汕头网站网店建设重庆市招标网官网
函数:是指一段可以直接被另一段程序调用的程序或者代码~(MySQL内置)
一.字符串函数
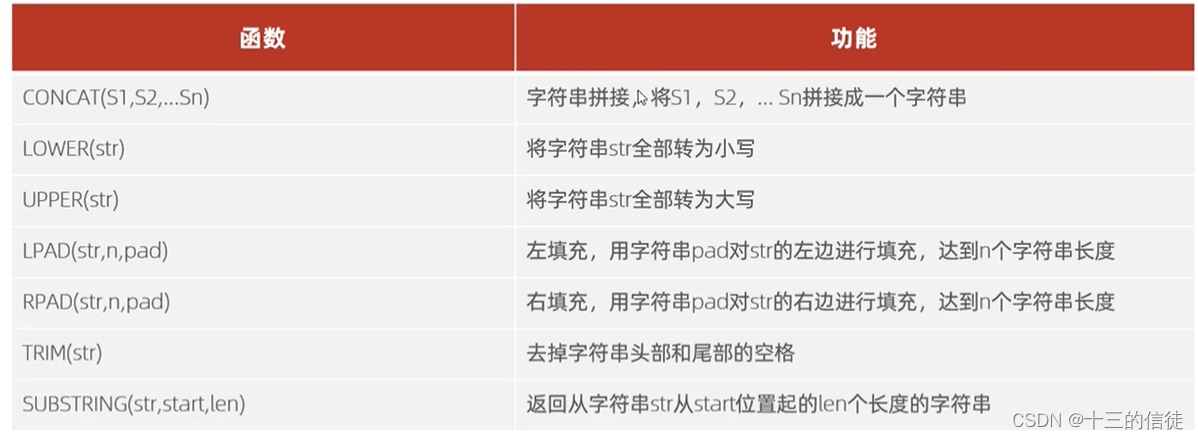
- trim不能去除中间的空格~
select concat('jsl','1325'):执行如上的代码,返回字符串"jsl1325"。
select lower('JSL');执行如上的代码,返回字符串"jsl",即全部转化为小写;upper同理,反之将小写字母均改为大写字母,此处不再赘述~
select lpad('++',5,'x');执行如上的代码,返回字符串"xxx++",第一个参数是待填充的原字符串,x是用来填充字符串的字符,而最后一个参数5则是填充后自字符串的总长度~(右填充是rpad)
select trim(' Hello Old Lover ');执行后结果为Hello Old Lover,注意trim仅仅可以去除掉两侧的空格,中间的空格依旧保留~
select substring('Used to be an ideal',1,4);执行上述代码,返回的结果是Used,后面两个数字参数分别是截取字符串的头位和末位~
二.数值函数

select ceil(1.7);向上取整,结果为2~
select floor(1.4);向下取整,结果为1~
(注意:无论如何都严格遵守取整规则,不存在四舍五入~)
select mod(7,3);简单的取模运算,结果为2~
select rand();返回一个0~1之间的随机数~
select round(3.1415926,2);返回结果为3.14, 即在保留2位小数的情况下四舍五入~
三.日期函数
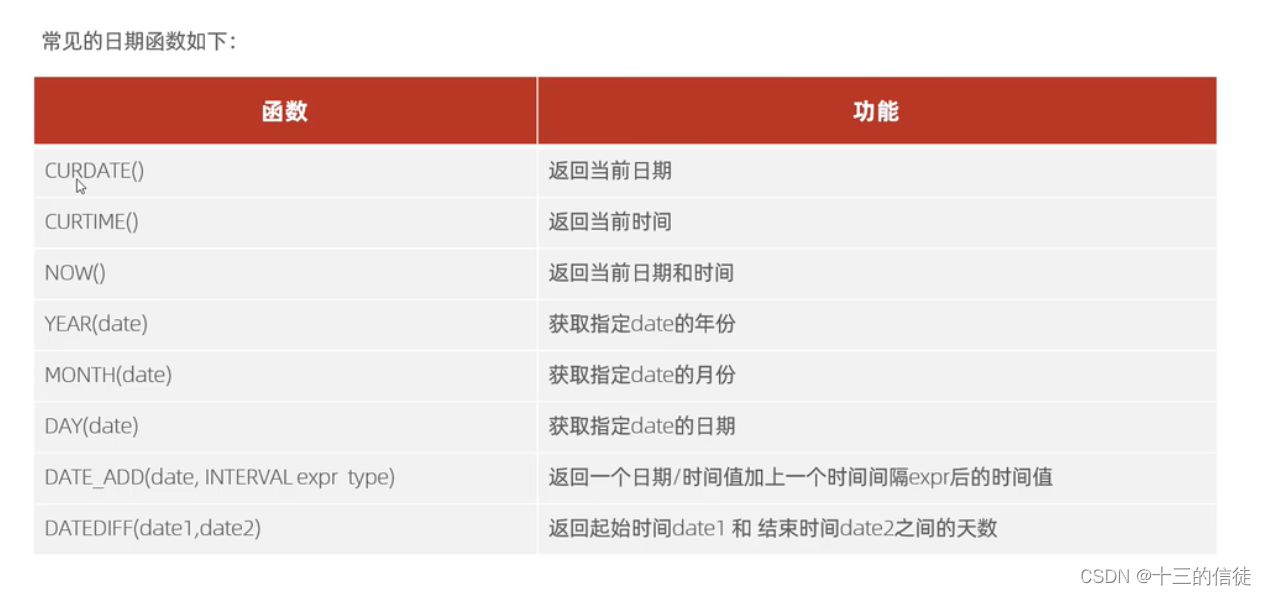
select curdata();
select curtime();
上述两个函数能够分别返回当前的日期和时间,如果修改为now,则可以同时返回日期和时间~
select year(now());
select month(now());
select day(now());分别单独返回当前日期的年月日,可以传入获取当前时间的now,也可以传入字符串格式的日期~
select date_add(now(),interval 5 day);执行上述代码段,获取当前日期是1月16号,5天后即为21号~
select datediff('2023-3-10','2023-12-19');注意,该函数的返回结果为左边减去右边,所以结果为-284天。
四.流程控制函数

实战中常用于判断多个条件为真或者为假的情况~