水利建设管理司网站长沙百度网站推广
方法一:设置环境变量
- 打开“控制面板” > “系统和安全” > “系统”。
- 点击“高级系统设置”。
- 在“系统属性”窗口中,点击“环境变量”。
- 在“系统变量”部分,点击“新建”,创建一个新的变量:
- 变量名:
JAVA_TOOL_OPTIONS- 变量值:
-Dfile.encoding=UTF-8
- 点击“确定”保存设置。
检查配置是否成功
- 打开命令提示符(Command Prompt)。
- 输入以下命令运行一个简单的Java程序来检查编码:
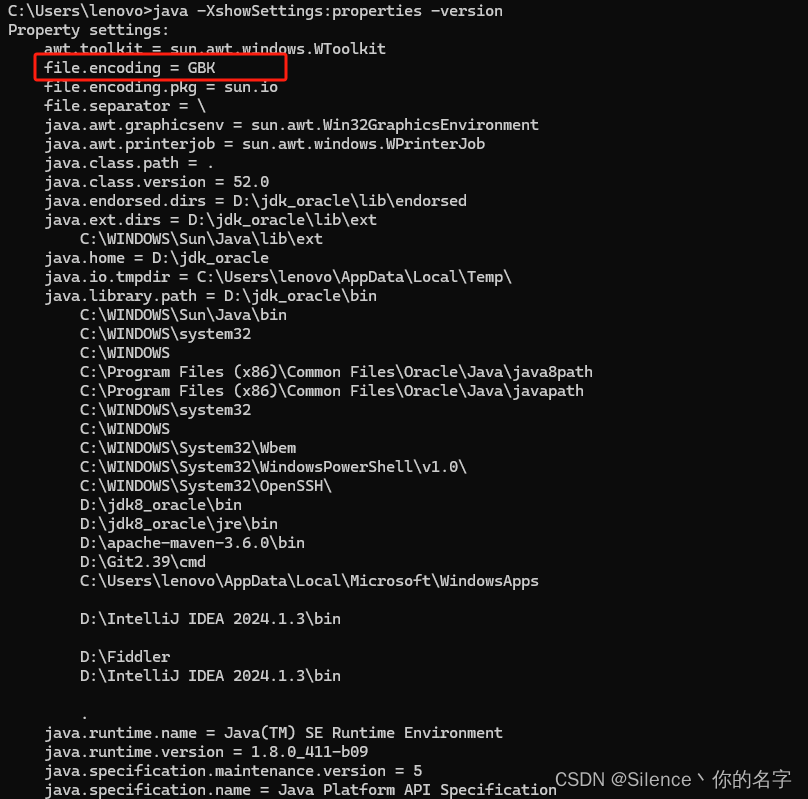
java -XshowSettings:properties -version- 在输出结果中,查找
file.encoding项。如果配置成功,你应该会看到类似以下内容:
file.encoding = UTF-8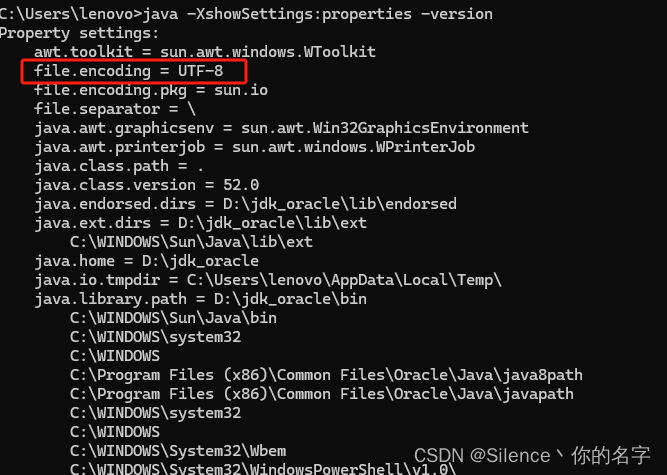
通过这些步骤,你可以在Windows系统上设置JDK的默认编码为UTF-8并验证设置是否成功。
注意
如果在输出中你仍然看到 sun.jnu.encoding = GBK,请注意这表示Java在与操作系统交互时使用的编码,可能因为操作系统的默认编码是GBK。只要 file.encoding 是 UTF-8,你的Java应用程序将使用UTF-8编码。