建设数据库搜索网站婚恋网站建设方案
C语言函数大全
本篇介绍C语言函数大全-- w 开头的函数
1. wcstok
1.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
wchar_t *wcstok(wchar_t *wcs, const wchar_t *delim, wchar_t **ptr); | 用于将一个长字符串拆分成几个短字符串(标记),并返回第一个标记的地址 |
wchar_t *wcstok(wchar_t *wcs, const wchar_t *delim); | 用于将一个长字符串拆分成几个短字符串(标记),并返回第一个标记的地址 |

参数:
- wcs : 被分割的字符串
- delim : 分割符字符串,包含多个字符
- ptr : 指向保存上次调用后的指针的指针,首次调用时需赋值为
NULL
1.2 演示示例
windows 下两个参数的示例:
#include <wchar.h>
#include <stdio.h>int main() {wchar_t str[] = L"Hello, huazie! This is wcstok demo.";wchar_t* token;// 第一次调用token = wcstok(str, L" ,.!?");while (token != NULL) {wprintf(L"%ls\n", token);token = wcstok(NULL, L" ,.!?");}return 0;
}
1.3 运行结果

2. wcstol
2.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
long int wcstol(const wchar_t* str, wchar_t** endptr, int base); | 用于将字符串转换为长整型数字的函数 |
参数:
- str : 要转换的字符串
- endptr : 可选输出参数,指向第一个不能转换成数字字符的字符的指针
- base : 数字基数,介于
2和36之间;
当base参数为0时,wcstol()函数会自动检测数字基数:
- 如果输入字符串以
"0x"或"0X"开头,则将基数设置为16。- 如果输入字符串以
"0"开头,则将基数设置为8。- 如果不是这些情况,则将基数设置为
10。
2.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>int main()
{//const wchar_t* str = L"123456";//const wchar_t* str = L"123a456";//const wchar_t* str = L"a123456";const wchar_t* str = L"0xFF";wchar_t* endptr;long int num;//num = wcstol(str, &endptr, 10);num = wcstol(str, &endptr, 0);if (endptr == str)printf("Invalid input.\n");elseprintf("The number is %ld\n", num);return 0;
}
注意: 如果输入字符串无法转换为数字,则
wcstol()函数返回0,并将endptr指向输入字符串的起始位置。所以,在使用wcstol()函数时,建议检查endptr和str是否相同,以确定输入是否有效。
2.3 运行结果




3. wcstoul
3.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
unsigned long int wcstoul(const wchar_t* str, wchar_t** endptr, int base); | 用于将字符串转换为无符号长整型数字 |
参数:
- str : 要转换的字符串
- endptr : 可选输出参数,指向第一个不能转换成数字字符的字符的指针
- base : 数字基数,介于
2和36之间;
当base参数为0时,wcstol()函数会自动检测数字基数:
- 如果输入字符串以
"0x"或"0X"开头,则将基数设置为16。- 如果输入字符串以
"0"开头,则将基数设置为8。- 如果不是这些情况,则将基数设置为
10。
3.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>int main()
{const wchar_t* str = L"123a456";wchar_t* endptr;unsigned long int num;num = wcstoul(str, &endptr, 10);if (endptr == str)printf("Invalid input.\n");elseprintf("The number is %lu\n", num);return 0;
}
wcstoul() 函数的用法和 wcstol() 函数类似,这里就不一一列举了
3.3 运行结果

4. wcsxfrm
4.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
size_t wcsxfrm(wchar_t* dest, const wchar_t* src, size_t n); | 将一个 Unicode 字符串转换为一个 “可排序” 的字符串。该新字符串中的字符序列反映了源字符串中的字符顺序和大小写信息,以便进行字典序比较。 |
参数:
- dest : 存储转换后字符串的目标缓冲区
- src: 要转换的源字符串
- n : 目标缓冲区的最大长度
4.2 演示示例
#include <stdlib.h>
#include <stdio.h>
#include <wchar.h>#define ARRAY_SIZE 5int main()
{const wchar_t* arr[ARRAY_SIZE] = { L"Tom", L"Alice", L"Huazie", L"David", L"Charlie" };wchar_t sorted_arr[ARRAY_SIZE][50];size_t i;for (i = 0; i < ARRAY_SIZE; i++) {wcsxfrm(sorted_arr[i], arr[i], sizeof(sorted_arr[i]));}// 使用 qsort 对字符串数组排序qsort(sorted_arr, ARRAY_SIZE, sizeof(sorted_arr[0]), wcscmp);// 排序后输出wprintf(L"Sorted array:\n");for (i = 0; i < ARRAY_SIZE; i++) {wprintf(L"%ls\n", sorted_arr[i]);}return 0;
}
在上面的示例代码中,
- 首先,我们定义一个包含
5个Unicode字符串的字符串数组arr,每个字符串代表一个人名; - 然后,定义一个大小为
5x50的二维字符数组sorted_arr,用于存储排序后的字符串; - 接着,使用
wcsxfrm()函数将每个Unicode字符串转换为可排序字符串,并将结果存储在sorted_arr数组中; - 再然后,使用
qsort()函数按字典序对sorted_arr数组中的字符串进行排序; - 再接着,使用
wprintf()函数输出排序后的字符串; - 最后结束程序。
4.3 运行结果

5. wctype
5.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
wctype_t wctype(const char* property); | 用于确定给定的宽字符类别 |
参数:
- property : 一个指向表示宽字符属性名称的字符串字面量的指针
常见的宽字符属性及含义如下:
| 属性名称 | 含义 |
|---|---|
"alnum" | 字母数字字符 |
"alpha" | 字母字符 |
"blank" | 空格或水平制表符字符 |
"cntrl" | 控制字符 |
"digit" | 数字字符 |
"graph" | 可打印字符(除空格字符外) |
"lower" | 小写字母字符 |
"print" | 可打印字符 |
"punct" | 标点符号字符 |
"space" | 空白字符 |
"upper" | 大写字母字符 |
"xdigit" | 十六进制数字字符 |
返回值:
- 如果指定的属性存在,则返回相应的宽字符类型;
- 如果指定的属性不存在,则返回零。
5.2 演示示例
#include <stdio.h>
#include <wchar.h>
#include <wctype.h>int main()
{wchar_t ch = L',';wctype_t punct_wt;// 获取标点符号字符类型punct_wt = wctype("punct");// 判断指定的宽字符是否为标点符号if (iswctype(ch, punct_wt)) {wprintf(L"%lc is a punctuation character.\n", ch);} else {wprintf(L"%lc is not a punctuation character.\n", ch);}return 0;
}
注意: 在调用
wctype()函数时,应该传递一个有效的宽字符属性名称作为参数,详见 5.1 的表格所示。
5.3 运行结果

6. wctob
6.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int wctob(wint_t wc); | 用于将给定的宽字符转换为其对应的字节表示 |
参数:
- wc : 一个宽字符值
返回值:
- 如果能转换成功,则返回返回与之对应的字节表示;
- 如果无法将给定宽字符转换为字节表示,则返回
EOF。
6.2 演示示例
#include <stdio.h>
#include <wchar.h>int main()
{wchar_t ch = L'?';int byte;// 将 Unicode 字符转换为字节表示byte = wctob(ch);// 输出字节值printf("Byte value of %lc: %d (0x%02X)\n", ch, byte, byte);return 0;
}
注意: 在使用
wctob()函数时,应该确保系统当前的本地化环境和编码方式与程序中使用的字符编码一致。如果字符编码不一致,可能会导致错误的结果或未定义行为。
6.3 运行结果

7. wctomb
7.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int wctomb(char* s, wchar_t wc); | 用于将给定的宽字符转换为其对应的多字节字符表示 |
参数:
- s : 一个指向字符数组的指针
- wc : 一个宽字符值
返回值:
- 如果能转换成功,则将
wc转换为其对应的多字节字符表示,存储在s指向的字符数组中;- 如果
s是空指针,则不执行任何操作,只返回转换所需的字符数;- 如果无法将给定宽字符转换为多字节字符表示,则返回
-1
7.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>int main()
{wchar_t ch = L'?';char mb[MB_CUR_MAX];int len;// 将 Unicode 字符转换为多字节字符表示len = wctomb(mb, ch);// 输出转换结果if (len >= 0) {printf("Multibyte representation of %lc: ", ch);for (int i = 0; i < len; i++) {printf("%02X ", (unsigned char) mb[i]);}printf("\n");} else {printf("Failed to convert %lc to multibyte character.\n", ch);}return 0;
}
在上面的示例程序中,wctomb() 函数被用来将 Unicode 字符 ',' 转换为其对应的多字节字符表示,并将结果保存在字符数组 mb 中。然后,程序输出每个字节的十六进制值。
注意: 在使用
wctomb()函数时,应该根据当前的本地化环境和编码方式调整字符数组的大小。可以使用MB_CUR_MAX宏来获取当前编码方式下一个多字节字符所需的最大字节数,从而确定字符数组的大小。
7.3 运行结果

8. wmemchr
8.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
void* wmemchr(const void* s, wchar_t c, size_t n); | 用于在宽字符数组中查找给定的宽字符 |
参数:
- s : 一个指向宽字符数组的指针
- c : 要查找的宽字符值
- n : 要搜索的字节数
返回值:
- 如果找到了
c,则返回指向该位置的指针;- 否则返回空指针。
8.2 演示示例
#include <stdio.h>
#include <wchar.h>int main()
{const wchar_t str[] = L"Hello, Huazie!";const wchar_t ch = L'u';wchar_t* pch;// 在宽字符数组中查找给定的宽字符// 使用 wcslen() 函数来获取 str 的长度,以指定要搜索的字节数 npch = wmemchr(str, ch, wcslen(str));// 根据 pch,来判断是否找到,并输出结果if (pch)wprintf(L"Found '%lc' at position %d.\n", ch, (int)(pch - str));elsewprintf(L"Could not find '%lc'.\n", ch);return 0;
}
8.3 运行结果

9. wmemcmp
9.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int wmemcmp(const wchar_t* s1, const wchar_t* s2, size_t n); | 用于比较两个宽字符数组的前 n 个宽字符 |
参数:
- s1 : 待比较的宽字符串1
- s2 : 待比较的宽字符串2
- n : 要比较的字节数
返回值:
- 如果两个数组相等,则返回零;
- 如果
s1比s2小,则返回负数;- 如果
s1比s2大,则返回正数。
9.2 演示示例
#include <stdio.h>
#include <wchar.h>int main()
{const wchar_t str1[] = L"Hello";const wchar_t str2[] = L"Huazie";int result;// 比较两个宽字符数组result = wmemcmp(str1, str2, wcslen(str1));// 根据result,来判断,并输出结果if (result == 0)wprintf(L"%ls and %ls are equal.\n", str1, str2);else if (result < 0)wprintf(L"%ls is less than %ls.\n", str1, str2);elsewprintf(L"%ls is greater than %ls.\n", str1, str2);return 0;
}
9.3 运行结果

10. wmemcpy
10.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
wchar_t* wmemcpy(wchar_t* dest, const wchar_t* src, size_t n); | 用于将一个宽字符数组的前 n 个宽字符复制到另一个宽字符数组 |
参数:
- dest : 目标宽字符串
- src : 源宽字符串
- n : 要复制的字节数
10.2 演示示例
#include <stdio.h>
#include <wchar.h>
#include <string.h>int main()
{const wchar_t src[] = L"Hello, Huazie!";wchar_t dest[20];// 将一个宽字符数组复制到另一个宽字符数组wmemcpy(dest, src, wcslen(src) + 1);// 输出结果wprintf(L"Source string: %ls\n", src);wprintf(L"Destination string: %ls\n", dest);return 0;
}
注意: 在使用
wmemcpy()函数时,应该确保目标数组有足够的空间来存储源数组的内容,以免发生缓冲区溢出。在上面的示例中,我们使用wcslen()函数来获取源数组的长度,然后加上1,以包括字符串结尾的空字符 '\0'。
10.3 运行结果

11. wmemset
11.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
wchar_t* wmemset(wchar_t* s, wchar_t c, size_t n); | 用于将一个宽字符数组的前 n 个宽字符设置为给定的宽字符值 |
参数:
- s : 一个指向宽字符数组的指针
- c : 要设置的宽字符值
- n : 要设置的字节数
11.2 演示示例
#include <stdio.h>
#include <wchar.h>
#include <string.h>int main()
{wchar_t str[20]= L"Hello Huazie!";// 修改前wprintf(L"Before: %ls\n", str);// 将一个宽字符数组的所有元素设置为给定的宽字符值Xwmemset(str, L'X', wcslen(str));// 修改后wprintf(L"After : %ls\n", str);return 0;
}
在上面的示例程序中,
- 首先,我们定义一个宽字符数组 str,并初始化为
"Hello Huazie!"; - 接着,调用
wprintf()函数输出修改之前的宽字符数组str; - 然后,调用
wmemset()函数将宽字符数组str的所有元素都设置为‘X’; - 最后,再调用
wprintf()函数输出修改之后的宽字符数组str,并结束程序。
11.3 运行结果

12. wprintf
12.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int wprintf(const wchar_t* format, ...); | 用于格式化输出宽字符字符串 |
参数:
- format : 一个宽字符格式化字符串
- … : 可选参数
12.2 演示示例
#include <stdio.h>
#include <wchar.h>int main()
{wchar_t name[] = L"Huazie";int age = 25;double height = 1.75;// 输出格式化的宽字符字符串wprintf(L"%ls %d %.2f\n", name, age, height);return 0;
}
12.3 运行结果

13. write
13.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
ssize_t write(int fd, const void* buf, size_t count); | 用于将数据写入文件描述符 |
参数:
- fd : 要写入的文件描述符
- buf: 写入数据的缓冲区
- count: 写入的字节数
返回值:
- 如果写入成功,则返回实际写入的字节数;
- 如果出现错误,则返回
-1。
13.2 演示示例
#include <stdio.h>
#include <unistd.h>int main()
{const char msg[] = "Hello, Huazie!\n";int nbytes;// 向标准输出流写入数据nbytes = write(STDOUT_FILENO, msg, sizeof(msg) - 1);// 输出结果if (nbytes == -1) {perror("write");return 1;}return 0;
}
注意: 在使用
write()函数时,应该确保给定的文件描述符是有效的,并且缓冲区中有足够的数据可供写入,以免发生未定义的行为
13.3 运行结果

14. wscanf
14.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int wscanf(const wchar_t* format, ...); | 用于从标准输入流(stdin)读取格式化的宽字符输入 |
参数:
- format : 一个宽字符格式化字符串
- … : 可选参数
14.2 演示示例
#include <stdio.h>
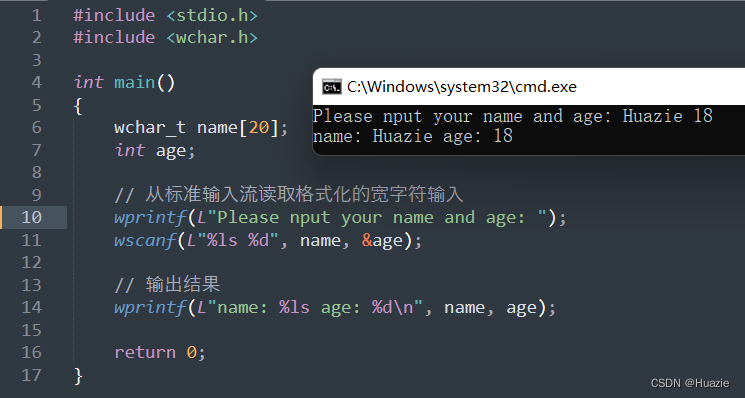
#include <wchar.h>int main()
{wchar_t name[20];int age;// 从标准输入流读取格式化的宽字符输入wprintf(L"Please nput your name and age: ");wscanf(L"%ls %d", name, &age);// 输出结果wprintf(L"name: %ls age: %d\n", name, age);return 0;
}
14.3 运行结果