网站建设一个月多少钱网站建设和维护pdf
乳房X线摄影(MG)在乳腺癌的早期发现中起着重要作用。MG可以在早期阶段发现乳腺癌,即使是感觉不到肿块的小肿瘤。基于卷积神经网络(CNN)的DL最近吸引了MG的大量关注,因为它有助于克服CAD系统的限制(假阳性、不必要的辐射暴露、无意义的活组织检查、高回调率、更高的医疗费用和更多的检查次数)。
当其应用在整个乳房X光图像时,由于在不同特征级别的多重卷积,CNN的计算代价很高。首先聚焦于图像的特定区域,而不是整个图像,逐渐为整个图像建立特征。
CNN缺乏在没有增强的情况下处理旋转和比例不变性的能力,并且无法对相对空间信息进行编码。
为解决此类问题,使用基于块的乳房图像分类器,而其中使用潜在的感兴趣区域(ROI)而不是整个乳房图像,这种方法有一定的局限性。基于CNN深度学习模型用于乳房X光摄影乳腺癌检测的第一个挑战是肿瘤定位。
大多数基于CNN的深度学习模型使用基于块的方法:
①裁剪乳房X光照片上的可疑肿瘤区域并将其送入模型。这会导致整个乳房X光检查的信息丢失,导致出现假阳性结果
②同时其性能根据图像中病变的大小而不同
③CNN需要相当大的预处理来处理糟糕的图像质量。由于能见度降低、对比度低、清晰度差和噪音,相当大比例的异常被误诊或忽视
④CNN对于不平衡的数据集的性能很差,训练数据集中正类和负类之间的不平等被称为数据集不平衡。直接在不平衡的数据集上训练CNN模型可能会使预测偏向于具有更多观测数量的类别。
弥补图像数据集不足的方法
数据增强和迁移学习
数据增强使得能够使用原始图像创建重新排列的图像数据,从而增加训练图像数据集的数量和种类。它包括噪波添加、旋转、平移、对比度、饱和度、色彩增强、亮度、缩放和裁剪等操作。
迁移学习利用来自所选数据集的预先训练的权重作为在另一数据集上训练的起点。这使得能够从先前任务中学到的知识用于目标任务。几乎所有基于CNN的用于乳房X光摄影的DL方法都使用迁移学习方法来弥补大型数据集的不足,并利用具有先验特征知识的优化模型来执行新任务。
基于Vision Transformer的迁移学习
- 图像数据平衡模块,用于解决乳房X光数据集中的类不平衡问题
- 设计了一种基于视觉变换的乳房X光片分类迁移学习方法。利用Transformer的自我注意力方法,改进了基于CNN的迁移学习方法的缺点
- 源图像被分成称为视觉标记的图像块的集合。
- 视觉标记被合并到固定维度编码向量的集合中。实质上与负责处理文本输入的网络相同的Transformer编码器网络与编码后的矢量一起被馈送图像中的块的位置。
- VIT编码器由多个模块组成,每个模块都有三个主要处理部件:层归一化、多头注意力网络(MSP)和多层感知器(MLP)。
该模型通过层归一化对训练图像的差异性进行调整,使训练过程保持在正轨上。多头注意力网络从提供的嵌入式视觉token创建attention map,其帮助网络将注意力集中在图像最关键的区域。
多视图Transformer
使用多视图Transformer模型(MVT)来检测乳房X光照片上的乳腺癌。MVT由两个主要部分组成:局部和全局Transformer。局部Transformer分析来自每个视图图像的数据。相比之下,全局Transformer结合来自四-视图乳房X光照片的数据。
自注意力机制、多头自注意力和多层感知器是局部和全局Transformer的三个主要组成部分。
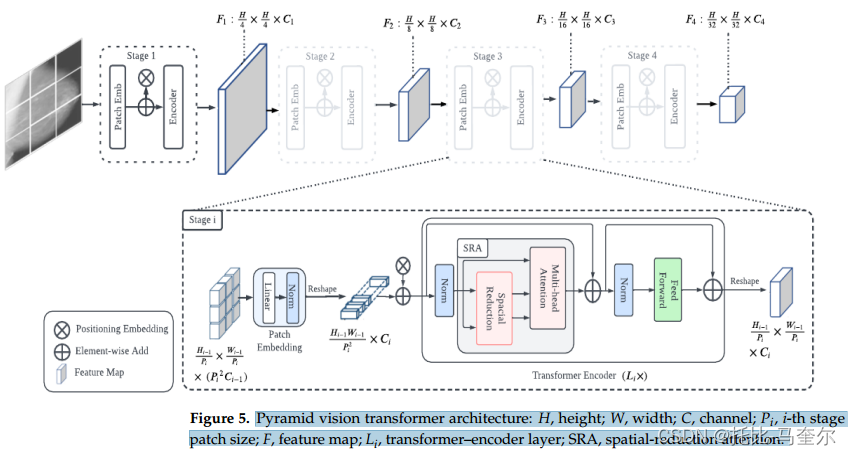
乳房X光照片的像素大小差异很大;我们将所有图像的大小调整为224*224像素,从输入图像到生成补丁的首选大小。
Vision Transformer架构
视觉转换器模型将图像分割成更小的二维块,并将这些块作为单词标记输入,如原始NLP转换器模型所执行的那样。高度H、宽度W和通道数C的输入图像被分成较小的二维块,以类似于输入在NLP域中的结构的方式排列输入图像数据。
产生
个像素大小为
的块。每个块被展平为
的向量
,
使用可训练的线性投影E将展平的块映射到D维度,产生一系列嵌入的图像块,
嵌入的图像块序列以嵌入
的可学习类为前缀,
最后将在训练过程中学习到的一维位置嵌入Epos添加到块嵌入中,从而向输入中添加定位信息。
我们将反馈到Transformer-encoder网络结构中,该网络是由L个相同的层堆叠而成,从而进行分类。在编码器输出的第 L 层向分类前馈
的值。在预训练过程中,采用单隐藏层MLP(多层感知机)实现分类;在精调过程中,采用单线性层实现分类;MLP实现 GELU 非线性进行分类。
总体而言,视觉转换器使用了原始NLP转换器架构的编码器组件。编码器接收大小为16×16的嵌入图像块序列作为输入,连同位置数据,以及挂起到该序列的可学习类嵌入。补丁越小,性能就越高,计算成本也就越高。
Swin Transformer架构
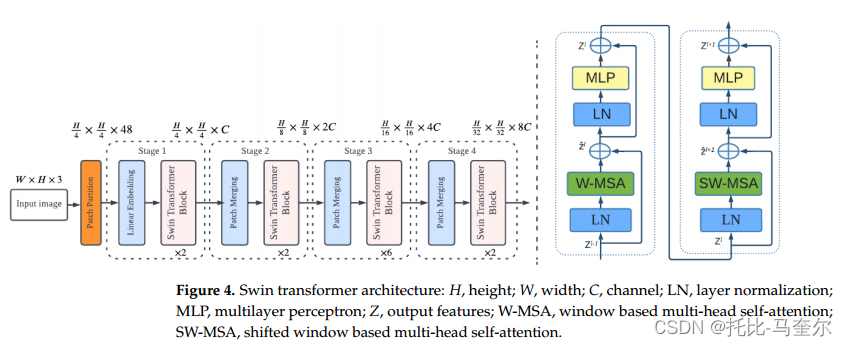
金字塔 vision Transformer(PVT)
PVT使用一种被称为空间减少注意(SRA)的自我注意类型,其特征是键和值的空间减少,以获得注意机制的二次方复杂性。SRA逐渐降低了整个模型中特征的空间维度。此外,它还将位置嵌入应用于所有变压器块,强化了顺序的思想。