wordpress全站背景wordpress 手机端api
1. 工作原理
1.1 流程图
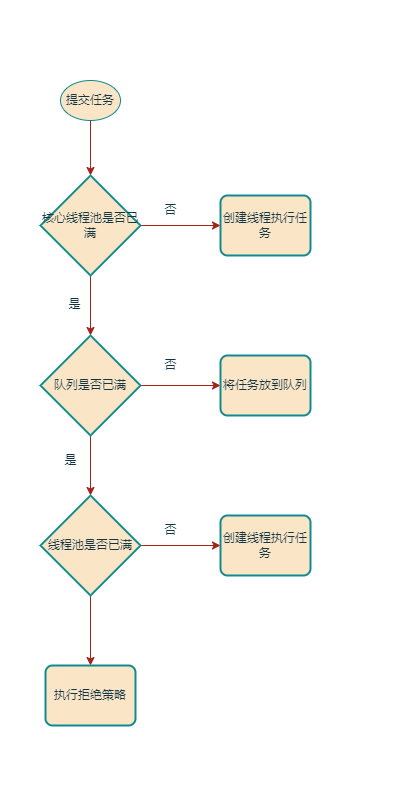
1.2 执行示意图
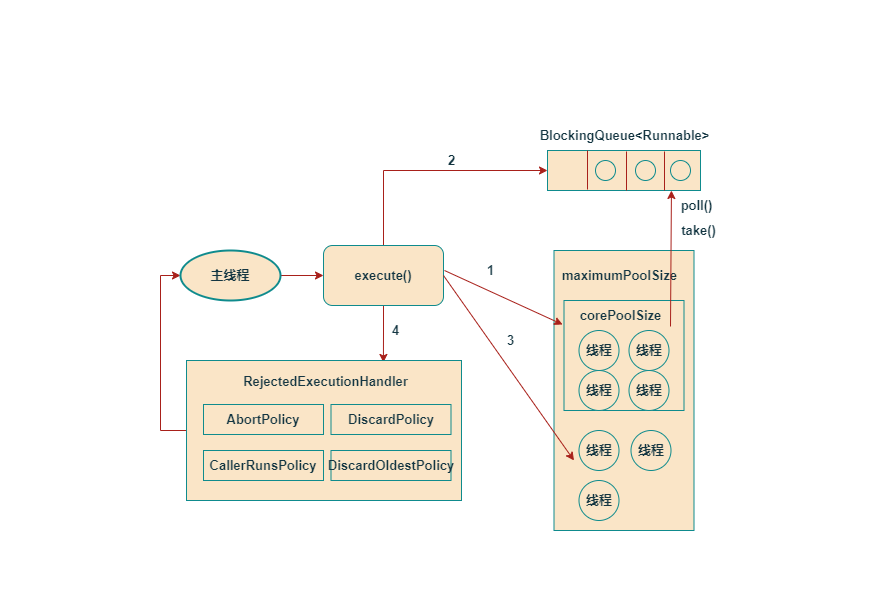
从上图得知
如果当前运行的线程数小于corePoolSize(核心线程数),则会创建新线程作为核心线程来执行任务(注意,执行这一步需要获取全局锁)。
如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue中。
如果无法将任务加入BlockingQueue(队列已满),则将创建线程来执行任务(注意,执行这一步骤需要获取全局锁)。
如果第三步创建线程使得当前线程数大于maximumPoolSize,任务将被拒绝,并调用RejectdExecutionHandler.rejectedExecution()方法。
2. 源码解析
2.1 核心参数
corePoolSize 核心线程数,池中所保存的线程数,包括空闲线程。
maximumPoolSize 线程池最大容量,在核心线程数的基础上可能会额外增加一些非核心线程,需要注意的是只有当workQueue队列填满时才会创建多于corePoolSize的线程(线程池总线程数不超过maxPoolSize)
workQueue 用于保存任务的队列
SynchronousQueue 线性安全、capacity是0不存储任何元素、可以在两个线程中传递同一个对象。synchronousQueue.put(object);synchronousQueue.take();如果不希望任务在队列中等待而是希望将任务直接移交给工作线程,可使用SynchronousQueue作为等待队列。
LinkedBlockingQueue 链式队列,队列容量不足或为0时自动阻塞。锁是分离的,高并发的情况下生产者和消费者可以并行地操作队列中的数据,可以提高吞吐量。当QPS很高,发送数据很大,大量的任务被添加到这个无界LinkedBlockingQueue 中,导致cpu和内存飙升服务器挂掉。
ArrayBlockingQueue 数组实现的有界队列,使用独占锁,生产者和消费者无法并行操作,在高并发场景下会成为性能瓶颈。
PriorityBlockingQueue PriorityBlockingQueue中的优先级由任务的Comparator决定。
keepAliveTime 空闲线程的存活时间 当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize。如果allowCoreThreadTimeout=true,则会直到线程数量=0。
threadFactory 线程工厂 默认DefaultThreadFactory 创建同样分组(ThreadGroup) 同样优先级(NORM_PRIORITY) non-daemon的线程。
handler 拒绝策略处理 默认AbortPolicy 抛异常RejectedExecutionException
AbortPolicy:不执行该任务,并抛出RejectedExecutionException异常。
CallerRunsPolicy:由调用线程处理该任务,如果执行程序已关闭,则会丢弃该任务。
DiscardOldestPolicy:丢弃队列中最老的一个任务,然后重新尝试执行任务(重复此过程。
DiscardPolicy:不执行该任务,也不抛异常。
2.2 线程池状态
2.2.1 线程池状态
成员变量ctl是Integer的原子变量,使用一个变量同时记录线程池状态和线程池中线程个数,假设计算机硬件的Integer类型是32位二进制标示,如下面代码所示,其中高3位用来表示线程池状态,后面29位用来记录线程池线程个数。
//线程个数掩码位数,并不是所有平台int类型是32位,所以准确说是具体平台下Integer的二进制位数-3后的剩余位数才是线程的个数
private static final int COUNT_BITS = Integer.SIZE - 3;
//线程最大个数(低29位)00011111111111111111111111111111
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
//(高3位):11100000000000000000000000000000
private static final int RUNNING = -1 << COUNT_BITS;
//(高3位):00000000000000000000000000000000
private static final int SHUTDOWN = 0 << COUNT_BITS;
//(高3位):00100000000000000000000000000000
private static final int STOP = 1 << COUNT_BITS;
//(高3位):01000000000000000000000000000000
private static final int TIDYING = 2 << COUNT_BITS;
//(高3位):01100000000000000000000000000000
private static final int TERMINATED = 3 << COUNT_BITS;
获取线程池的运行状态和线程池中的线程个数
// 获取高三位 运行状态
private static int runStateOf(int c) { return c & ~CAPACITY; }
//获取低29位 线程个数
private static int workerCountOf(int c) { return c & CAPACITY; }
//计算ctl新值,线程状态 与 线程个数
private static int ctlOf(int rs, int wc) { return rs | wc; }2.2.2 线程池状态含义:
RUNNING:接收新任务并且处理阻塞队列里的任务。
SHUTDOWN:拒绝新任务但是处理阻塞队列里的任务。
STOP:拒绝新任务并且抛弃阻塞队列里的任务,同时中断正在处理的任务。
TIDYING:所有任务都执行完(包含阻塞队列里面任务),当前线程池活动线程为0,将要调用terminated方法。
TERMINATED:终止状态。terminated方法调用完成以后的状态。
2.3 执行方法
2.3.1 线程池中任务提交方法
execute()方法
public void execute(Runnable command) {//(1) 如果任务为null,则抛出NPE异常if (command == null)throw new NullPointerException();//(2)获取当前线程池的状态+线程个数变量的组合值int c = ctl.get();//(3)当前线程池线程个数是否小于corePoolSize,小于则开启新线程运行if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}//(4)如果线程池处于RUNNING状态,则添加任务到阻塞队列if (isRunning(c) && workQueue.offer(command)) {//(4.1)二次检查int recheck = ctl.get();//(4.2)如果当前线程池状态不是RUNNING则从队列删除任务,并执行拒绝策略if (! isRunning(recheck) && remove(command))reject(command);//(4.3)如果当前线程池线程为空,则添加一个线程else if (workerCountOf(recheck) == 0)addWorker(null, false);}//(5)如果队列满了,则新增线程,新增失败则执行拒绝策略else if (!addWorker(command, false))reject(command);
}submit(Runnable task)方法
public Future<?> submit(Runnable task) {// 6 NPE判断if (task == null) throw new NullPointerException();// 7 包装任务为FutureTaskRunnableFuture<Void> ftask = newTaskFor(task, null);// 8 投递到线程池执行execute(ftask);// 9 返回ftaskreturn ftask;
}protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {return new FutureTask<T>(runnable, value);
}public FutureTask(Runnable runnable, V result) {//将runnable适配为Callable类型任务,并且让result作为执行结果this.callable = Executors.callable(runnable, result);this.state = NEW; // ensure visibility of callable
}submit(Runnable task,T result)方法
public <T> Future<T> submit(Callable<T> task) {if (task == null) throw new NullPointerException();RunnableFuture<T> ftask = newTaskFor(task);execute(ftask);return ftask;
}protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {return new FutureTask<T>(callable);
}2.3.2 线程池中任务执行方法
当用户线程提交任务到线程池后,在线程池没有执行拒绝策略的情况下,用户线 程会马上返回,而提交的任务要么直接切换到线程池中的Worker线程来执行,要么先放入线程池的阻塞队列里面,稍后再由Worker线程来执行。
Worker(Runnable firstTask) {// 在调用runWorker前禁止中断 避免当前Worker在调用runWorker方法前被中断(当其他线程调用了线程池的shutdownNow时,如果Worker状态≥0则会中断该线程)。status=0标示锁未被获取的状态,state=1标示锁已经被获取的状态,state=–1是创建Worker时默认的状态。setState(-1);this.firstTask = firstTask;//使用线程池中指定的线程池工厂创建一个线程作为该Worker对象的执行线程this.thread = getThreadFactory().newThread(this);
}public void run() {runWorker(this);//委托给runWorker方法
}final void runWorker(Worker w) {Thread wt = Thread.currentThread();Runnable task = w.firstTask;w.firstTask = null;//(1)status设置为0,允许中断。这时候调用shutdownNow会中断Worker线程。w.unlock();boolean completedAbruptly = true;try {//(2)当前task==null或者调用getTask从任务队列获取的任务返回nullwhile (task != null || (task = getTask()) != null) {//(2.1)获取工作线程内部持有的独占锁w.lock();...try {//(2.2)任务执行前干一些事情beforeExecute(wt, task);Throwable thrown = null;try {//(2.3)执行任务task.run();} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {thrown = x; throw new Error(x);} finally {//(2.4)任务执行完毕后干一些事情afterExecute(task, thrown);}} finally {task = null;//(2.5)统计当前Worker完成了多少个任务w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {//(3)执行清工作processWorkerExit(w, completedAbruptly);}
}private void processWorkerExit(Worker w, boolean completedAbruptly) {...//(3.1)统计整个线程池完成的任务个数,并从工作集里面删除当前woker 加全局锁final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {completedTaskCount += w.completedTasks;workers.remove(w);} finally {mainLock.unlock();}//(3.2)如果当前线程池状态是shutdown状态并且工作队列为空,或者当前是stop状态并且当前线程池里面没有活动线程,则设置线程池状态为TERMINATED。tryTerminate();//(3.3)判断当前线程中的线程个数是否小于核心线程个数,如果是则新增一个线程。int c = ctl.get();if (runStateLessThan(c, STOP)) {if (!completedAbruptly) {int min = allowCoreThreadTimeOut ? 0 : corePoolSize;if (min == 0 && ! workQueue.isEmpty())min = 1;if (workerCountOf(c) >= min)return; // replacement not needed}addWorker(null, false);}
}2.3.3 线程池关闭方法
shutdown()方法
调用 shutdown后,线程池就不会再接收新的任务,但是工作队列里面的任务还是要执行的,该方法是立刻返回的,并不同步等待队列任务完成再返回。
首先使用CAS设置当前线程池状态为TIDYING,如果成功则执行扩展接口terminated在线程池状态变为TERMINATED前做一些事情,然后设置当前 线程池状态为TERMINATED,最后调用termination.signalAll()来激活调用线程池的 awaitTermination系列方法被阻塞的所有线程。
public void shutdown() {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {//(1)权限检查如果设置了安全管理器,则看当前调用shutdown命令的线程是否有关闭线程的权限,如果有权限则还要看调用线程是否有中断工作线程的权限,如果没有权限则抛出SecurityException或者NullPointerException异常。checkShutdownAccess();//(2)设置当前线程池状态为SHUTDOWN,如果已经是SHUTDOWN则直接返回advanceRunState(SHUTDOWN);//(3)设置中断标志。这里首先加了全局锁,同时只有一个线程可以调用shutdown设置中断标志。然后尝试获取Worker本身的锁,获取成功则设置中断标识,由于正在执行的任务已经获取了锁,所以正在执行的任务没有被中断。这里中断的是阻塞到getTask()方法,企图从队列里获取任务的线程,也就是空闲线程。interruptIdleWorkers();onShutdown();} finally {mainLock.unlock();}//(4)尝试状态变为TERMINATEDtryTerminate();
}private void advanceRunState(int targetState) {for (;;) {int c = ctl.get();if (runStateAtLeast(c, targetState) ||ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))))break;}
}private void interruptIdleWorkers(boolean onlyOne) {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {for (Worker w : workers) {Thread t = w.thread;//如果工作线程没有被中断,并且没有正在运行则设置中断if (!t.isInterrupted() && w.tryLock()) {try {t.interrupt();} catch (SecurityException ignore) {} finally {w.unlock();}}if (onlyOne)break;}} finally {mainLock.unlock();}
}final void tryTerminate() {for (;;) {
...int c = ctl.get();
...final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {//设置当前线程池状态为TIDYINGif (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {try {terminated();} finally {//设置当前线程池状态为TERMINATEDctl.set(ctlOf(TERMINATED, 0));//激活调用条件变量termination的await系列方法被阻塞的所有线程termination.signalAll();}return;}} finally {mainLock.unlock();}}
}
shutdownNow()方法
调用 shutdownnow后,线程池就不会再接收新的任务,并且会丢弃工作队列里面的任务,正在执行的任务也会被中断,该方法是立刻返回的,并不同步等待激活的任务执行完成再返回。
调用线程池队列的drainTo方法把队列中的任务移除到taskList 里,如果发现线程池队列还不为空(比如DelayQueue或者其他类型的队列drainTo可能 移除元素失败),则循环移除里面的元素,最后返回移除的任务列表。
public List<Runnable> shutdownNow() {List<Runnable> tasks;final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {//(5)权限检查checkShutdownAccess();//(6) 设置线程池状态为stopadvanceRunState(STOP);//(7)中断所有线程,这里需要注意的是中断所有线程,包含空闲线程和正在执行任务的线程interruptWorkers();//(8)移动队列任务到taskstasks = drainQueue();} finally {mainLock.unlock();}//(9)终止状态tryTerminate();return tasks;
}private void interruptWorkers() {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {for (Worker w : workers)w.interruptIfStarted();} finally {mainLock.unlock();}
}private List<Runnable> drainQueue() {//8.1获取任务队列BlockingQueue<Runnable> q = workQueue;ArrayList<Runnable> taskList = new ArrayList<Runnable>();//8.2 从任务队列移除任务到taskList列表q.drainTo(taskList);//8.3 如果q还不为空,则说明drainTo接口调用失效,则循环移除if (!q.isEmpty()) {for (Runnable r : q.toArray(new Runnable[0])) {if (q.remove(r))taskList.add(r);}}//8.4返回异常的任务列表return taskList;
}2.4 参数优化
2.4.1 默认值
corePoolSize = 1
maxPoolSize = Integer.MAX_VALUE
queueCapacity = Integer.MAX_VALUE
keepAliveTime = 60s
allowCoreThreadTimeout = false
rejectedExecutionHandler = AbortPolicy()需要根据几个值来决定
tasks :每秒的任务数,假设为500~1000
taskcost:每个任务花费时间,假设为0.1s
responsetime:系统允许容忍的最大响应时间,假设为1s
corePoolSize
corePoolSize = 每秒需要多少个线程处理?
threadcount = tasks/(1/taskcost) = taskstaskcout = (500 ~ 1000)0.1 = 50~100 个线程。
corePoolSize设置应该大于50。根据8020原则,如果80%的每秒任务数小于800,那么corePoolSize设置为80。
queueCapacity
队列容量 queueCapacity = (coreSizePool/taskcost)*responsetime
切记不能设置为Integer.MAX_VALUE,这样队列会很大,线程数只会保持在corePoolSize大小,当任务陡增时,
不能新开线程来执行,响应时间会随之陡增。
maxPoolSize
最大线程数在生产环境上我们往往设置成corePoolSize一样,这样可以减少在处理过程中创建线程的开销。
rejectedExecutionHandler:根据具体情况来决定,任务不重要可丢弃,任务重要则要利用一些缓冲机制来处理。
keepAliveTime和allowCoreThreadTimeout采用默认通常能满足。
2.4.2 参考值
@Configuration
public class ConcurrentThreadGlobalConfig {@Beanpublic ThreadPoolTaskExecutor defaultThreadPool() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();//核心线程数目executor.setCorePoolSize(65);//指定最大线程数executor.setMaxPoolSize(65);//队列中最大的数目executor.setQueueCapacity(650);//线程名称前缀executor.setThreadNamePrefix("DefaultThreadPool_");//rejection-policy:当pool已经达到max size的时候,如何处理新任务//CALLER_RUNS:不在新线程中执行任务,而是由调用者所在的线程来执行//对拒绝task的处理策略executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());//线程空闲后的最大存活时间executor.setKeepAliveSeconds(60);//加载executor.initialize();return executor;}
}以上