Spark整合hive的时候
连接Hdfs不从我hive所在的机器上找,而是去连接我的集群里的另外两台机器
但是我的集群没有开
所以下面就一直在retry

猜测:
出现这个错误的原因可能与core-site.xml和hdfs-site.xml有关,因为这里面配置了集群的namenode信息
解决方案:
我新建了一个项目,里面没有core-site.xml和hdfs-site.xml
只放进去一个hive-site.xml

错误原因:
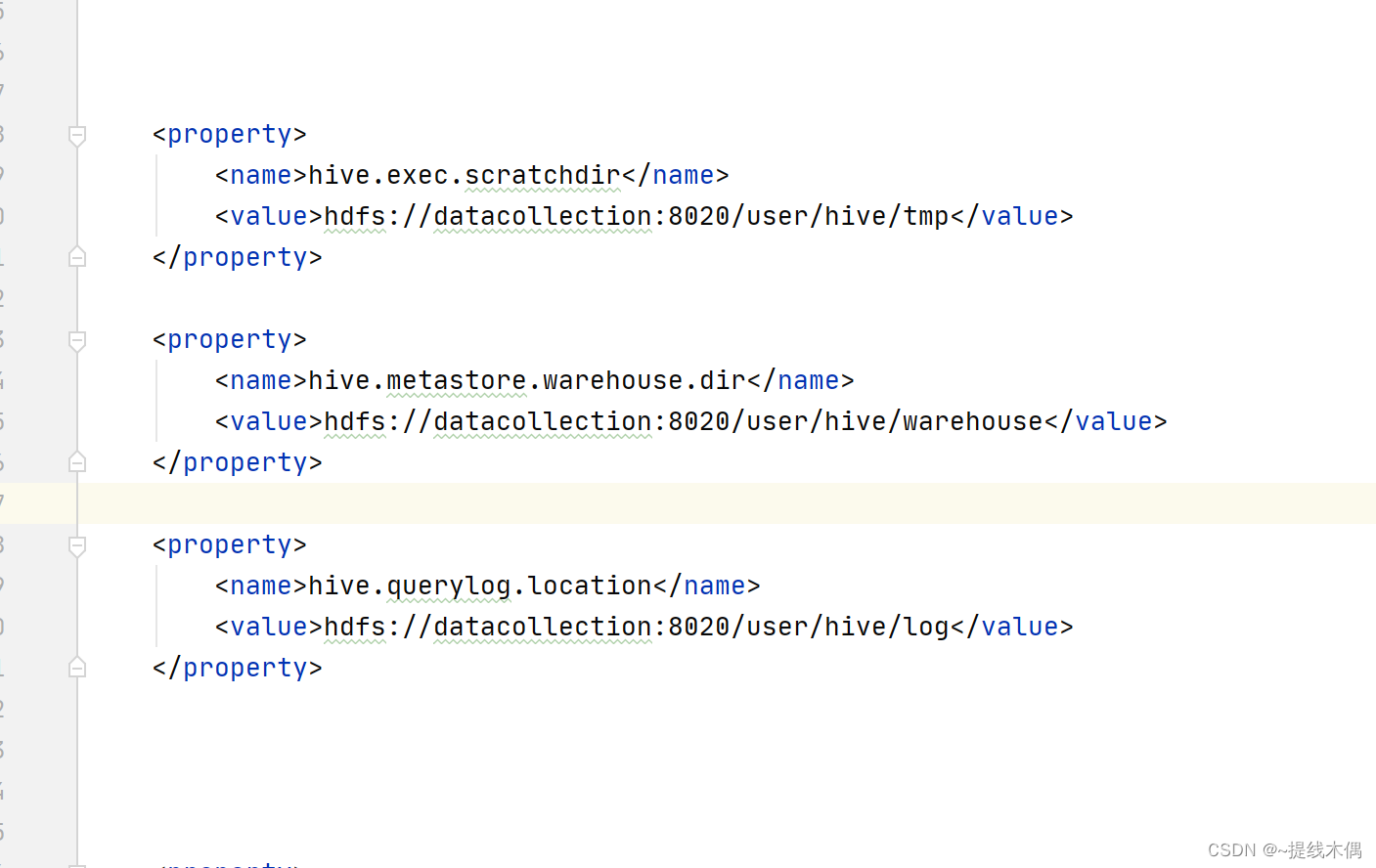
我的hive-site.xml中没有图片中的三个配置,加上这三个配置就好了