专门做调研的网站成全高清视频免费观看
Android双目三维重建:Android双目摄像头实现双目测距
目录
Android双目三维重建:Android双目摄像头实现双目测距
1.开发版本
2.Android双目摄像头
3.双目相机标定
(1)双目相机标定-Python版
(2)双目相机标定-Matlab版
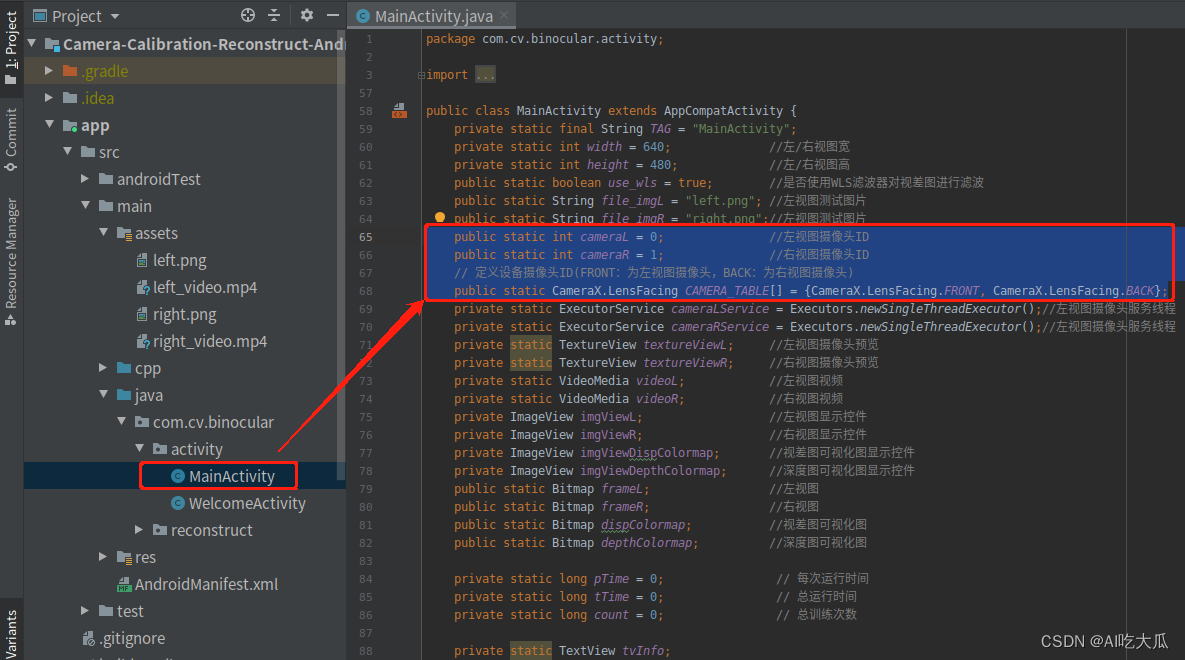
4.相机参数配置
5.Android 双目测距
(1) 核心算法
(2) JNI C++接口
(3) JNI Java接口
6. Android Demo测试效果
7.双目三维重建项目代码(Android版本)下载
8. 双目三维重建项目代码(C/C++版本)
9. 双目三维重建项目代码(Python版本)
10.参考资料
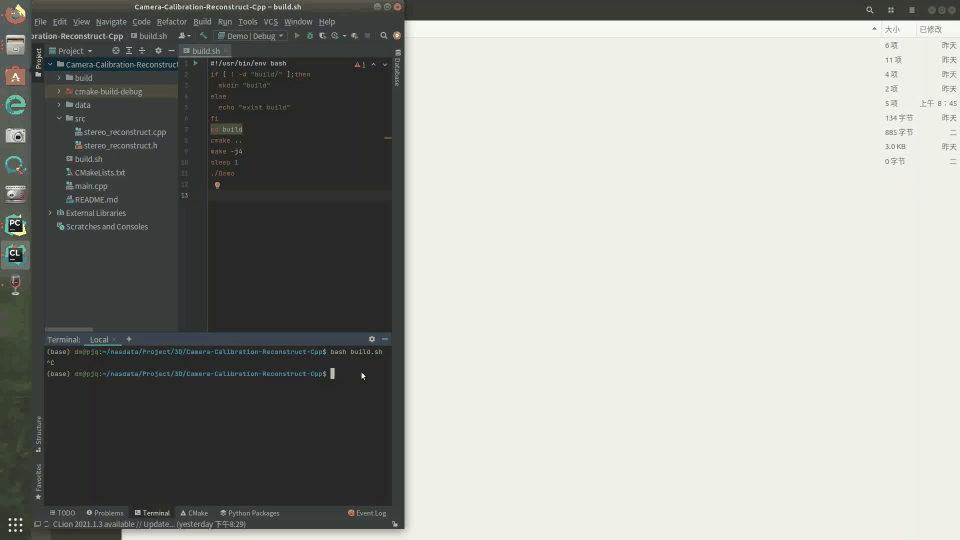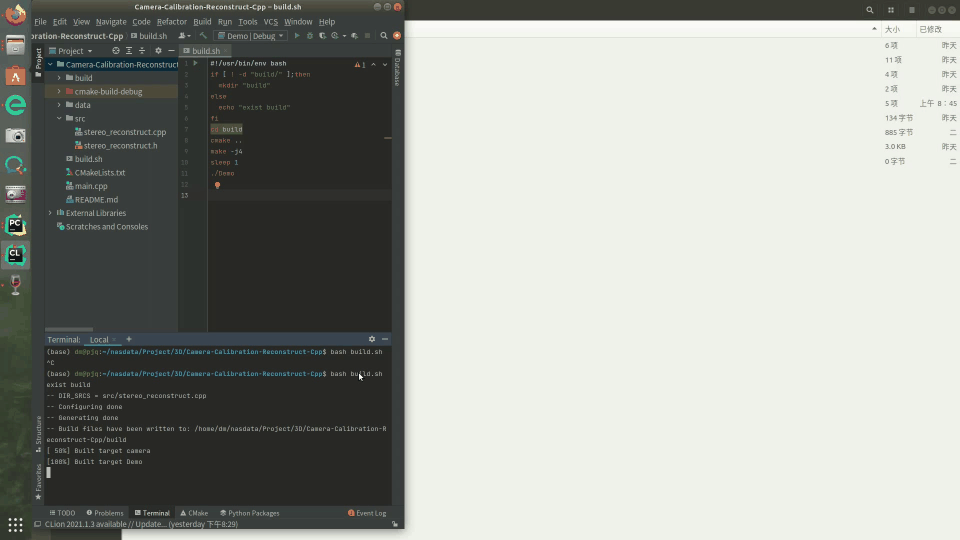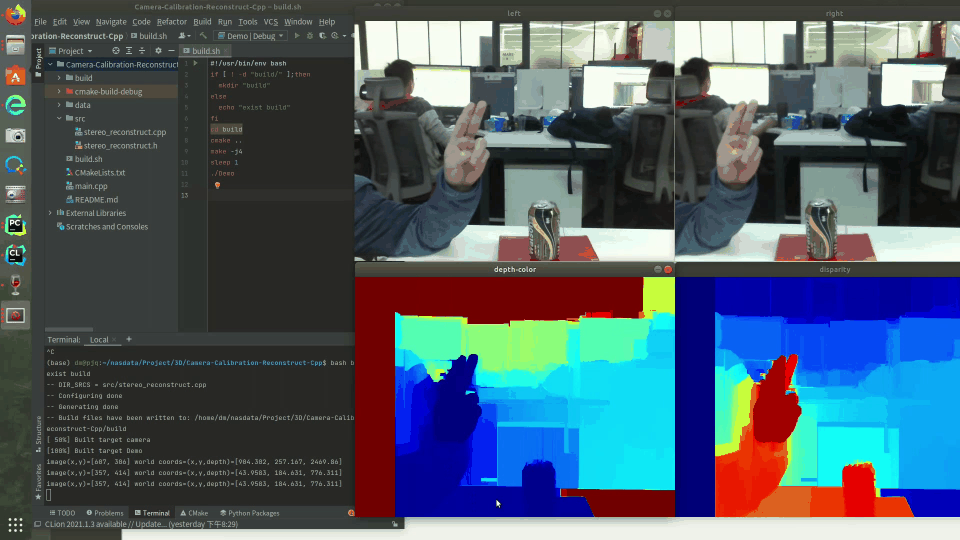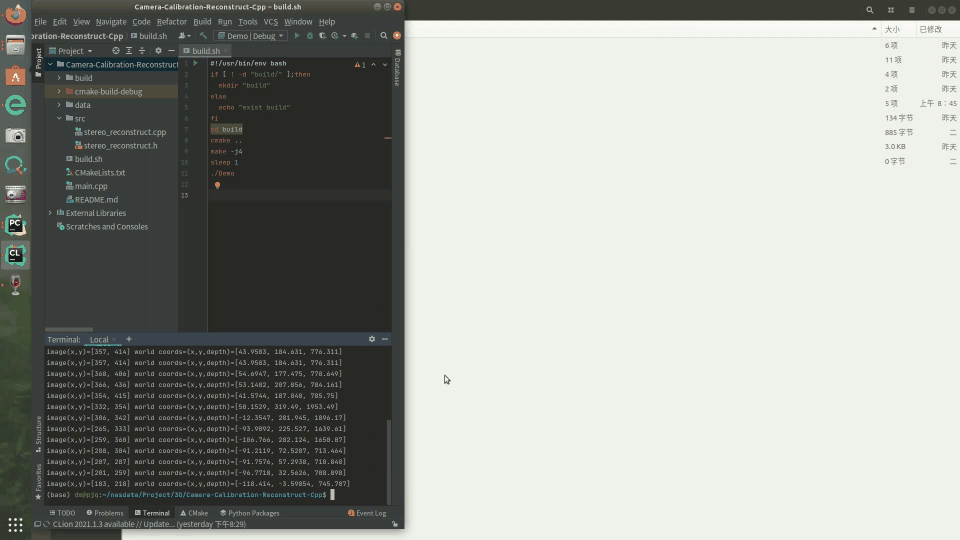
本篇博文是《双目三维重建系统(双目标定+立体校正+双目测距+点云显示)Python》的续作,我们将使用OpenCV C++实现双目测距,并将算法移植到Android系统,实现一个Android版本双目三维重建系统。由于我们只考虑三维重建实现双目测距效果,因而去除了PCL和Open3d库三维显示效果,但依然保留了视差图,深度图等可视化效果,用户可以通过触摸手机屏幕点击图像位置,即可获得对应的世界坐标以及深度距离信息。
从效果来看,Android版本的双目测距和Python版本的效果几乎一致,可以达到准实时的检测效果,基本可以达到工业级别测距精度,可在Android开发板运行,非常适合应用于无人机,智能小车测距避障等场景。
来~先看一下Android版本的Demo效果图(触摸手机屏幕点击图像位置,会显示对应距离信息):
Android版本的Demo体验:https://download.csdn.net/download/guyuealian/87611878
| 未使用WLS滤波器 | 使用WLS滤波器 |
 |  |
诚然,网上有很多C++版本双测距的代码,但项目都不是十分完整,而且恢复视差图效果也一般,难以达到商业实际应用,究其原因,主要有下面几个:
- 双目摄像头质量问题,
- 双目标定存在问题,导致校准误差较大
- 没有使用WLS滤波器对视差图进行滤波,该方法可以极大提高视差图的效果
本篇将着重介绍OpenCV C++项目实现双目测距的过程,关于双目相机标定+双目校正+双目匹配等内容,请查看鄙人另一篇博客 《双目三维重建系统(双目标定+立体校正+双目测距+点云显示)Python》
【尊重原则,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/129762989
更多项目《OpenCV实现双目测距》系列文章请参考:
- OpenCV实现双目测距(Python版本)双目三维重建系统(双目标定+立体校正+双目测距+点云显示)Python
- OpenCV实现双目测距(C/C++版本)OpenCV C++双目三维重建:双目摄像头实现双目测距
- OpenCV实现双目测距(Android版本)https://blog.csdn.net/guyuealian/article/details/129762989

1.开发版本
Android SDK,NDK,Jave等版本信息,请参考:

项目开发需要依OpenCV库,同时也需要用到opencv_contrib库
- opencv 4.5.3
- opencv_contrib 4.5.3
Android项目源码,已经配置好了opencv,无需重新下载和配置
2.Android双目摄像头
开发前,你需要准备有一台Android系统的双目摄像头,要求如下
- 从双目三维重建原理中可知,左右摄像头的成像平面尽可能在一个平面内,成像平面不在同一个平面的,尽管可以立体矫正,其效果也差很多。
- 双目摄像头必须是同一个平面,不能一个前置摄像头,一个后置摄像头(代码层面可以分为前置和后置摄像头,但实物机器必须同时前置或者同时后置)
- 基线不太建议太小,作为测试,一般baseline在3~9cm就可以满足需求,有些无人车的双目基线更是恐怖到1~2米长
- 一分钱,一分货,相机的质量好坏,直接决定了你的成像效果
- 双目摄像头必须重新标定获得双目相机内外参数信息,然后编辑源码,修改为自己双目相机的相机参数

3.双目相机标定
注意,Android版本的双目三维重建系统的源码,不涉及双目标定的相关内容,如果那你需要适配自己的手机双目摄像头,你需要重新标定,详细步骤参考如下:
(1)双目相机标定-Python版
请参考鄙人另一篇博客,无需Matlab,即可进行相机标定:双目三维重建系统(双目标定+立体校正+双目测距+点云显示)Python
该方法双目标定完成后,会得到一个双目相机内外参数信息(stereo_cam.yml)文件:
%YAML:1.0
---
size: !!opencv-matrixrows: 2cols: 1dt: ddata: [ 640., 480. ]
K1: !!opencv-matrixrows: 3cols: 3dt: ddata: [ 7.6159209686584518e+02, 0., 3.2031427422505453e+02, 0.,7.6167321445963728e+02, 2.2467546927337131e+02, 0., 0., 1. ]
D1: !!opencv-matrixrows: 1cols: 5dt: ddata: [ 3.4834574885170888e-02, -5.5261651661983137e-02,5.7491952731614823e-04, -4.2764224824172658e-05,1.8477350140315381e-02 ]
K2: !!opencv-matrixrows: 3cols: 3dt: ddata: [ 7.6327773941976670e+02, 0., 2.8768149948082271e+02, 0.,7.6350419442870850e+02, 2.1897333598636970e+02, 0., 0., 1. ]
D2: !!opencv-matrixrows: 1cols: 5dt: ddata: [ 3.5020972475517692e-02, -4.0770660841280497e-02,-4.4231087565750534e-04, -1.0552562170995372e-03,-9.7749906830348537e-02 ]
R: !!opencv-matrixrows: 3cols: 3dt: ddata: [ 9.9999370552351063e-01, 7.8563885326366346e-04,3.4600122760633780e-03, -7.9503151737356746e-04,9.9999600079883766e-01, 2.7140949167922721e-03,-3.4578661403601796e-03, -2.7168286517956050e-03,9.9999033095517087e-01 ]
T: !!opencv-matrixrows: 3cols: 1dt: ddata: [ -6.0005833133148414e+01, 1.7047017063672587e-01,6.0300223404957642e-01 ]
E: !!opencv-matrixrows: 3cols: 3dt: ddata: [ -1.1005724987007073e-04, -6.0346296076620343e-01,1.6883191705475561e-01, 3.9550629985097430e-01,-1.6255182474732952e-01, 6.0007339329190145e+01,-1.2276256904913259e-01, -6.0005727085740176e+01,-1.6345135556766910e-01 ]
F: !!opencv-matrixrows: 3cols: 3dt: ddata: [ -6.7250769136371160e-10, -3.6870834234286016e-06,1.6143104894409041e-03, 2.4160347372858321e-06,-9.9287680075344234e-07, 2.7862421257891157e-01,-1.1014218394645766e-03, -2.7856049650040260e-01, 1. ]
R1: !!opencv-matrixrows: 3cols: 3dt: ddata: [ 9.9997618806974742e-01, -2.0278309638726887e-03,-6.5963016213173775e-03, 2.0367881225372914e-03,9.9999701250432615e-01, 1.3514719999064883e-03,6.5935413581266105e-03, -1.3648750875444691e-03,9.9997733090723306e-01 ]
R2: !!opencv-matrixrows: 3cols: 3dt: ddata: [ 9.9994547731576255e-01, -2.8407384289991728e-03,-1.0048512373976153e-02, 2.8270879178959596e-03,9.9999506202764499e-01, -1.3724045434755307e-03,1.0052361397026631e-02, 1.3439216883706559e-03,9.9994857062992937e-01 ]
P1: !!opencv-matrixrows: 3cols: 4dt: ddata: [ 7.3741438842621210e+02, 0., 3.1126281356811523e+02, 0., 0.,7.3741438842621210e+02, 2.2189782714843750e+02, 0., 0., 0., 1.,0. ]
P2: !!opencv-matrixrows: 3cols: 4dt: ddata: [ 7.3741438842621210e+02, 0., 3.1126281356811523e+02,-4.4251577456670653e+04, 0., 7.3741438842621210e+02,2.2189782714843750e+02, 0., 0., 0., 1., 0. ]
Q: !!opencv-matrixrows: 4cols: 4dt: ddata: [ 1., 0., 0., -3.1126281356811523e+02, 0., 1., 0.,-2.2189782714843750e+02, 0., 0., 0., 7.3741438842621210e+02, 0.,0., 1.6664137886344466e-02, 0. ]
参数说明:
- 参数size,对应图像宽高(width,height)
- 参数K1,对应左目相机内参矩阵(3×3)
- 参数D1,对应左目相机畸变系数矩阵(5×1)
- 参数K2,对应右目相机内参矩阵(3×3)
- 参数D2,对应右目相机畸变系数矩阵(5×1)
- 参数T,对应双目相机平移向量T(3×1)
- 参数R,对应双目相机旋转矩阵R(3×3)
- 至于配置文件中的参数,如R1, R2, P1, P2, Q这些重投影矩阵,可默写即可,不用修改,这些在运行时,会重新计算。
(2)双目相机标定-Matlab版
网上已经存在很多Matlab双目相机标定的教程,请自行百度哈 ;使用Matlab工具箱进行双目相机标定后,请对应参数进行修改
需要注意的是:旋转矩阵R是(3×3)二维矩阵,而Matlab给出的是旋转向量om(1×3),请使用cv2.Rodrigues()将旋转向量转为旋转矩阵,参考下面的代码进行转换
import cv2import numpy as np# 定义旋转矩阵R,旋转向量omR = [[9.9999370551606337e-01, 7.8563882630048958e-04, 3.4600144345510440e-03],[-7.9503149273969136e-04, 9.9999600080163187e-01, 2.7140938945082542e-03],[-3.4578682997252063e-03, -2.7168276311286426e-03, 9.9999033095047696e-01]]R = np.asarray(R)print(f"旋转矩阵R:\n {R}")# 把旋转矩阵R转化为旋转向量omom, _ = cv2.Rodrigues(R)print(f"旋转向量om:\n {om}")# 把旋转向量om转换为旋转矩阵RR1, _ = cv2.Rodrigues(om)print(f"旋转矩阵R1:\n {R1}")
4.相机参数配置
- 双目相机标定完成后,得到了相机内外参数信息
- 根据自己相机参数,修改项目app/src/main/cpp/src/stereo_reconstruct.h文件
- 下面C++代码中,定义了双目相机CameraParam变量camera1,用户需要根据自己的双目相机,修改对应的相机内外参数。
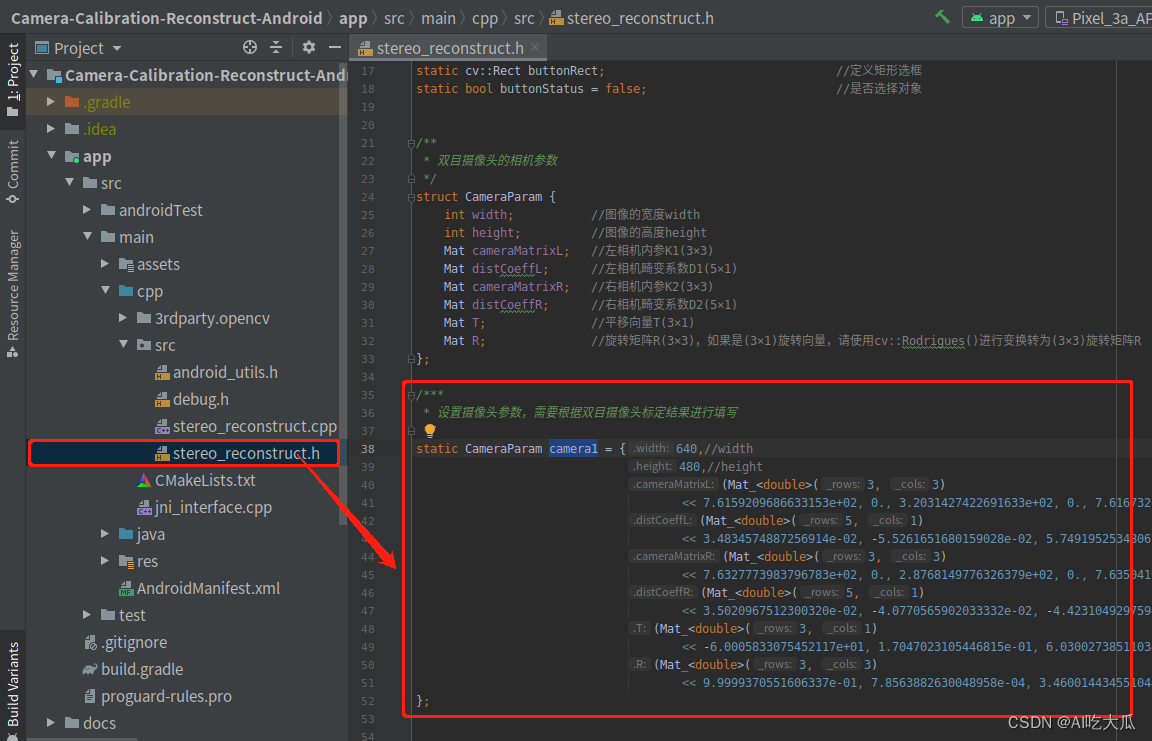
/*** 双目摄像头的相机参数*/
struct CameraParam {
int width; //图像的宽度width
int height; //图像的高度height
Mat cameraMatrixL; //左相机内参K1(3×3)
Mat distCoeffL; //左相机畸变系数D1(5×1)
Mat cameraMatrixR; //右相机内参K2(3×3)
Mat distCoeffR; //右相机畸变系数D2(5×1)
Mat T; //平移向量T(3×1)
Mat R; //旋转矩阵R(3×3),如果是(3×1)旋转向量,请使用cv::Rodrigues()进行变换转为(3×3)旋转矩阵R
};/**** 设置摄像头参数,需要根据双目摄像头标定结果进行填写*/
static CameraParam camera1 = {
640,//width
480,//height
(Mat_<double>(3, 3)
<< 7.6159209686633153e+02, 0., 3.2031427422691633e+02, 0., 7.6167321446015626e+02, 2.2467546926913309e+02, 0., 0., 1.),//cameraMatrixL
(Mat_<double>(5, 1)
<< 3.4834574887256914e-02, -5.5261651680159028e-02, 5.7491952534806736e-04, -4.2764223950233445e-05, 1.8477350164208820e-02),//distCoeffL
(Mat_<double>(3, 3)
<< 7.6327773983796783e+02, 0., 2.8768149776326379e+02, 0., 7.6350419482215057e+02, 2.1897333669573928e+02, 0., 0., 1.),
(Mat_<double>(5, 1)
<< 3.5020967512300320e-02, -4.0770565902033332e-02, -4.4231049297594003e-04, -1.0552565496142535e-03, -9.7750314807571667e-02),
(Mat_<double>(3, 1)
<< -6.0005833075452117e+01, 1.7047023105446815e-01, 6.0300273851103448e-01),
(Mat_<double>(3, 3)
<< 9.9999370551606337e-01, 7.8563882630048958e-04, 3.4600144345510440e-03, -7.9503149273969136e-04, 9.9999600080163187e-01, 2.7140938945082542e-03, -3.4578682997252063e-03, -2.7168276311286426e-03, 9.9999033095047696e-01),
};
5.Android 双目测距
Android OpenCV版本的双目测距与Python版本双目测距的效果几乎一致,基本可以达到工业级别测距精度。由于我们只考虑三维重建实现双目测距效果,因而去除了PCL和Open3d库三维显示效果,但依然保留了视差图,深度图等可视化效果,用户可以通过触摸手机屏幕点击图像位置,即可获得对应的世界坐标以及深度距离信息。
(1) 核心算法
Android版本的双目测距算法,核心代码都使用C++开发,上层应用Java部分通过JNI调用opencv C++算法,函数接口声明,都已经给出了详细的参数说明,为了方便大家学习,函数命名和实现逻辑与Python版本的几乎一致:
| Python版本 | C++版本 |
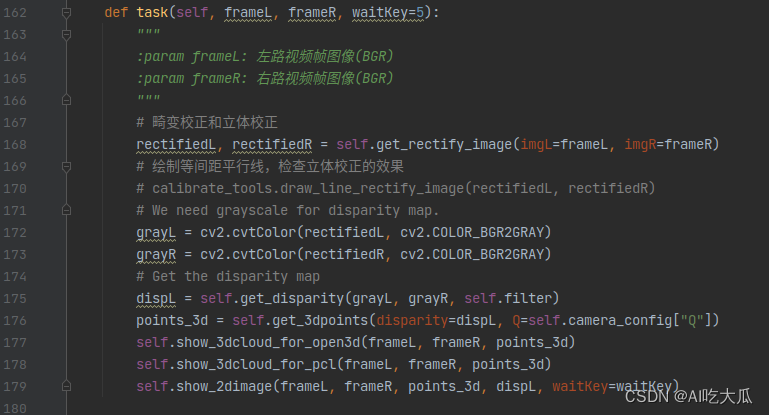 | 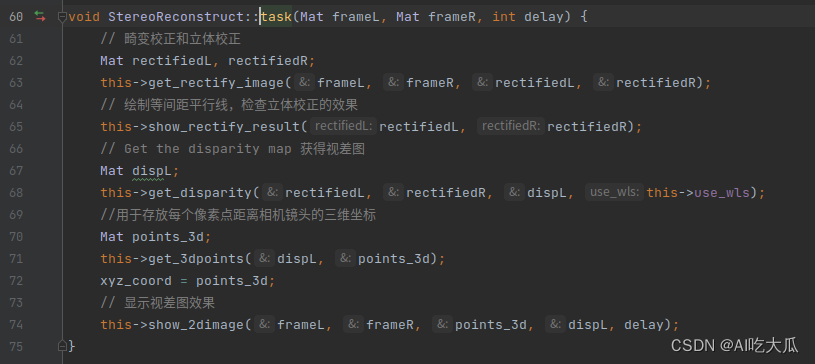 |
- 这是C++核心算法部分函数定义
//
// Created by 390737991@qq.com on 2018/10/6.
//#ifndef CAMERA_CALIBRATION_RECONSTRUCT_CPP_STEREO_RECONSTRUCT_H
#define CAMERA_CALIBRATION_RECONSTRUCT_CPP_STEREO_RECONSTRUCT_H#include <opencv2/opencv.hpp>
#include <iostream>using namespace std;
using namespace cv;static cv::Mat xyz_coord; //用于存放每个像素点距离相机镜头的三维坐标
static cv::Point start; //鼠标按下的起始点
static cv::Rect buttonRect; //定义矩形选框
static bool buttonStatus = false; //是否选择对象/*** 双目摄像头的相机参数*/
struct CameraParam {int width; //图像的宽度widthint height; //图像的高度heightMat cameraMatrixL; //左相机内参K1(3×3)Mat distCoeffL; //左相机畸变系数D1(5×1)Mat cameraMatrixR; //右相机内参K2(3×3)Mat distCoeffR; //右相机畸变系数D2(5×1)Mat T; //平移向量T(3×1)Mat R; //旋转矩阵R(3×3),如果是(3×1)旋转向量,请使用cv::Rodrigues()进行变换转为(3×3)旋转矩阵R
};/**** 设置摄像头参数,需要根据双目摄像头标定结果进行填写*/
static CameraParam camera1 = {640,//width480,//height(Mat_<double>(3, 3)<< 7.6159209686633153e+02, 0., 3.2031427422691633e+02, 0., 7.6167321446015626e+02, 2.2467546926913309e+02, 0., 0., 1.),//cameraMatrixL(Mat_<double>(5, 1)<< 3.4834574887256914e-02, -5.5261651680159028e-02, 5.7491952534806736e-04, -4.2764223950233445e-05, 1.8477350164208820e-02),//distCoeffL(Mat_<double>(3, 3)<< 7.6327773983796783e+02, 0., 2.8768149776326379e+02, 0., 7.6350419482215057e+02, 2.1897333669573928e+02, 0., 0., 1.),(Mat_<double>(5, 1)<< 3.5020967512300320e-02, -4.0770565902033332e-02, -4.4231049297594003e-04, -1.0552565496142535e-03, -9.7750314807571667e-02),(Mat_<double>(3, 1)<< -6.0005833075452117e+01, 1.7047023105446815e-01, 6.0300273851103448e-01),(Mat_<double>(3, 3)<< 9.9999370551606337e-01, 7.8563882630048958e-04, 3.4600144345510440e-03, -7.9503149273969136e-04, 9.9999600080163187e-01, 2.7140938945082542e-03, -3.4578682997252063e-03, -2.7168276311286426e-03, 9.9999033095047696e-01),
};#ifdef PLATFORM_ANDROIDstatic void onMouse(int event, int x, int y, int, void *) {
}
static void show_image(const string &winname, cv::Mat &image, int delay = 0, int flags = cv::WINDOW_AUTOSIZE) {
}
static bool get_video_capture(string video_file, cv::VideoCapture &cap, int width = -1, int height = -1, int fps = -1) {return true;
}
static bool get_video_capture(int camera_id, cv::VideoCapture &cap, int width = -1, int height = -1, int fps = -1) {return true;
}
#else/**** 鼠标响应回调函数* @param event* @param x* @param y*/
static void onMouse(int event, int x, int y, int, void *) {if (buttonStatus) {buttonRect.x = MIN(x, start.x);buttonRect.y = MIN(y, start.y);buttonRect.width = std::abs(x - start.x);buttonRect.height = std::abs(y - start.y);}switch (event) {case EVENT_LBUTTONDOWN: //鼠标左按钮按下的事件start = Point(x, y);buttonRect = Rect(x, y, 0, 0);buttonStatus = true;cout << "image(x,y)=" << start;cout << " world coords=(x,y,depth)=" << xyz_coord.at<Vec3f>(start) << endl;break;case EVENT_LBUTTONUP: //鼠标左按钮释放的事件buttonStatus = false;if (buttonRect.width > 0 && buttonRect.height > 0)break;}
}/**** 显示图像* @param winname 窗口名称* @param image 图像* @param delay 显示延迟,0表示阻塞显示* @param flags 显示方式*/
static void show_image(const string &winname, cv::Mat &image, int delay = 0, int flags = cv::WINDOW_AUTOSIZE) {cv::namedWindow(winname, flags);cv::imshow(winname, image);cv::waitKey(delay);
}/**** 读取视频文件* @param video_file 视频文件* @param cap 视频流对象* @param width 设置图像的宽度* @param height 设置图像的高度* @param fps 设置视频播放频率* @return*/
static bool get_video_capture(string video_file, cv::VideoCapture &cap, int width = -1, int height = -1, int fps = -1) {//VideoCapture video_cap;cap.open(video_file);if (width > 0 && height > 0) {cap.set(cv::CAP_PROP_FRAME_WIDTH, width); //设置图像的宽度cap.set(cv::CAP_PROP_FRAME_HEIGHT, height); //设置图像的高度}if (fps > 0) {cap.set(cv::CAP_PROP_FPS, fps);}if (!cap.isOpened())//判断是否读取成功{return false;}return true;
}/**** 读取摄像头* @param camera_id 摄像头ID号,默认从0开始* @param cap 视频流对象* @param width 设置图像的宽度* @param height 设置图像的高度* @param fps 设置视频播放频率* @return*/
static bool get_video_capture(int camera_id, cv::VideoCapture &cap, int width = -1, int height = -1, int fps = -1) {//VideoCapture video_cap;cap.open(camera_id); //摄像头ID号,默认从0开始if (width > 0 && height > 0) {cap.set(cv::CAP_PROP_FRAME_WIDTH, width); //设置捕获图像的宽度cap.set(cv::CAP_PROP_FRAME_HEIGHT, height); //设置捕获图像的高度}if (fps > 0) {cap.set(cv::CAP_PROP_FPS, fps);}if (!cap.isOpened()) //判断是否成功打开相机{return false;}return true;
}#endifclass StereoReconstruct {
public:/**** 构造函数,初始化StereoReconstruct* @param camera 双目相机参数* @param use_wls 是否使用WLS滤波器对视差图进行滤波* @param vis 是否显示*/StereoReconstruct(CameraParam camera, bool use_wls = true, bool vis = false);/**** release*/~StereoReconstruct();/**** 开始双目测距任务* @param frameL* @param frameR*/void task(Mat frameL, Mat frameR, int delay = 0);/**** 畸变校正和立体校正* @param imgL 左视图* @param imgR 右视图* @param rectifiedL 校正后左视图* @param rectifiedR 校正后右视图*/void get_rectify_image(Mat &imgL, Mat &imgR, Mat &rectifiedL, Mat &rectifiedR);/**** 获得视差图* @param imgL 畸变校正和立体校正后的左视图* @param imgR 畸变校正和立体校正后的右视图* @param dispL 返回视差图* @param use_wls 是否使用WLS滤波器对视差图进行滤波*/void get_disparity(Mat &imgL, Mat &imgR, Mat &dispL, bool use_wls = true);//SGBM匹配算法/**** 计算像素点的3D坐标(左相机坐标系下)* @param disp 视差图* @param points_3d 返回三维坐标points_3d,三个通道分布表示(X,Y,Z),其中Z是深度图depth, 即距离,单位是毫米(mm)* @param scale 单位变换尺度,默认scale=1.0,单位为毫米*/void get_3dpoints(Mat &disp, Mat &points_3d, float scale = 1.0);/**** 将输入深度图转换为伪彩色图,方面可视化* @param depth* @param colormap*/void get_visual_depth(cv::Mat &depth, cv::Mat &colormap, float clip_max = 6000.0);/**** 显示矫正效果* @param rectifiedL* @param rectifiedR*/void show_rectify_result(cv::Mat rectifiedL, cv::Mat rectifiedR);/**** 可视化视差图和深度图* @param frameL* @param frameR* @param points_3d* @param disp* @param delay*/void show_2dimage(Mat &frameL, Mat &frameR, Mat &points_3d, Mat &disp, int delay);/**** 显示Mat的最大最小值* @param src* @param vmin 最小值下限* @param vmax 最大值下限*/void clip(cv::Mat &src, float vmin, float vmax);/**** 显示Mat的最大最小值* @param src* @param th* @param vmin*/void clip_min(cv::Mat &src, float th, float vmin);public:string depth_windows = "depth-color"; // 深度图的窗口名称int vis; // 是否可视化int use_wls; // 是否使用WLS滤波器对视差图进行滤波Size image_size; // 图像宽高(width,height)Rect validROIL; // 图像校正之后,会对图像进行裁剪,这里的左视图裁剪之后的区域Rect validROIR; // 图像校正之后,会对图像进行裁剪,这里的右视图裁剪之后的区域Mat mapLx, mapLy, mapRx, mapRy; // 映射表Mat Rl, Rr, Pl, Pr, Q; // 校正后的旋转矩阵R,投影矩阵P, 重投影矩阵QMat dispL; // 视差图(CV_32F)Mat disp_colormap; // 视差图可视化图(CV_8UC3)Mat depth; // 深度图(CV_32F)Mat depth_colormap; // 深度图可视化图(CV_8UC3)Mat points_3d; // 世界坐标图(CV_32F)cv::Ptr<cv::StereoSGBM> sgbm;
};#endif //CAMERA_CALIBRATION_RECONSTRUCT_CPP_STEREO_RECONSTRUCT_H
(2) JNI C++接口
#include <jni.h>
#include <string>
#include <fstream>
#include "src/stereo_reconstruct.h"
#include "android_utils.h"
#include "debug.h"
#include "opencv2/opencv.hpp"StereoReconstruct *stereo = nullptr;JNIEXPORT jint JNI_OnLoad(JavaVM *vm, void *reserved) {return JNI_VERSION_1_6;
}JNIEXPORT void JNI_OnUnload(JavaVM *vm, void *reserved) {}extern "C"
JNIEXPORT void JNICALL
Java_com_cv_binocular_reconstruct_StereoReconstruct_init(JNIEnv *env, jclass clazz, jboolean use_wls) {CameraParam camera = camera1;//双目相机参数(请根据自己双目相机标定结果进行修改)//bool use_wls = true; //是否使用WLS滤波器对视差图进行滤波stereo = new StereoReconstruct(camera, use_wls, false);
}extern "C"
JNIEXPORT void JNICALL
Java_com_cv_binocular_reconstruct_StereoReconstruct_reBuild(JNIEnv *env, jclass clazz, jobject bitmapL,jobject bitmapR,jobject disp_colormap,jobject depth_colormap) {Mat frameL; // 左视图Mat frameR; // 右视图BitmapToMatrix(env, bitmapL, frameL);BitmapToMatrix(env, bitmapR, frameR);stereo->task(frameL, frameR, 0);MatrixToBitmap(env, stereo->disp_colormap, disp_colormap); //视差图可视化图(CV_8UC3)MatrixToBitmap(env, stereo->depth_colormap, depth_colormap);//视差图可视化图(CV_8UC3)LOGW("frameL : (%d,%d)", frameL.cols, frameL.rows);LOGW("disp_colormap : (%d,%d)", stereo->disp_colormap.cols, stereo->disp_colormap.rows);LOGW("depth_colormap : (%d,%d)", stereo->depth_colormap.cols, stereo->depth_colormap.rows);
}extern "C"
JNIEXPORT jobject JNICALL
Java_com_cv_binocular_reconstruct_StereoReconstruct_getWorld(JNIEnv *env, jclass clazz, jint x,jint y) {cv::Vec3f point = stereo->points_3d.at<Vec3f>(Point(x, y));float cx = point[0];float cy = point[1];float cz = point[2];LOGW("image(x,y)=[%d,%d] world=(x,y,depth)=[%3.2f,%3.2f,%3.2f]mm", x, y, cx, cy, cz);auto cls_point = env->FindClass("com/cv/binocular/reconstruct/Point3d");auto init_id = env->GetMethodID(cls_point, "<init>", "(FFF)V");env->PushLocalFrame(1);jobject obj = env->NewObject(cls_point, init_id, cx, cy, cz);obj = env->PopLocalFrame(obj);return obj;
}(3) JNI Java接口
package com.cv.binocular.reconstruct;import android.graphics.Bitmap;public class StereoReconstruct {static {System.loadLibrary("binocular_wrapper");}/**** 初始化* @param use_wls 是否使用WLS滤波器对视差图进行滤波*/public static native void init(boolean use_wls);/**** 进行双目三维重建* @param frameL: 输入左视图* @param frameR:输入右视图* @param disp_colormap:输出视差图可视化图* @param depth_colormap:输出深度图可视化图* @return*/public static native void reBuild(Bitmap frameL, Bitmap frameR, Bitmap disp_colormap, Bitmap depth_colormap);/**** 将图像坐标映射为世界坐标(world coordinate)* @param x 输入图像像素坐标x* @param y 输入图像像素坐标y* @return Point3d世界坐标(x, y, z),其中z为深度距离*/public static native Point3d getWorld(int x, int y);
}
6. Android Demo测试效果
Android版本双目测距Demo源码提供图片,视频和摄像头三种方式测试
- Android Demo图片测试:项目资源(src/main/assets)自带一对左右视图的测试图片,你需要将测试图片拷贝到你的手机,然后在Demo APP点击【图片】打开图片即可;如果你想测试自己的图片,请将左视图文件命名为left***.png,右视图文件命名为right***.png,否则不能正常加载左右视图。图片格式支持jpg,png等多种格式
- Android Demo视频测试:项目资源(src/main/assets)自带一对左右视图的视频文件,你需要将测试视频拷贝到你的手机,然后在Demo APP点击【视频】打开视频即可;如果你想测试自己的视频,请将左视图视频文件命名为left***.mp4,右视图视频文件命名为right***.mp4,否则不能正常加载左右视图。视频格式支持mp4,avi等多种格式
- Android Demo摄像头测试:需要Android设备支持两个摄像头,源码部分cameraL = 0对应前置摄像头,cameraR = 1对应后置摄像头,仅作为Android手机测试使用;真实Android手机,双目摄像头必须要同一平面上。
Android版本的Demo效果图(触摸手机屏幕点击图像位置,会显示对应距离信息):
Android版本的Demo体验:https://download.csdn.net/download/guyuealian/87611878

从测试效果可以看到,使用WLS滤波后,视差图的整体效果都有明显改善,但速度会变慢哦
| 未使用WLS滤波器 | 使用WLS滤波器 |
| |
 |  |
7.双目三维重建项目代码(Android版本)下载
完整的Android项目代码请公众号咨询联系(非无偿)
整体Android项目源码包含:
- Demo支持使用WLS滤波器对视差图进行滤波
- Demo支持双目测距,误差在1cm内(触摸手机屏幕点击图像位置,会显示对应距离信息)
- Demo支持图片,视频,摄像头测试
- 所有依赖库都已经配置好,可直接build运行
8. 双目三维重建项目代码(C/C++版本)
目前已经实现了OpenCV C++版本的双目测距,与Python版本效果几乎一致,
详细请查看鄙人另一篇博客《OpenCV C++双目摄像头实现双目测距》:OpenCV C++双目三维重建:双目摄像头实现双目测距_opencv双目三维重建_AI吃大瓜的博客-CSDN博客
9. 双目三维重建项目代码(Python版本)
如果你需要Python版本的双目测距, 请查看鄙人另一篇博客《双目三维重建系统(双目标定+立体校正+双目测距+点云显示)Python》
| 双目测距Demo视频 |
10.参考资料
- OpenCV C++双目三维重建:双目摄像头实现双目测距
- 双目三维重建:双目摄像头实现双目测距(Python)
- 双目三维重建系统(双目标定+立体校正+双目测距+点云显示)Python
-
https://blog.csdn.net/guyuealian/article/details/129762989
- Ubuntu18.04安装opencv和opencv_contrib