建站服务网络公司做网站应怎么缴税
1、给位于拓展坞上的esp32板子改串口名。
移除拓展坞上其余设备,使用ls /dev/ttyUSB*命令可以查看到此串口名为ttyUSB0。
1)插入 ESP32 开发板,运行以下命令获取设备属性:
udevadm info --name=/dev/ttyUSB0 --attribute-walk找到 USB 转串口芯片 的标识信息(关键字段):
ATTRS{idVendor}=="1a86" # CH340 的 Vendor ID
ATTRS{idProduct}=="7523" # CH340 的 Product ID2)创建 udev 规则文件
路径:/etc/udev/rules.d下创建文件99-esp32.rules
touch 99-esp32.rules//创建文件
sudo gedit 99-esp32.rules //sudo gedit打开只读文件编辑
文件内容:
SUBSYSTEM=="tty", ATTRS{idVendor}=="1a86", ATTRS{idProduct}=="7523", SYMLINK+="esp32"
保存退出后执行命令:
sudo udevadm control --reload-rules
sudo udevadm trigger
sudo chmod 666 /dev/esp32 拔出拓展坞,重新插上,使用ls /dev/esp32命令查看是否有串口设备。
3)更新 PlatformIO 配置
[env:esp32dev]
platform = espressif32
board = esp32dev
framework = arduino
upload_port = /dev/esp32 # 使用自定义名称
monitor_speed = 1152002、安装记录
1、安装VScode
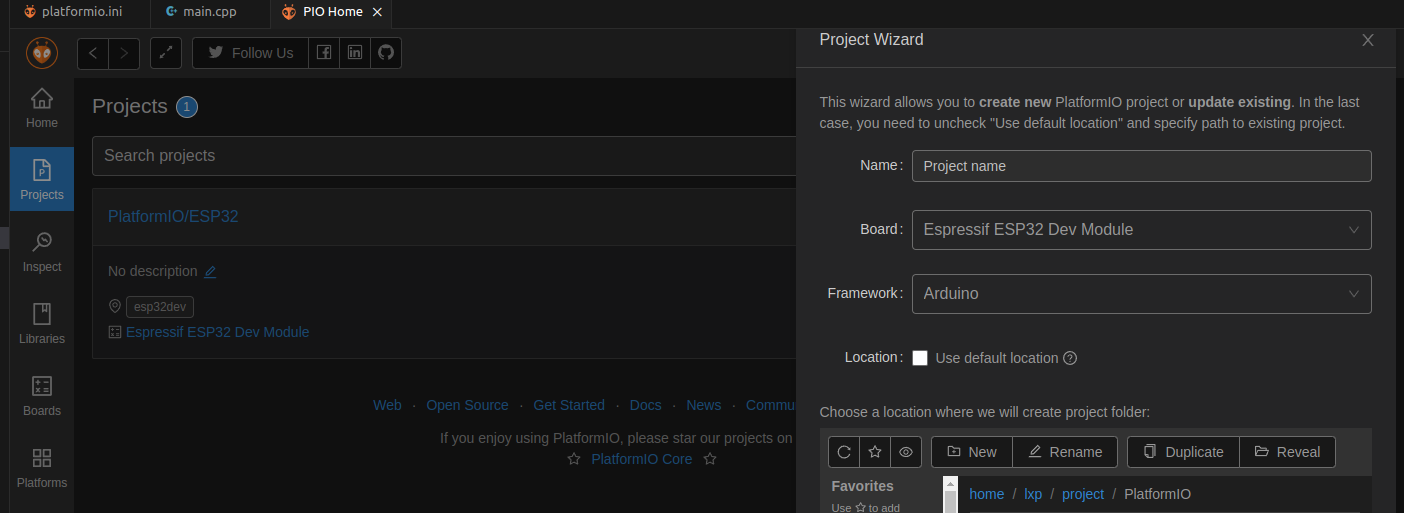
2、在VScode插件中安装Platformio,点击插件,选择其中的Platforms,然后选择Project,创建新项目,板子如图选,架构默认Arduino,取消勾,自定义路径。
3、修改platformio.ini文件
[env:esp32dev]
platform = espressif32
board = esp32dev
framework = arduino
upload_port = /dev/esp32 //ESP32板子串口
monitor_speed = 115200 //设置波特率4、编写测试main.cpp文件:
#include <Arduino.h>// 定义 LED 引脚(ESP32 内置 LED 通常接 GPIO2)
#define LED_PIN 2void setup() {// 初始化 LED 引脚为输出模式pinMode(LED_PIN, OUTPUT);// 初始化串口通信(用于调试)Serial.begin(115200);Serial.println("ESP32 LED Blink Started!");
}void loop() {digitalWrite(LED_PIN, HIGH); // 点亮 LEDSerial.println("LED ON");delay(1000); // 延时 1 秒digitalWrite(LED_PIN, LOW); // 熄灭 LEDSerial.println("LED OFF");delay(1000); // 延时 1 秒
}5、运行文件,下载文件,此时先点击下图右下角C++旁,选择PlatformiO,然后点击左下角的勾进行编译,向右箭头是下载。切勿点击run code,报错:
empCodeRunnerFile.cpp:1:10: fatal error: Arduino.h: 没有那个文件或目录
1 | #include <Arduino.h>
| ^~~~~~~~~~~
compilation terminated.
