泉州市住房与城乡建设网站照片做视频的网站
6.4 如何正确使用volatile
单一赋值可以,但是含复合运算赋值不可以(i++之类的)
volatile int a = 10;
volatile boolean flag = true;
状态标志,判断业务是否结束
作为一个布尔状态标志,用于指示发生了一个重要的一次性事件,例如完成初始化或任务结束

销较低的读,写锁策略
当读远多于写,结合使用内部锁和volatile变量来减少同步的开销
原理是:利用volatile保证读操作的可见性,利用synchronized保证符合操作的原子性

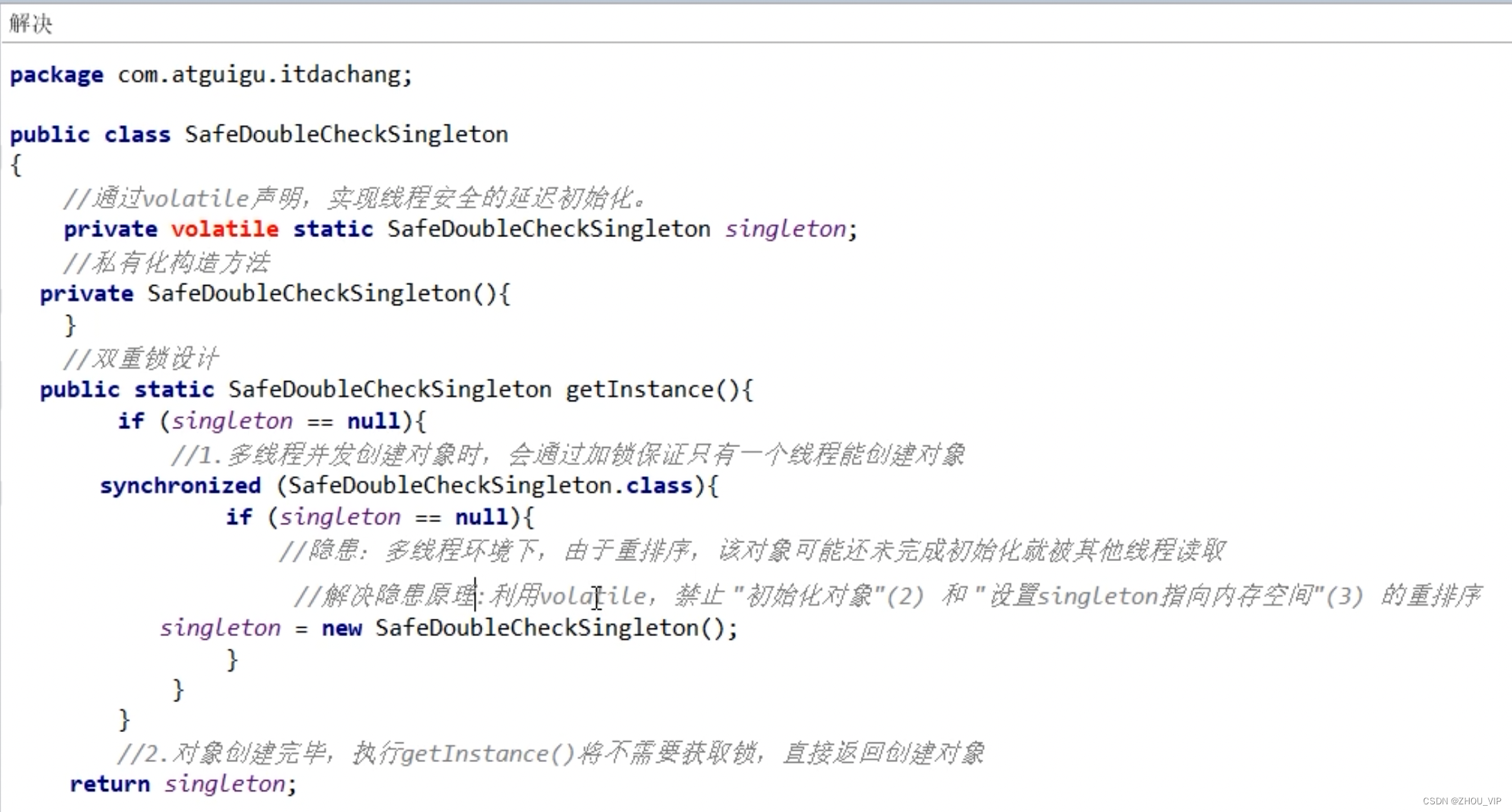
DCL双端锁的发布
问题描述:首先设定一个加锁的单例模式场景