解决方案的网站建设wordpress承受访问量
虽然png图片格式是一种无损压缩格式,但是png图片的内存大小也是比较大的,而且兼容性上也没有jpg图片好,许多平台推荐的也都是jpg格式,所以当我们需要把png转jpg格式的时候,就需要用到图片格式转换器,今天推荐的这款图片处理工具,是一款在线图片编辑器--压缩图,它的图片转格式功能支持在线格式转换,省去了下载安装的时间,而且操作也非常简单。
使用浏览器搜索【压缩图】。在导航栏中选择【图片转格式】。

点击输入图片描述(最多30字)
点击选择图片,支持批量处理最大可达60张。

点击输入图片描述(最多30字)
选择要转的格式类型,照片转格式完成后,点击下载保存。
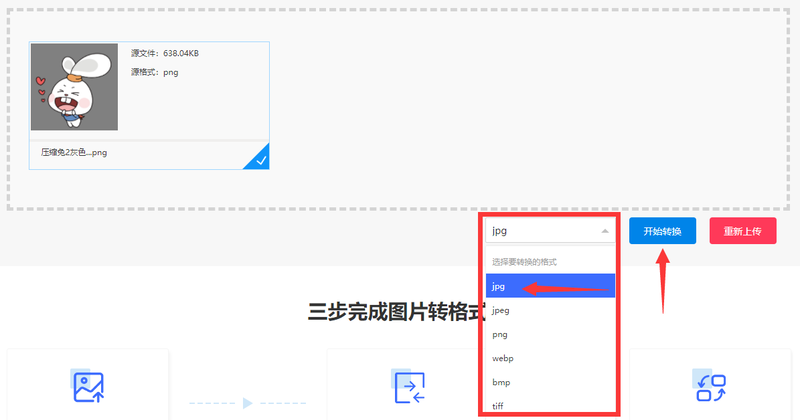
点击输入图片描述(最多30字)
以上就是今天分享的关于png怎么转jpg的操作步骤了,小伙伴们应该都学会了吧,不仅是png、jpg图片格式之间可以相互转换,还有很多其他格式也支持,希望本文可以帮助到大家。