怎样创建旅游网站蜘蛛不抓取网站的原因
在学习深度学习的时候,我们需要考虑如何去处理数据去训练我们的模型,pytorch为我们提供了Dataset和DataLoader两个类来对数据进行处理,前者作用是提供了一种方式来获取数据及其label,后者的作用是为网络提供不同的数据形式。本文主要讲第一个类——Dataaet.
一、Dataset的作用

如图,我们举个例子,我们这里有很多和数据(左边每一个图形代表一个数据),其中我们需要获取圆形的数据,通过Dataset,我们可以将所有的圆拿出来,放到我们的数据集当中,并且每一个数据都有自己的label,比如说红色、绿色。并且数据集会将每一个数据进行编号,所以我们可以归纳出Dataset的作用:
1.获取每一个数据以及其label
2.告诉我们在数据集中有多少个数据
二、Dataset的使用
1.数据集下载
在使用Dataset之前,建议大家先去下载一个数据集,下面提供一个国内的数据集下载地址:
数据集下载![]() https://aistudio.baidu.com/datasetoverview/2/1
https://aistudio.baidu.com/datasetoverview/2/1
下载解压后放在项目文件夹下就行。
2.类的定义
我们创建一个新文件,起名为demo1.py
导入工具:
from torch.utils.data import Dataset
from PIL import Image
import os我们通过查看文档可知,所有的数据集都应该继承Dataset类,并且子类都必须重写__getitem__方法,该方法的主要作用是获取每一个数据以及其label,也可以选择性重写__len__方法,获取数据集的大小。
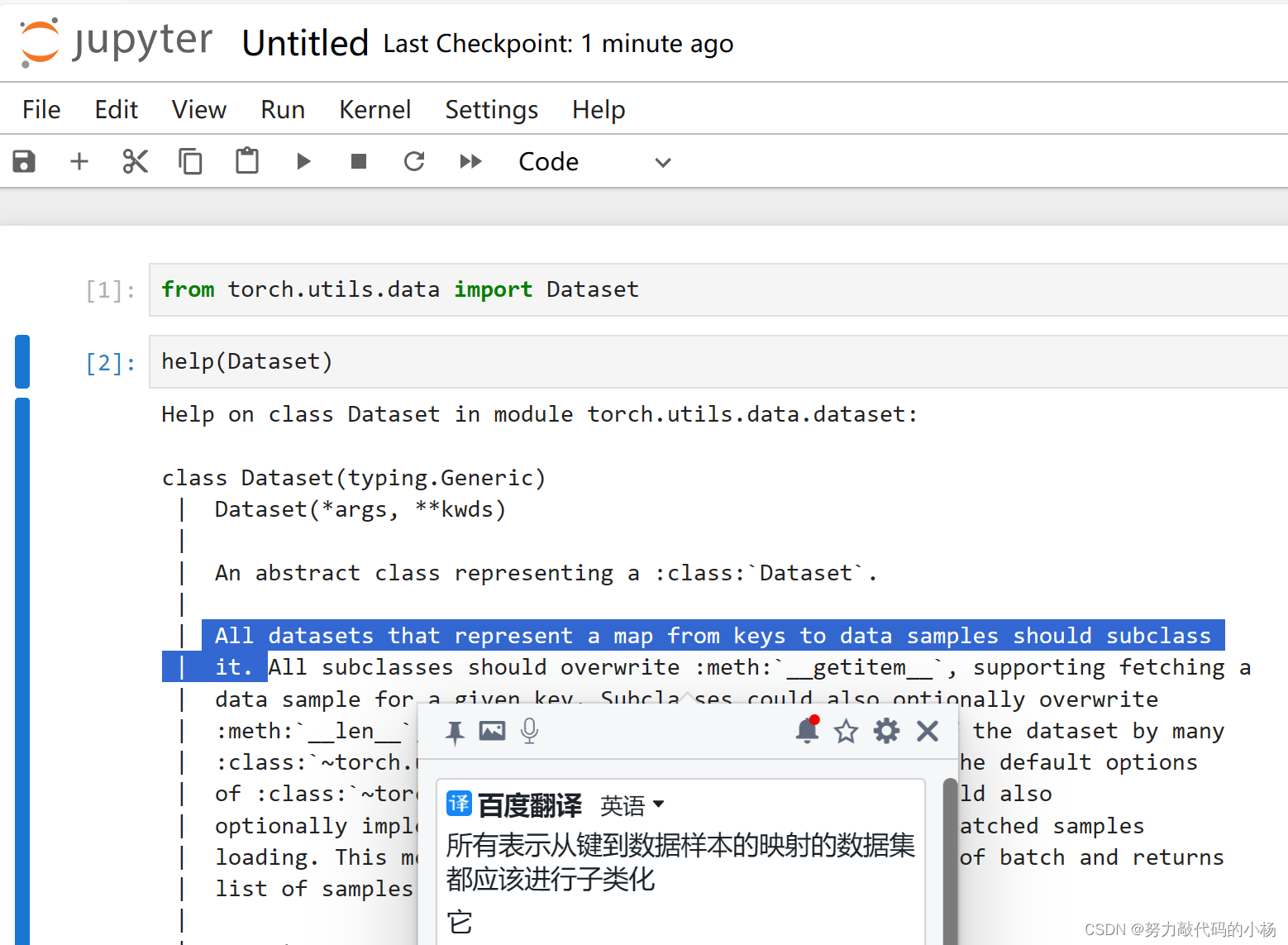
所以我们定义一个类MyData
MyData(Dataset):
#构造方法,将文件夹名称以及子文件夹传入def __init__(self,root_dir,label_dir):self.root_dir = root_dirself.label_dir=label_dirself.path=os.path.join(self.root_dir+self.label_dir)self.Img_path=os.listdir(self.path)#获取数据集中第idx个数据以及其label,我们可以通过索引获取数据对象def __getitem__(self, inx):Img_name = self.Img_path[inx]Img_item_path = os.path.join(self.root_dir,self.label_dir,Img_name)img = Image.open(Img_item_path)label = self.label_dirreturn img,label#获取数据集的长度def __len__(self):return len(self.Img_path)3.测试
我们通过以下代码来进行演示:
在我的项目中,有flowers这个数据集,然后下面又分了几个文件夹代码不同的花的数据集

我们想获取第4张雏菊的照片,我们的根数据集是flowers,我们就可以创建daisy_label数据集对象。
root_dir = "folwers\\"#表示根目录为flowers,这里用两杠是因为要构成转义字符
daisy_dir = "daisy" #表示我们需要的数据在“daisy”文件夹下面
daisy_dataset = MyData(root_dir,daisy_dir)
然后,我们获取第4个数据和它的label并将其展现出来
img,lebel = daisy_dataset.__getitem__(4)
img.show()
print(lebel)我们得到以下运行结果:
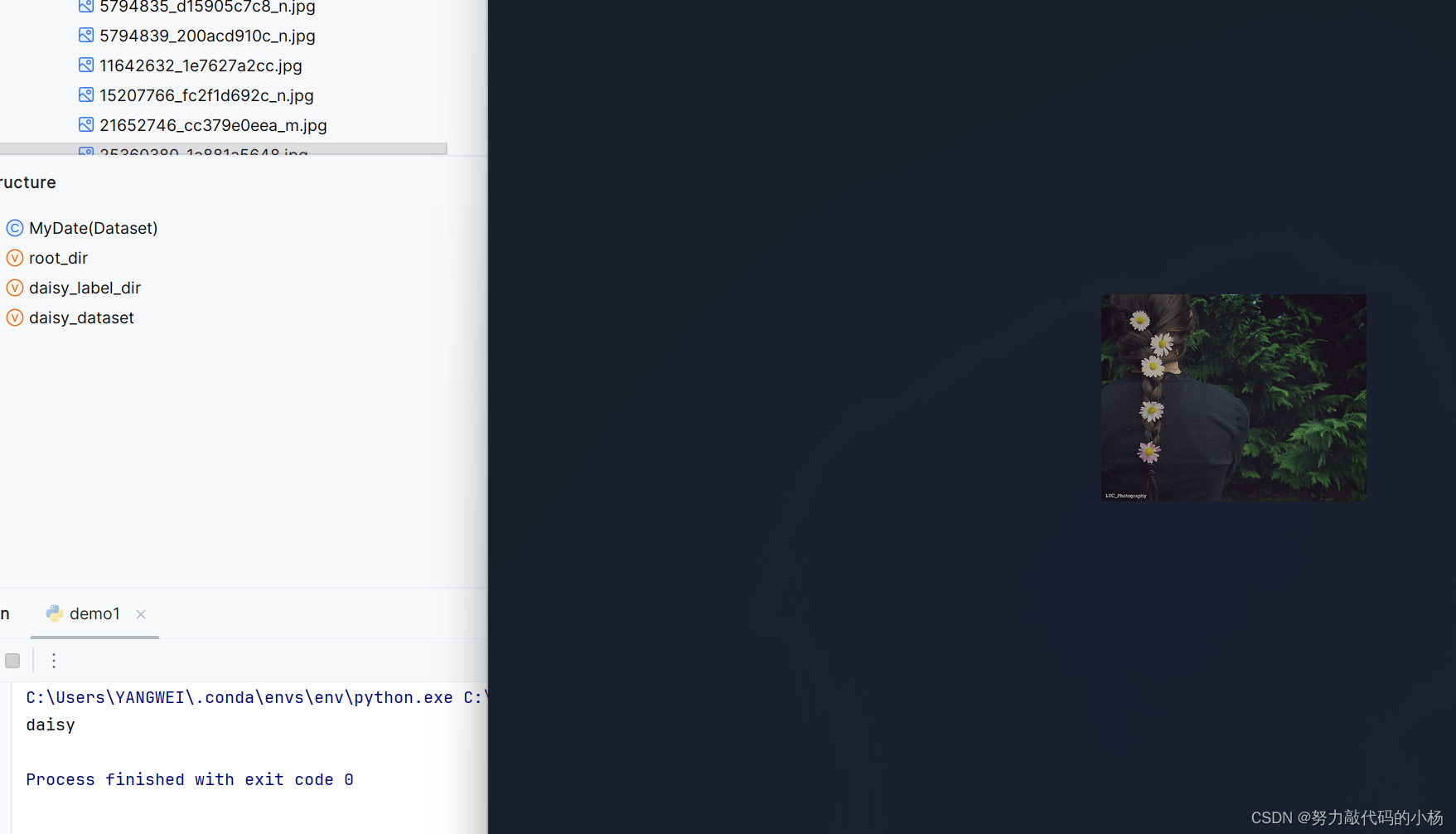 成功获取到了目标数据和它的label。
成功获取到了目标数据和它的label。
三、源码展示
MyData(Dataset):
#构造方法,将文件夹名称以及子文件夹传入def __init__(self,root_dir,label_dir):self.root_dir = root_dirself.label_dir=label_dirself.path=os.path.join(self.root_dir+self.label_dir)self.Img_path=os.listdir(self.path)#获取数据集中第idx个数据以及其label,我们可以通过索引获取数据对象def __getitem__(self, inx):Img_name = self.Img_path[inx]Img_item_path = os.path.join(self.root_dir,self.label_dir,Img_name)img = Image.open(Img_item_path)label = self.label_dirreturn img,label#获取数据集的长度def __len__(self):return len(self.Img_path)root_dir = "flowers\\"
daisy_label_dir = "daisy"
daisy_dataset = MyDate(root_dir,flowers_label_dir)img,lebel = daisy_dataset.__getitem__(4)
img.show()
print(lebel)