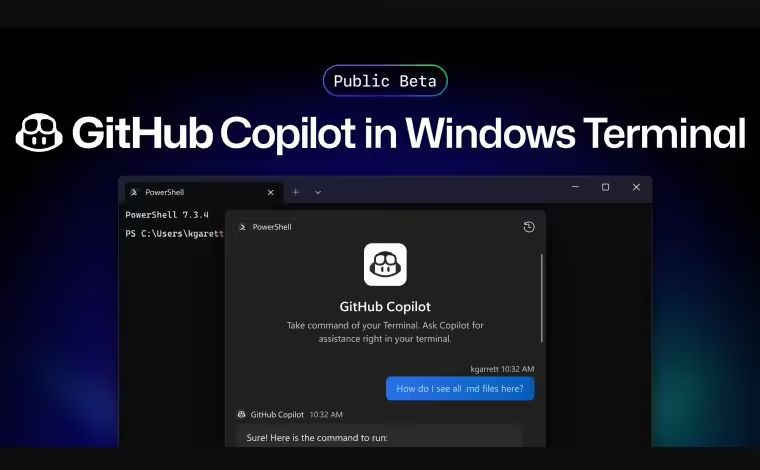
GitHub通过与VS Code和Xcode集成,提供IDE内的代码建议和自动补全,显著提升编程效率。Anthropic的Claude虽未集成第三方应用,但其“Artifacts”功能让用户无需离开应用即可查看生成的网页。

OpenAI的Canvas功能类似Anthropic的“Artifacts”,但ChatGPT能将生成内容直接集成到开发环境,让工作流程更流畅。亚马逊云科技(AWS)将Q Developer AI助手集成到Visual Studio Code和JetBrains等IDE中,提供内嵌的建议和代码补全插件,用户可直接在IDE中操作。
软件应用集成已不新鲜,Slack与多家公司合作多年,用户可直接在聊天窗口调用应用。如今,AI工具与开发环境的结合成为竞争焦点,OpenAI也在积极布局。
4.Azure OpenAI现可部署o1模型
Azure OpenAI 里面已上架o1-preview和o1-mini,现在可在Playground 预览和API部署调用。
模型适用于美国东部2 和瑞典中部的标准和全域标准部署,以供已申请的客户使用。

o1 系列高级推理模型在以下复杂而微妙的问题领域表现出色:
复杂代码生成:能够执行算法生成和高级编码任务,以帮助开发人员。
高级问题解决方案:非常适合全面的头脑风暴会议和解决多方面的问题。
复杂文档比较:非常适合分析合同、案件档案或法律文件以辨别细微的差别。
指令遵循和工作流管理:特别擅长处理需要较短上下文的工作流。