网站的内容策略wordpress屏蔽蜘蛛爬虫
rufus制作ubantu的U盘安装介质时,rufus软件界面上的分区类型选什么(如下图)?
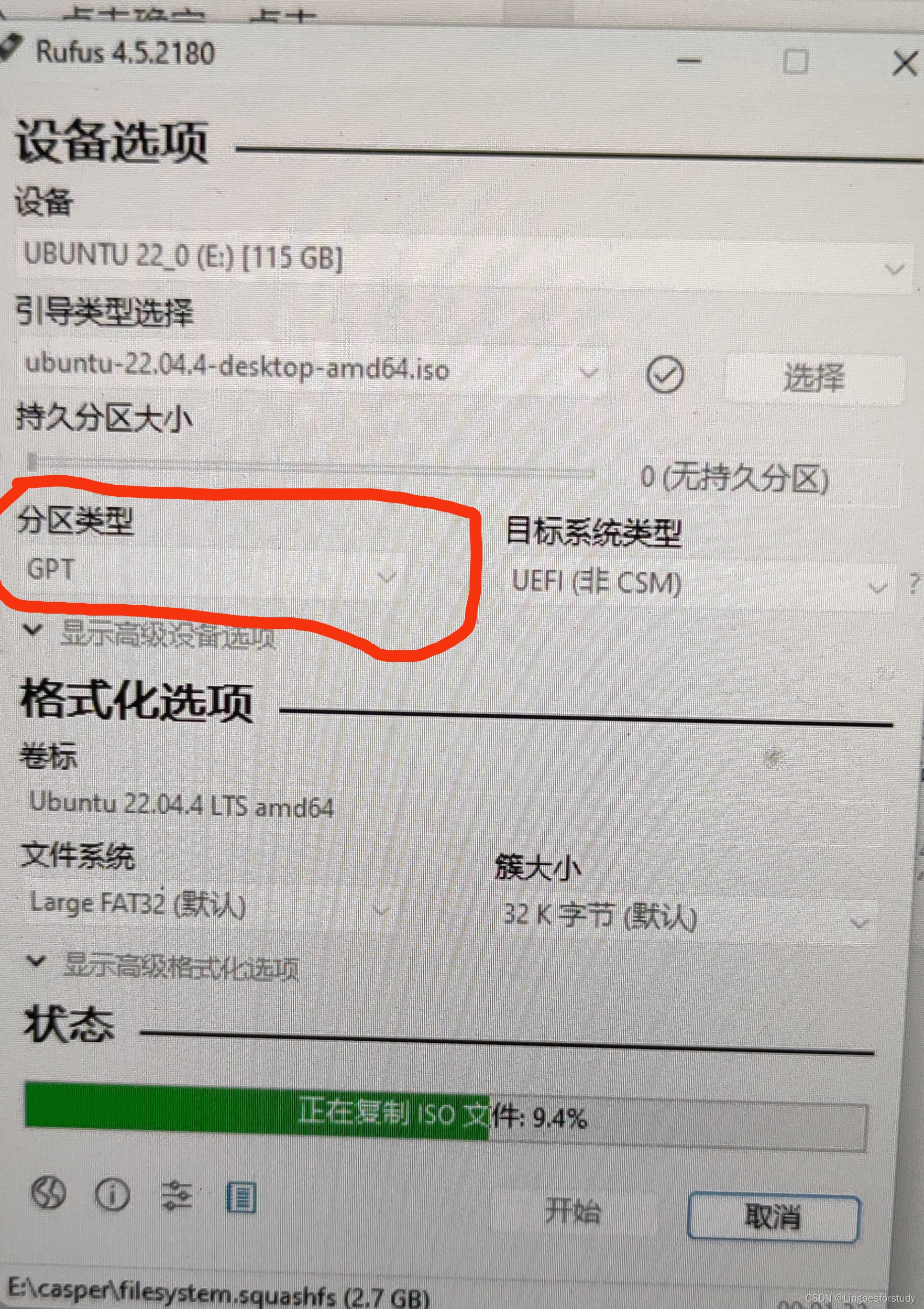
在使用Rufus制作Ubuntu的U盘安装介质时,分区类型的选择取决于我们的计算机的引导方式。
以下是具体的选择建议:
1、查看计算机的引导方式:
- 打开计算机并进入BIOS设置界面(通常在开机时按下F2、Delete键或根据计算机型号查找正确的按键组合)。
- 查找“Boot”选项卡或类似的选项,然后查看“Boot Mode”或“Boot List Option”等设置。
- 如果我们看到“Legacy”或“BIOS”等术语,则表示我们的计算机使用的是BIOS引导方式。
- 如果我们看到“UEFI”或“UEFI Boot”等术语,则表示我们的计算机使用的是UEFI引导方式。
2、根据引导方式选择分区类型:
- 如果我们的计算机使用BIOS引导方式,则选择MBR(Master Boot Record)分区类型。MBR是传统的分区表格式,适用于大多数旧版本的操作系统和旧的BIOS系统。
- 如果我们的计算机使用UEFI引导方式,则选择GPT(GUID Partition Table)分区类型。GPT是新一代的分区表格式,支持更大容量的硬盘以及更多的主要分区和逻辑分区,同时提供更好的数据完整性和容错能力。
3、文件系统选择:
- 在制作Ubuntu的U盘安装介质时,除了分区类型外,还需要选择文件系统。为了确保最佳的兼容性和可引导性,建议使用FAT32文件系统。虽然NTFS文件系统也可以用于制作可启动USB安装介质,但在某些情况下可能会导致兼容性问题。
综上所述,当我们使用Rufus制作Ubuntu的U盘安装介质时,需要根据我们的计算机的引导方式选择相应的分区类型(BIOS对应MBR,UEFI对应GPT),并建议使用FAT32文件系统以确保兼容性和可引导性。如果在制作或安装过程中遇到问题,请检查我们的分区类型和文件系统设置是否正确,并参考Ubuntu的官方文档或社区论坛获取更多帮助。