python做网站的书wordpress音乐主题公园
前言:
本专栏参考教材为《SPSS22.0从入门到精通》,由于软件版本原因,部分内容有所改变,为适应软件版本的变化,特此创作此专栏便于大家学习。本专栏使用软件为:SPSS25.0
本专栏所有的数据文件请点击此链接下载:SPSS数据分析专栏附件!
1.曲线回归
曲线回归是一种回归分析方法,用于探索自变量和因变量之间的非线性关系。相比于线性回归,曲线回归可以更好地拟合曲线状或非线性的数据模式。
在曲线回归中,常见的方法包括多项式回归、指数回归、对数回归和幂函数回归等。这些方法通过引入非线性的函数形式,来拟合数据中的曲线状关系。
举例来说,多项式回归可以通过添加二次项、三次项等来拟合数据中的曲线形状。指数回归适用于自变量和因变量之间呈指数关系的情况。对数回归则适用于自变量和因变量之间呈对数关系的情况。幂函数回归用于自变量和因变量之间呈幂函数关系的情况。
曲线回归的步骤与线性回归类似,包括收集数据、可视化数据、选择适当的模型、拟合模型、评估模型和解释结果等。但需要注意的是,在选择曲线回归模型时,要根据实际情况选择适当的函数形式,并进行合理的判断和尝试。
注意,曲线回归也有适用范围和局限性。选择适当的曲线回归模型需要基于数据和领域知识,并需要注意过拟合(overfitting)和模型复杂性的问题。
2.SPSS实现
(1)打开“data09-02”数据文件,选择“分析”——“回归”——“曲线估算”,弹出下图所示的对话框。
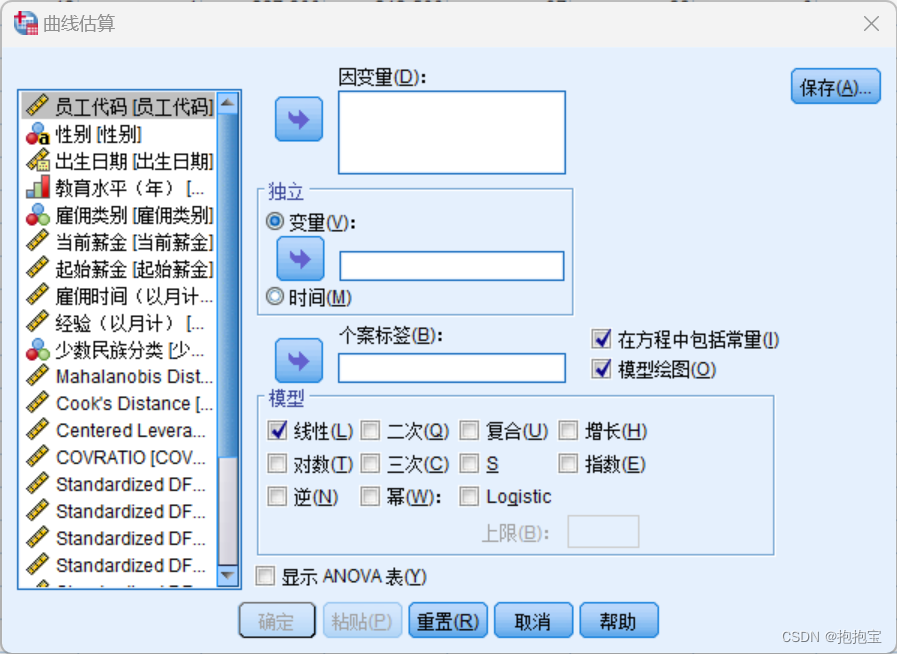
(2) 按照下图选择相应变量以及勾选对应选项。
注:模型可以根据需要选择,此处仅选择图中几种模型进行对比。
(3)完成设置后,单击确定。
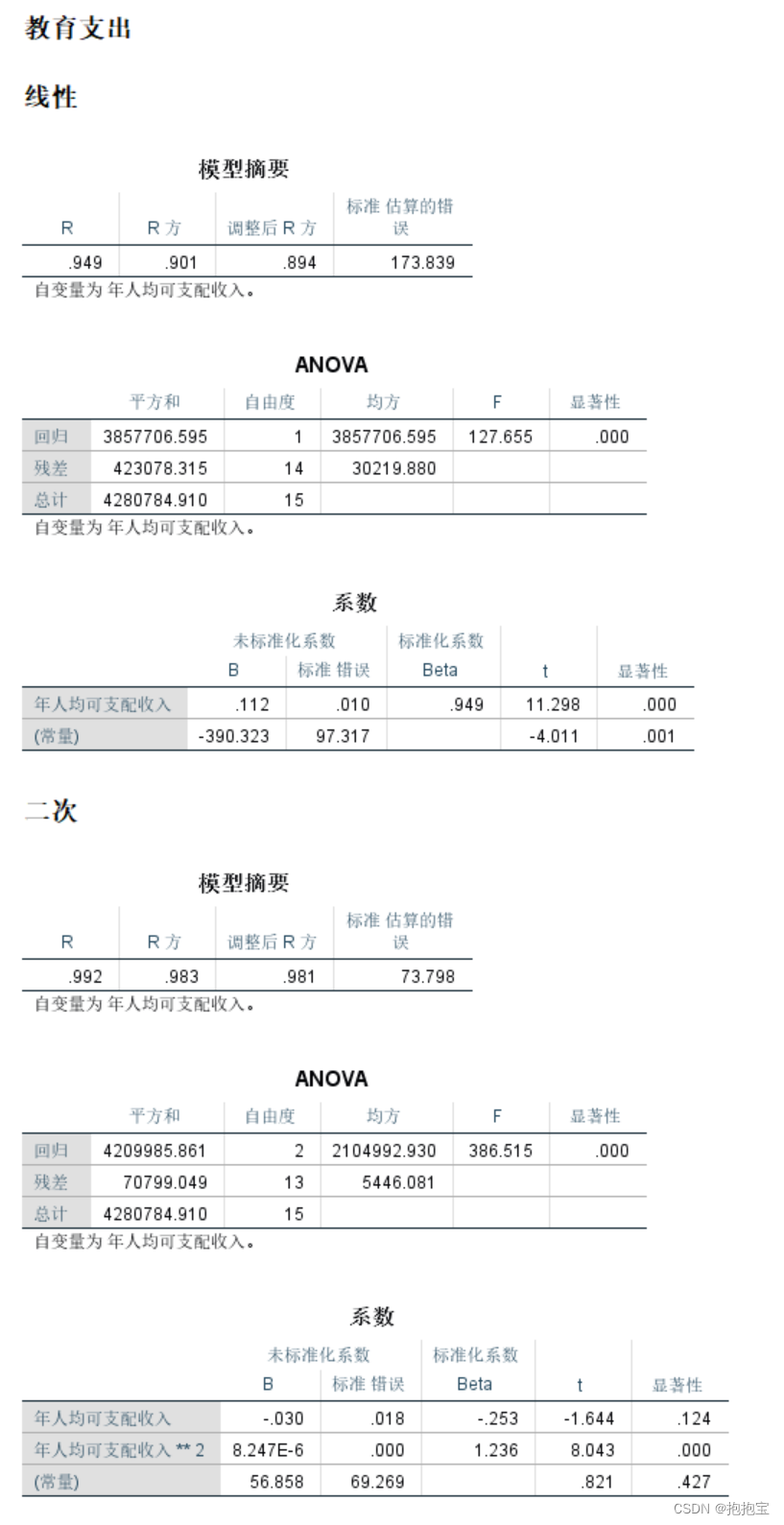
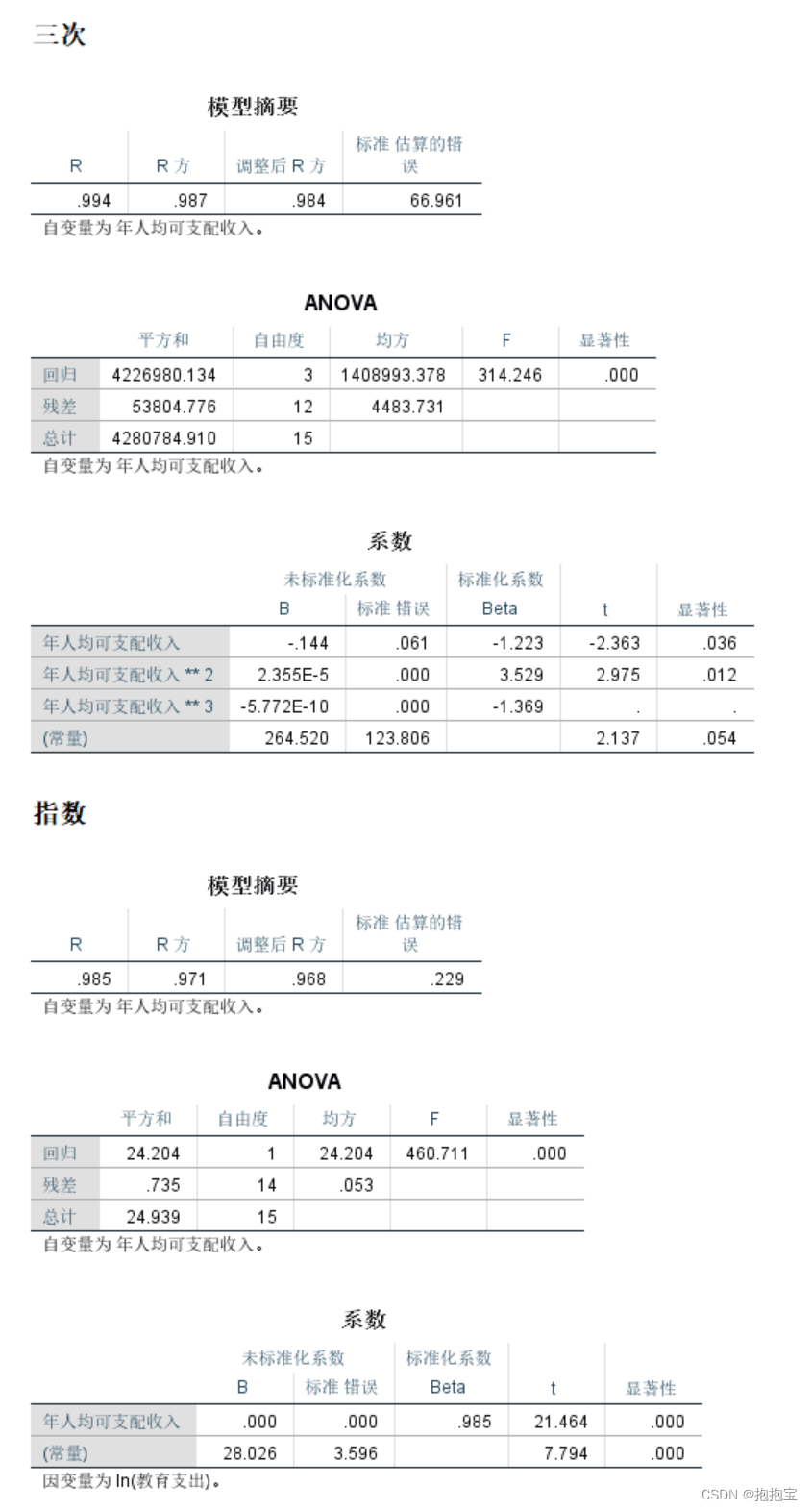
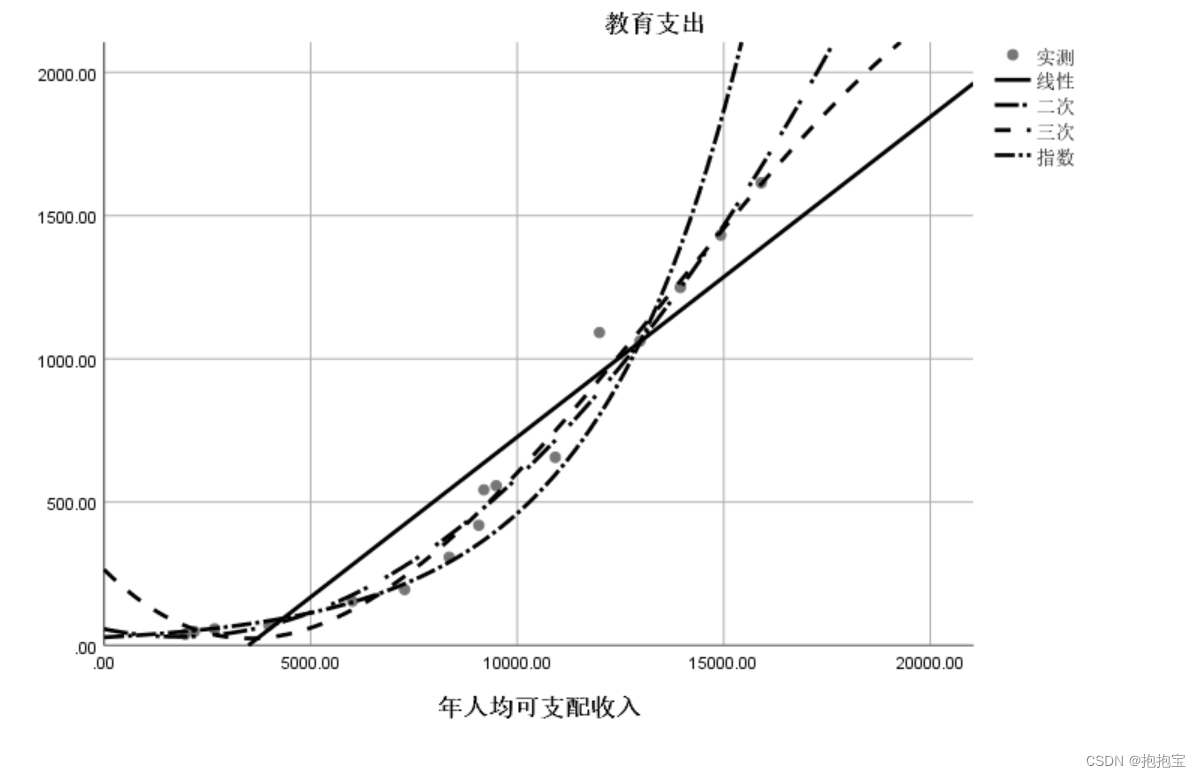
3.结果分析